日本語LLMの「特殊性」は4つの軸で理解する
「日本語のAIはなぜ英語より精度が低いのか」——この問いを「学習データが少ないから」だけで片づけてしまうと、本当の改善ポイントを見落とします。
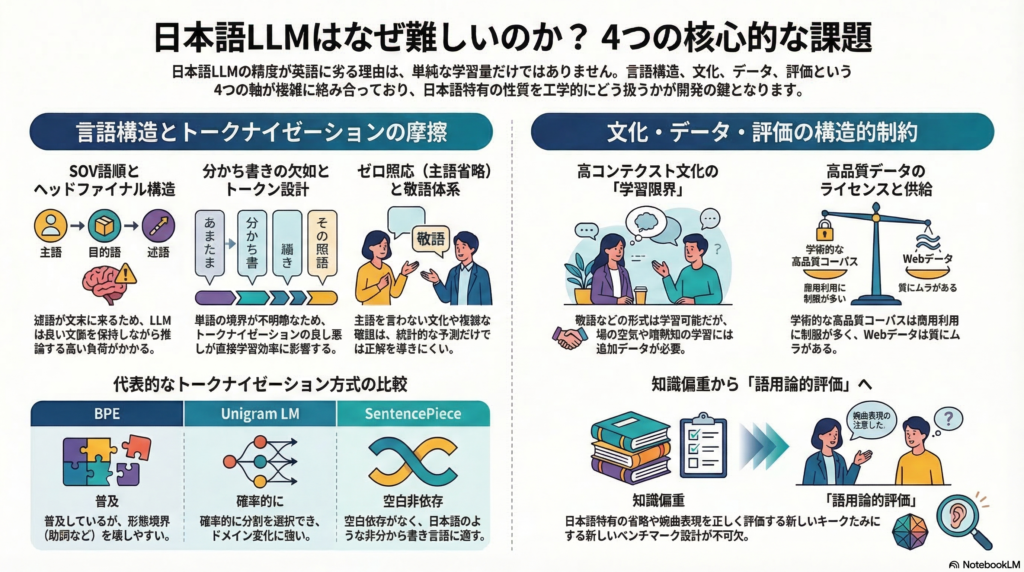
日本語LLM(大規模言語モデル)の難しさは、(1) 言語構造とトークナイゼーションの相互作用、(2) 高コンテクスト文化や敬語の「学習可能性」、(3) コーパスの量・質・ライセンス制約、(4) 評価ベンチマークの設計限界、という四つの軸が複雑に絡み合った構造問題です。本記事では、この四軸をそれぞれ掘り下げ、なぜ日本語LLMの開発が一筋縄ではいかないのかを整理します。
日本語の言語構造がLLMの「次トークン予測」に与える摩擦
空白なし・SOV・ヘッドファイナルという三重の壁
Transformerベースのデコーダ型LLMは、過去の文脈から次のトークンを予測する自己回帰学習を基本とします。英語であれば単語間にスペースがあるため、自然な分割単位が存在します。ところが日本語には分かち書きがなく、「どこで切るか」というトークン境界の設計自体が、モデルの統計的学習の前提条件を形成してしまいます。
さらに日本語はSOV語順(主語→目的語→述語)かつ「ヘッドファイナル」、つまり文の主要情報である述語が文末に来る構造を持ちます。英語のSVO語順(主語→述語→目的語)とは「予測処理のタイミング」が根本的に異なります。左から右へ逐次トークンを生成するLLMにとって、日本語では長い助詞・係り受け連鎖を保持しながら文末の述語まで待たなければならず、長距離依存の保持が英語以上に重要な課題になります。
形態論・ゼロ照応・敬語という語用論的負荷
日本語の摩擦点はさらに続きます。
**形態論(活用・複合語)**では、語幹・活用語尾・接辞の組み合わせで表層形が多様に変化するため、語彙が膨張しやすく、トークナイゼーション次第で語彙の安定性が大きく変わります。
**主語省略(ゼロ照応)**は、日本語が「主語を言わなくてよい言語」であることから生じます。述語だけ見ても誰が何をしたか分からないケースが多く、文脈全体から項を補完する能力がモデルに求められます。これは表層の手がかりが少ない分、単純な統計学習では対処しにくい問題です。
敬語体系は、話者・聞き手・話題人物の社会関係(上下・内外・距離・場面)に応じて表現が体系的に変化します。「文法」と「社会モデル」の複合問題として、LLMが正確に再現するには相当量の高品質な注釈付きデータが必要になります。
トークナイゼーション設計の選択肢と日本語固有のトレードオフ
日本語LLM開発で最初に直面するのが、トークナイゼーション設計の選択です。代表的な方式とその特性を整理します。
BPE(Byte Pair Encoding) は実装が広く普及しており、語彙サイズ管理も容易ですが、頻度ベースのマージが形態境界を壊しやすいという弱点があります。「助詞またぎ」が起きると、文法的な単位をまたいでトークンが結合され、助詞・敬語・活用の学習を阻害する可能性があります。
Unigram LM は確率モデルで分割を選択するため、分割の曖昧性を確率的に扱えます。「サブワード正則化」(複数の分割をサンプルしながら学習する手法)と組み合わせることで、ドメインシフトへの頑健性を高めやすい特性があります。
SentencePiece は「前処理としての空白分割に依存しない」設計であり、日本語のような非分かち書き言語で実装上の利点が大きく、BPEとUnigramの両方を実装しています。
形態素解析ベースのアプローチは形態境界が比較的一貫しますが、辞書依存・未知語対応・ドメイン差による分割の不安定さという課題が残ります。
実務的な結論として、「日本語の文法現象をモデルが圧縮できる単位で切れているか」が鍵です。語用論タスク(敬語・省略・含意)を重視する場合は、BPEだけに依存するのでなく、Unigramやサブワード正則化、形態素解析とのハイブリッドを検討する価値があります。
文化的文脈をLLMが「学習できる範囲」の見極め
高コンテクスト文化の「学習可能性」を二分する
日本語コミュニケーションはしばしば「高コンテクスト」と表現されます。行間・省略・察しへの依存が高く、言語外の共有前提や非言語情報が重要な役割を果たします。この「高コンテクスト性」を、LLMはどこまで学習できるのでしょうか。
答えは二分されます。
学習可能な側面:観測可能な言語的規則——敬語の選択、婉曲表現、定型的な断り方、あいづち、ポライトネス方略などは、テキスト上の表現として観測できます。十分な量と多様性のある正例・負例データがあれば、統計的学習が成立しやすい領域です。
学習困難な側面:外部世界・共同注意に依存する暗黙知——共有経験、場の空気、沈黙の意味、企業文化固有の慣行などは、テキストだけからは同定できない場合が多いです。このような暗黙知の学習には、追加モダリティ(音声・映像)、場面や関係性のメタデータ、あるいは意図ラベルの人手注釈が必要になります。
敬語学習を「工学的に実装する」四つのレイヤ
敬語の学習を実装する方法論は、おおむね次の四レイヤで整理できます。
①データ収集(観測可能性の最大化): 敬語選択が話者間の関係性に依存するため、会話データでは話者属性や関係性メタ情報が付くコーパスが価値を持ちます。KeiCOのような「社会的地位に基づく敬語現象」に特化したコーパスが構築されている点は、文化的文脈を学習可能な形に落とした実例として重要です。
②注釈(社会関係ラベルと誤り定義): 「正しい敬語」は状況依存であり、単純な正誤ではなく「適切性」の問題になります。関係性(上司-部下、顧客-店員)、場面(社内/社外、公式/非公式)、意図(依頼/謝罪/断り)まで含めた注釈設計が必要です。
③指示追従チューニング(SFT): 指示文の設計自体が評価の一部になります。llm-jp-evalのように、既存データをプロンプト形式に変換して統一評価する枠組みは、この設計思想を実装した好例です。
④RLHF(人間のフィードバックによる強化学習): 「人が好む応答」へモデルを寄せる手段として有効ですが、日本語の敬語・婉曲を英語圏のアノテータ規範で最適化すると不自然になるリスクがあります。日本語母語話者・領域専門家による評価基準の策定が不可欠です。
日本語コーパスの「量・質・ライセンス」の現実
高品質な公式コーパスと「学習利用」の壁
日本語には言語研究向けに設計された高品質なコーパスが複数存在します。BCCWJ(現代日本語書き言葉均衡コーパス)は書籍・雑誌・新聞・ブログ・掲示板など複数ジャンルを横断する均衡コーパスです。話し言葉ではCSJ(日本語話し言葉コーパス)やCEJC(日本語日常会話コーパス)が整備されています。
しかし、これらの公式コーパスは品質は高いものの、商用利用や大規模学習への適用条件が制限されているケースが多く、LLMの大規模事前学習データとしてそのまま使えるとは限りません。これは「使える高品質日本語」を確保する上での現実的制約です。
WebコーパスはLLMの主戦場だが、リスクも増える
LLMの事前学習は、規模の観点からCommon Crawl等のWebデータに依存しやすい状況です。大規模日本語Webコーパスを「LLMの学習に耐える品質」にするには、テキスト抽出→言語判定→品質フィルタ→重複排除→ホストフィルタリングという工程設計が性能に直結します。実際にCommon Crawlの複数スナップショットを活用した日本語Webコーパス構築研究では、継続事前学習によって日本語ベンチマークスコアの一貫した改善が報告されています。
一方で、英語中心の多言語モデルでは日本語の学習データ比率が著しく小さい場合があるとも指摘されており、言語分布は日本語性能の上限を規定し得ます。Webデータ活用においても、ライセンス・個人情報・有害表現・ドメイン偏りへの対処は技術問題と同程度に重要な課題です。
日本語LLMの評価ベンチマーク:到達点と設計上の限界
JGLUEからllm-jp-evalまでの現状
日本語評価では、JGLUEが「翻訳ではなく日本語で作られた」複数タスクからなるベンチマークとして重要な位置を占めています。文分類・文ペア・QAなど多様なタスクで構成され、日本語NLPの標準的な評価基盤として機能しています。
JMMLUはMMLUの翻訳問題に加えて、日本固有の文化背景に基づく問題を追加した多肢選択ベンチマークです。「翻訳適用の限界」を意識した設計として注目されます。llm-jp-evalは複数の日本語データセットをプロンプト形式に変換し、生成モデルとして統一的に自動評価する枠組みを提案しており、モデル比較を体系化する上で有用です。
対話評価のRakudaはLLM-as-a-judgeを用いる日本語評価として運用されていますが、1ターン対話・少数データという制約があり、測定できる側面が限定的である点に留意が必要です。
日本語固有の評価タスクが今後の鍵を握る
既存ベンチマークが「知識・精度」中心なのに対して、日本語LLMの実務上の失敗は語用論的側面——省略補完の失敗、敬語の崩れ、含意の取り違え——に集中しやすいという指摘があります。これを正確に測るには、現行のベンチに加えて、次のような「日本語固有ベンチ」の設計が求められます。
- 省略・ゼロ照応タスク: 主語省略・項補完の失敗を指示語・項同定で測定する
- 敬語適切性タスク: 社会関係に合う敬語選択をペア比較(人手またはLLMジャッジ)で評価する
- 含意・婉曲理解タスク: 「断り」「遠回しな意図」を文字通り解釈する誤りを多肢選択と理由説明で測る
- 文体・レジスタ変換タスク: 丁寧体/普通体、口語/文語の切り替えを変換精度で評価する
評価設計の実務要点は三つです。①正解が一意でない語用論現象を「違反の種類」として定義すること、②自動採点だけでなく人手またはペア比較を組み込むこと、③省略・敬語・含意を同一対話の複数ターンで測定すること——これらが日本語固有の失敗を正確に捕捉するための条件です。
まとめ:日本語LLM開発の優先度と次のステップ
日本語LLMの「特殊性」は、データ量の問題に還元できない構造的課題です。言語構造(形態論・ゼロ照応・敬語・ヘッドファイナル性)がトークナイゼーション設計と深く絡み合い、文化的文脈の学習可能範囲は「観測可能な言語的規則」に限定され、コーパスのライセンスはWebデータへの依存を強い、評価ベンチは語用論的失敗を見落としやすい——これら四軸が同時に作用しています。
実務的には、まず①トークナイザ設計の再検証(Unigram・サブワード正則化・形態素ハイブリッド)、②Webコーパス構築工程の品質担保(品質フィルタ→重複排除→ホストフィルタ)、③評価の二層化(自動ベンチ+多ターン人手評価)の三点を優先的に固めることが、後段のSFTやRLHFの効果を最大化する近道です。
文化的知性をLLMで「操作化」するには、内面属性として語るのではなく、敬語違反率・含意の取り違え率・謝罪/断りの適切性といった検証可能な行動指標に落とし、データ化→チューニング→評価の改善ループに組み込む視点が不可欠です。
コメント