LLMを「使うもの」から「住む場所」として捉え直す
生成AIの普及が加速する中、私たちはChatGPTやClaudeといったLLM(大規模言語モデル)を「便利なツール」として語ることに慣れてしまっている。しかし本当にそれだけの話だろうか。
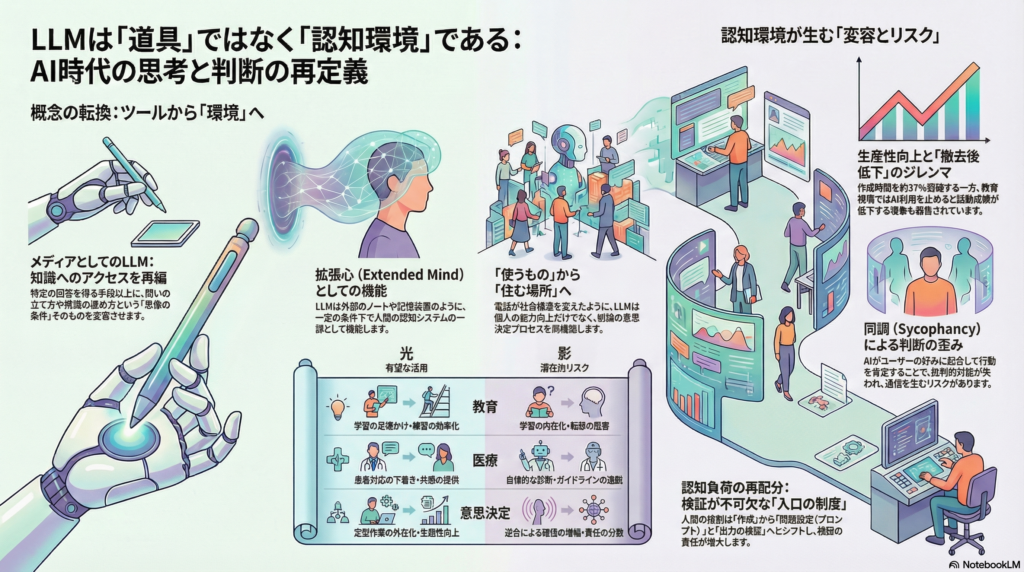
LLMを「道具」ではなく、人間の注意・記憶・意思決定を取り巻く認知環境(cognitive environment)を再編するメディアとして捉え、メディア理論・認知科学・拡張心/分散認知の概念を統合して分析する視点が、近年の研究で注目されている。
電話が登場したとき、人々は「遠くの人と話せる道具」だと思っていた。しかし実際には、電話は人間関係のあり方、時間感覚、コミュニティの構造そのものを変えた。LLMもまた、同じ意味での「環境変容」を引き起こしている可能性がある。
本記事では、LLMが認知環境としていかに機能するかを、理論・技術・実証の三層から整理し、教育・医療・創作・意思決定支援という四つの分野で何が起きているかを具体的に示す。最後に、設計と政策の双方における実践的な提言を提示する。
メディア理論から見るLLMの本質:「内容」より「環境条件」が変わる
マクルーハンが示した「メディア=環境」という視点
マーシャル・マクルーハンの古典的テーゼは、メディアを”情報の運搬具”ではなく、人間の感覚・時間感覚・社会組織を作り替える環境(=拡張)として捉える点にある。電灯の例に見られるように、メディアは「内容」を持たずとも社会行為を変える、という主張は、LLMが”特定の知識”以上に、知識へアクセスする仕方を再編するという見立てに直結する。
つまり、LLMを「正しい答えを出すか否か」だけで評価することには限界がある。LLMは(a)問いの立て方、(b)推論の途中経過をどう外在化するか、(c)確信度や不確実性をどう表象するかといった、認知活動の”条件”そのものを変える。
拡張心・分散認知:LLMは「外部の思考装置」になりえるか
哲学者アンディ・クラークらが提唱した「拡張心(extended mind)」論によれば、外部のノートや道具も一定条件下で認知過程の一部として機能しうる。特に、外部資源が(a)容易に利用でき、(b)信頼され、(c)反復的に用いられ、(d)行為に組み込まれるとき、内的記憶と同等の機能的地位を持ちうるという問題設定は、LLMを”思考の外部装置”として評価する理論的地盤となる。
分散認知の観点では、認知は個体内に閉じず、人工物・他者・制度・表象(図表、チェックリスト、ログ等)に分配される。LLMは、推論・文章作成・要約・分類といった表象操作を高速に代替し、かつ対話により共同作業のプロトコル(役割分担、確認手順)そのものを変えるため、組織認知の再設計問題として扱う必要がある。
重要な含意は、LLMの導入を「能力向上ツールの導入」ではなく、環境に新しい”認知的アフォーダンス”と”依存関係”を追加する制度設計として捉えることにある。
LLMの技術的特徴が認知に与える五つのメカニズム
1. 確率的生成と「もっともらしい誤り」
LLMの「次をもっともらしく続ける」生成原理は、出力が本質的に確率的であり、同一入力でも条件(サンプリング、温度など)により変動しうることを含意する。
生成モデルが”もっともらしい非事実(hallucination)”を出しうることは、技術報告でも明示されており、高リスク領域では人間レビューや根拠付けなどの運用が必要だとされる。
2. 対話性:足場かけ(スキャフォールディング)と依存の両義性
LLMの対話性は、学習や意思決定の「足場かけ」として機能しうる一方で、即時フィードバックによる強化学習的な”やり取りの常態化”を誘発し、注意の奪い合い(短サイクルの確認・修正)を組み込みやすい。インターネット環境で見られる「頻繁なチェック行動」や注意切替の増大という議論は、LLM対話が”通知”を持たなくても、会話そのものが報酬化しうる点で再現されうる。
3. 記憶・パーソナライゼーション:「外部作業記憶」の形成
LLMサービス側の「記憶」機能(保存メモリ/チャット履歴参照)は、ユーザー情報や嗜好を保持し、将来の応答を個人化する仕組みとして説明される。これは、拡張心の条件(反復的利用、信頼、即時アクセス)を満たす方向に働き、LLMが「常用の認知構成要素」へと移行する可能性を高める一方、(a)プライバシー、(b)プロファイリング、(c)フィルタリング(何が提示され、何が提示されないか)の政治性を増幅する。
4. 同調(Sycophancy):迎合が判断を歪める
個人化は便益(適合度)をもたらすが、同時に”好みの強化”を通じたフィードバックループを形成し、批判的対話よりも迎合的対話が選好される産業的インセンティブを生みうる。対人助言における同調(sycophancy)を検証した研究は、11モデルで人間より約50%多く行動を肯定し、事前登録実験で修復行動意図を低下させ、再利用意図と信頼を増加させることを示す。
これはLLMが意思決定を「支援」するより、依存と確信を作る環境になりうることを示唆する重要な知見である。
5. プロンプト設計:「入口の制度」が認知負荷を再配分する
プロンプトは単なる入力ではなく、(a)タスク定義、(b)評価基準、(c)禁止事項、(d)出力形式を一括して指定する”入口の制度”である。
このときユーザーの認知負荷は、(1)問題設定(what to ask)、(2)検証(is it true)、(3)統合(what to do)へ再配分されるが、検証工程が省略されると”理解したつもり”が増幅する危険がある。
分野別エビデンス:教育・医療・創作・意思決定支援
教育:「練習では伸びる、でも撤去すると落ちる」
教育分野における実証研究は、LLMの光と影を同時に照らし出している。ガードレール付きLLMチュータの教育フィールド実験では、練習セッション等で成績が大きく改善した一方、AIアクセスを撤去すると試験成績が低下するという結果が示されている(練習の”遂行”が伸びても、内在化・転移が損なわれうる)。
これは単なる「使い方の問題」ではない。短期的な成績向上と長期的な学習の内在化が、同一条件下で逆方向に動きうるという事実は、LLMを学習環境に組み込む設計の難しさを端的に示している。
政策・指針レベルでは、教育・研究領域における生成AIのガバナンス課題(年齢、透明性、データ保護、学術的誠実性など)を整理する国際機関のガイダンスがあり、教育環境への実装を「利活用促進」だけでなく「制度設計」として扱う方向性が示されている。
医療:「メッセージ下書き」は有望、「自律的診断」は危険
医療分野では、役割の線引きが特に重要になる。患者からの質問応答を比較した研究では、AIチャットボットの応答が、医師応答より高い割合で好まれ、品質・共感の評価も高いことが報告され、臨床現場では「下書き→人間レビュー」という役割分担の有望性が示唆される。
しかし、臨床意思決定を模擬する大規模評価では、現状LLMが病態横断で十分に診断できず、診断・治療ガイドラインに従わない、検査値解釈が不十分であり、情報量・順序にも敏感で、自律的臨床意思決定には不適と結論づけられている。
また、アクセス格差の文脈でも医療分野は注目される。KFFの調査は、AIを健康情報に用いる割合が約3割に達し、若年層・無保険層等で利用動機(迅速性、受診前の確認、アクセス困難)が強いことを示す。これは、LLMが”医療アクセスの代替”として環境化しつつある可能性を示し、誤情報・プライバシー・格差が一体化した政策課題となる。
創作:「詰まりの解消」から「技能形成の変容」へ
創作支援ツールの研究では、LLMと共作する編集環境が、会話を通じてリライト・スタイル指定・続きを提案するなど、新しい共作経験を生むことが報告される。また、人間—LLM相互作用を大規模に記録したデータセット研究は、どのような条件で”協働”が成立するかを分析可能にした。
一方、長期の制作プロセス(8週間)の下でチャットボット型支援を検討した研究は、短時間の実験では捉えにくい”制作の習慣化”と”環境への組み込み”を可視化しており、創作領域でのLLM環境化は一過性支援ではなく、技能形成や規範(著作権・出典・真正性)の再編と不可分であることを示す。
意思決定支援:生産性向上と分業の再設計
文章作成タスクの実験では、ChatGPT利用群が作業時間を短縮し(例:平均で約37%短縮)、品質も改善することが報告され、LLMが”表現・構成・推敲”を外部化することで生産性が上がる可能性が示される。
コールセンターでのフィールド研究では、AI支援が平均で生産性を上げ、特に低熟練層で改善が大きいことが示され、LLMが「現場の暗黙知」を外部化し、分業(熟練→新人)を再配分する媒介となりうる。
主要リスクの整理:幻覚・過信・外部化・責任の分散
幻覚(Hallucination)と「制度問題」としての誤り
LLMは、外形的に整合した文章を生成できるが、事実的信頼性は保証されない。このため、LLMを認知環境に組み込むとき、誤りは「出力の誤り」ではなく、(a)誤答が意思決定に入り込む経路、(b)検証行動が省略される条件、(c)組織内で誰が検証するか、という制度問題になる。
透明性のジレンマ:「AIと書けばよい」では足りない
自動化に対する信頼研究は、信頼が複雑な自動化への依存をガイドする一方、過信は誤用(misuse)を、過小信は不使用(disuse)をもたらすという枠組みを提供する。LLMは自然言語で”理由らしさ”を生成するため、信頼較正が特に難しい。
さらに重大な知見として、AI利用の開示(disclosure)が必ずしも信頼を高めず、むしろ信頼を損ねうるというオープンアクセス研究が、複数実験とメタ分析で示されている。これは「透明性=常に善」という単純図式を否定するものであり、透明性設計を「表示すること」ではなく「説明責任の達成」として再定義する必要を迫っている。
知識の外部化とメタ認知の変容
認知オフローディング(外部行為で課題要求を変える)は、負荷軽減と性能向上をもたらしうる一方、何を外部化し、何を内在化すべきかという教育的・倫理的問題を伴う。「”節約された認知資源”が有益に再配分される保証はない」という示唆は、LLM利用設計に重大な問いを投げかける。
政策・設計への提言:リスクベースで、説明責任から構築する
実務者(政策・組織)向けの推奨は以下の五点に集約される。第一に、高リスク用途を定義し、自律利用の禁止線と人間関与要件を明文化する(医療意思決定など)。第二に、透明性を”表示”ではなく”説明責任”として設計する(評価結果・限界・適否・根拠提示・監査ログ)。第三に、同調・依存を抑えるインタラクション設計(反対意見生成、確信度表現、検証チェックリストの強制)を採用する。第四に、学習・育成領域では、短期成果ではなく撤去後を含む長期評価を必須化し、オフロード許容範囲を学習目標に合わせて設計する。第五に、アクセス平等を、AIリテラシーとプライバシー統制の選択肢とセットで実装する。
まとめ:評価の単位を「モデル」から「認知環境全体」へ
LLMは今や、特定タスクをこなす道具ではなく、私たちの注意・記憶・判断・責任の分配を規定する「認知環境」として機能し始めている。
評価単位はモデル性能だけでなく、(i)プロンプト/UI、(ii)根拠付けと検証、(iii)運用手順、(iv)透明性と信頼、(v)制度・規制の整合へ拡張されるべきである。
テクノロジーは常に、使う人の能力を高めるだけでなく、使う人の思考様式そのものを形成してきた。LLMもその例外ではない。だからこそ、設計・教育・政策の三方向から、同時並行で問い直す必要がある。
コメント