内的対話とは何か?AIと思考の関係が注目される理由
「頭の中で自分に語りかける声」——それが内的対話(インナーボイス)です。私たちは問題を整理するとき、意思決定を下すとき、感情を処理するときに、無意識のうちにこの内なる言語を使っています。
近年、大規模言語モデル(LLM)の普及により、AIがこの内的対話を「外部化・拡張する」ツールとして機能することが注目されています。ChatGPTやClaudeに考えを打ち込むことで、思考が整理され、新たなアイデアが生まれるという経験をした方も多いでしょう。
本記事では、①内的対話の神経基盤と心理学理論、②LLMが思考補助として機能する仕組み、③AI依存がもたらす認知リスクと対策、という三つの柱で、脳・技術・実践の観点から徹底解説します。
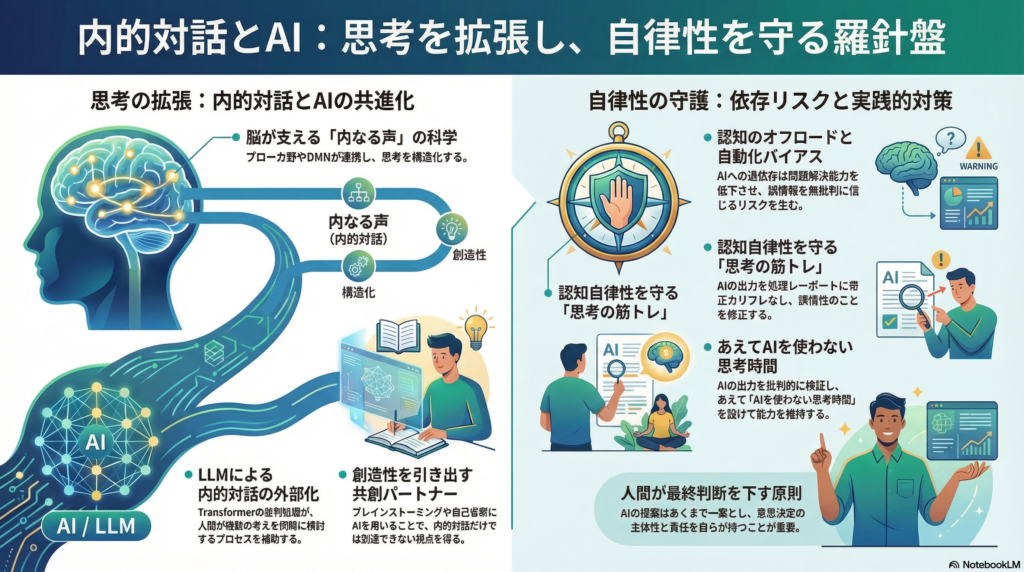
内的対話の神経基盤:脳のどこが動いているのか
内的対話を支える主要な脳領域
内的対話は、単なる「心の独り言」ではありません。脳の複数のネットワークが協調して機能する、高度な認知プロセスです。
左下前頭回(ブローカ野) は、外声での発話だけでなく「頭の中で話す」行為においても活性化することが神経画像研究で繰り返し確認されています。内的発話の生成過程において、ブローカ野は中心的な役割を担っており、言語の産出機構が内面的にも同様に機能していることを示しています。
左上側頭回(ウェルニッケ野の一部) も内的対話時に活性化します。これは、自分が頭の中で話した言葉を、脳が「想像上の聴取」として処理していることを示唆します。言語を「産む」回路だけでなく「聴く」回路も内的対話に関与しているという点は、内的対話が実際の会話と類似した神経メカニズムを持つことを意味します。
デフォルトモードネットワーク(DMN) は、内側前頭前野・後部帯状皮質・前部帯状皮質などを含むネットワークで、自己に焦点を当てた内省的思考の際に活性化します。日常的な空想、自己の回想、将来の計画を立てるときにも動作し、内的対話とは切り離せない関係にあります。
特に注目されるのは「対話的な内的対話」——つまり、自分の中で異なる視点を持つ声と議論する場合です。この形態では、前頭前野と後部帯状皮質が顕著に活動し、言語領域と連携した両側性の側頭領域も動員されます。これは、他者の視点をシミュレートする「Theory of Mind(他者理解)」ネットワークが内的対話にも使われていることを示しており、内なる対話が本質的に「社会的」な認知プロセスであることを示唆しています。
背外側前頭前野(DLPFC) などの実行機能領域は、内的対話の開始・停止・焦点の維持・話題の切り替えを制御します。また、自己の内的な声を外部の音と区別する役割も担っており、この調整機能の不全が幻聴の一因となる可能性も研究で示されています。
内的対話の心理学的理論
ヴィゴツキーの内言理論 は、内的対話の発達的起源を説明する上で欠かせない理論です。幼児期には行動ガイドとして機能する「私語(自己に向けた発話)」が存在し、成長とともにそれが内面化されて内的対話へと変化するとされています。ヴィゴツキーはこれを「言葉による思考の基盤」と位置づけ、内的対話が自己調整や思考整理に不可欠であると主張しました。幼児が課題をこなしながら声に出して自己指導する姿は、のちに外から見えない内的対話へと移行していきます。
メタ認知と自己調整 の観点では、内的対話は「自分の思考を考えるプロセス」として機能します。ワーキングメモリの「音韻ループ」の一部としての役割も示唆されており、計画・推論・自己制御といった実行機能を補助するとされています。
アラン・モリンの自己認識理論 では、内的な言葉が自己の経験を記述・評価する過程を通して、アイデンティティや自己の物語を構築すると説明されます。内的対話が一人称(「私」「自分」)で行われるのは、幼少期に親などとの対話を内面化した結果と考えられており、この「内的対話モデル」が自己反省・情動調整・創造性の発揮を支えています。
フェルニハフのスペクトル理論 は、内的対話を「断片的な内的言語」から「対話的な内面会話」まで幅広い形態として捉えます。用途に応じて使い分けられるこのスペクトルは、内的対話が固定的なものではなく、状況に応じて柔軟に変化する動的なプロセスであることを示しています。
これらの理論を総合すると、内的対話は外部との対話から内面化され、思考を調整・反省・構造化するための言語を介した認知ツール と位置づけられます。
LLMが思考補助ツールとして機能する仕組み
Transformerアーキテクチャと事前学習
現代のLLMの中核にある Transformerアーキテクチャ(Vaswaniら、2017年)は、自己注意機構(Self-Attention)により文章内の全単語を並列処理し、長距離の依存関係を効率的に捉えます。入力テキストはトークン(サブワード単位)に分割されてベクトル化され、複数の注意層を通じて文脈に応じた意味が統合されます。
GPT-3のような大規模モデルは数百億のパラメータを持ち、「次の単語予測」という一見シンプルなタスクを通じて、文法・事実知識・文脈のニュアンスを膨大なテキストから学習します。この事前学習の結果として、LLMはプロンプト内の指示や例示だけで多様なタスクに対応できる few-shot・zero-shot学習能力 を発揮します。
Transformerの仕組みは、数千語単位の文脈を同時保持しながら各情報片を相互評価する点で、人間が複数の考えを同時に検討するプロセスに類似しています。
対話型インターフェースと整合性向上技術
生の事前学習モデルをそのまま使うと、対話的なパートナーとしては不十分な場合があります。そこで、RLHF(人間のフィードバックを用いた強化学習) によるインストラクションチューニングが実施されます。ChatGPTやClaudeに代表されるこのアプローチでは、人間の評価者がモデルの応答を評価し、そのフィードバックをもとにモデルが応答の正確性・関連性・適切さを向上させます。
チャット形式のインターフェースは、ユーザーとLLMの対話を連続的に保持し、各ターンごとに文脈を更新します。これにより、ユーザーは段階的に思考を整理し、問いを深掘りできます。これはソクラテスの問答法やブレインストーミングに類似しており、ユーザーの考えとAIの生成内容が相互に影響し合うフィードバックループが形成されます。
また、RAG(検索拡張生成) により外部データベースと統合することで、LLMは固定された学習データの枠を超えた最新・専門情報の活用が可能になります。
具体的な思考補助の活用例
LLMによる思考補助は、次のような場面で特に効果を発揮します。
ブレインストーミング: 「太陽光発電ドローンの活用方法」や「SF小説のプロットアイデア」など特定のテーマを入力すると、多様で予想外の視点が提示され、内的対話だけでは到達しにくかった発想の拡張が期待できます。
文章作成支援: アウトライン作成・文章推敲・段落構成など、自分の考えを文章化するプロセスをAIが補助します。ドラフトを受け取ってユーザーが編集・発展させる過程で、自分自身の論理を再検討する機会にもなります。
学習と探求: 複雑な概念の段階的な説明や、「ラバーダック・デバッグ」(問題を言語化する過程で解決の糸口をつかむ手法)としての活用が有効です。
自己省察と意思決定: 「転職すべきか」「プレゼンにどう備えるか」といった問いに対して、LLMが利点・欠点を整理することで、ユーザー自身の思考プロセスを俯瞰し、深める支援を行います。
創造的な共創: 作詞家がテーマに基づくアイデアを求めたり、デザイナーがコンセプトの言語化を求めたりと、AIが人間の創造性を補完するパートナーとして機能しています。
AI依存のリスクと認知自律性を守る方法
過度なAI依存がもたらす認知的リスク
LLMが有用であればあるほど、過度な依存による弊害も無視できません。
認知のオフロード は最も懸念されるリスクです。頻繁にAIに答えを求めることで、情報を自分で保持・処理する努力が減少し、問題解決能力や批判的思考力が低下する可能性があります。GPSへの過依存で方向感覚が衰えるのと類似した現象です。外部ツールへの依存が進むと、人は情報そのものではなく「情報を探す方法」だけを記憶する傾向があるという指摘もあります。
自動化バイアス も重要な問題です。LLMは自信満々に応答を生成するため、ユーザーがその回答を無批判に受け入れやすい傾向があります。しかしLLMはあくまで統計的にテキストを予測するシステムであり、「幻覚(ハルシネーション)」と呼ばれる誤情報が含まれることもあります。推論プロセスが不透明なブラックボックス性が、ユーザーの検証意識を低下させ、深く考えるプロセスが省略されるリスクがあります。
アイデアの均質化 も懸念されます。複数のユーザーが同様のプロンプトを使えば、LLMの出力は似通ったものになりやすく、個人が自律的に考えた場合に生まれる多様性が失われる可能性があります。
さらに、AIの提案が多く反映されると、意思決定の主体性と責任感が希薄化 するリスクもあります。「このアイデアは自分のものか、AIのものか」が曖昧になることで、失敗時の責任意識や長期的な創造力の発展が損なわれる可能性があります。
認知自律性を守るための実践的対策
これらのリスクに対し、以下の対策が有効とされています。
積極的関与と批判的検証: LLMの出力を受け取ったあとは、自らも検証し、必要に応じて修正や反論を加える姿勢が重要です。AIの提案をゼロ地点からの思考整理のきっかけとして使う意識が求められます。
利用範囲の明確な区分: AIに任せるタスクと自分で考えるタスクを意識的に分け、「AI非依存の思考時間」を設けることで、思考筋肉の維持・強化を図ります。
LLMの仕組みへの理解: モデルが確率的にテキストを生成するという本質を理解し、出力内容の真偽を自ら検証する習慣が、過度な依存を防ぐための基盤となります。
多様な情報源・思考の活用: 一つのAIモデルに依存せず、複数の情報源や人間同士の議論を組み合わせることで、アイデアの均質化を防ぎます。
最終判断は人間が下す原則の維持: AIの提案はあくまで一案として参照し、最終的な意思決定は自らの判断に基づく習慣が、長期的な認知自律性の維持に不可欠です。
まとめ:脳・AI・主体性の三位一体で思考を進化させる
内的対話は、ブローカ野・ウェルニッケ野・デフォルトモードネットワークなど複数の脳領域が連携して支える高度な認知機能です。ヴィゴツキーの内言理論が示すように、それは外部の対話が内面化されたものであり、自己調整・問題解決・創造性の基盤となっています。
LLMはTransformerアーキテクチャと大規模事前学習により、この内的対話を外部化・拡張する有力なパートナーとなりえます。ブレインストーミング・文章作成・自己省察・創造的共創など、多様な思考支援が可能です。
一方で、認知のオフロード・自動化バイアス・アイデアの均質化・主体性の喪失といったリスクも現実のものです。重要なのは、「人間が常に最終的な判断者である」 という意識と仕組みを保ち続けること。AIを使いながら自分の認知を「筋トレ」し続ける意識改革こそが、テクノロジーと人間知性の健全な共存を実現します。
コメント