はじめに:なぜ「人間とAIの協調」が因果推論に求められるのか
データから「何が原因で何が起きているか」を明らかにする因果推論は、医療・政策・産業の意思決定において欠かせない分析手法です。しかし実際の現場では、専門家の知識とデータ駆動の推定を適切に組み合わせることが非常に難しく、属人的な判断や再現性の低い分析が課題となりがちです。
一方で、大規模言語モデル(LLM)の普及により、「AIに因果推論をそのまま任せてしまえばいいのでは」という誤解も広まっています。しかしLLMは、観察データを直接見ずに推論したり、幻覚(hallucination)を起こしたりする制約があり、因果推論エンジンの代替にはなり得ません。
本記事では、こうした課題を解決するために提案された**HACIF(Human–AI Collaborative Inference Framework)**について、理論背景から実装設計、評価・ガバナンスに至るまでを体系的に解説します。
HACIFとは何か:人間とLLMの役割分担を明確にする設計思想
HACIFの基本コンセプト
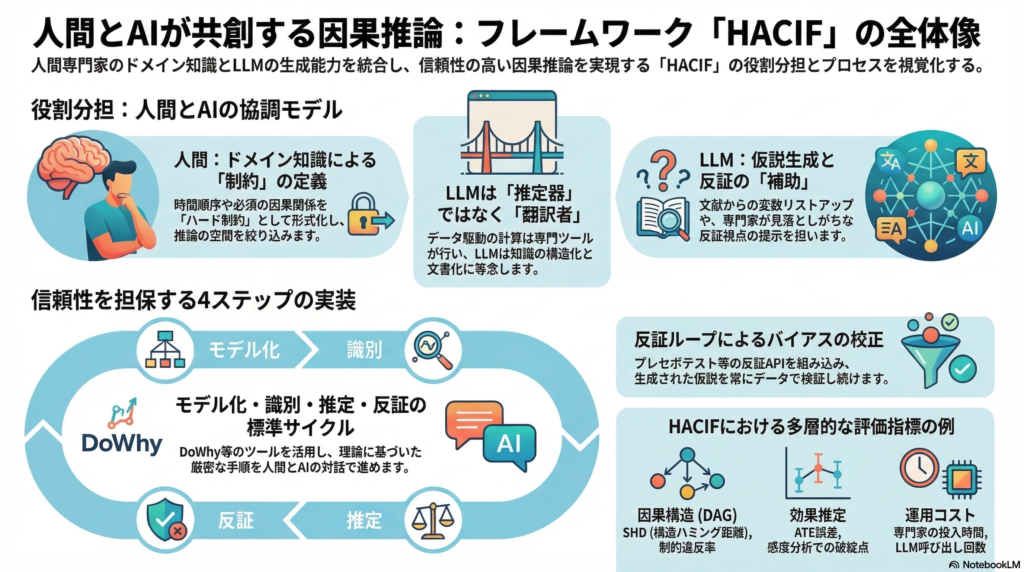
HACIFは、「人間専門家のドメイン知識」と「LLMの自然言語処理・仮説生成能力」を、因果推論のプロセス全体に協調的に組み込むための実装可能なフレームワークです。
重要なのは、LLMをあくまで補助者として位置づけることです。具体的には以下の3つの役割に限定しています。
- 知識の抽出・翻訳・対立仮説の生成:専門家が言語化した因果メカニズムを構造化し、候補交絡や媒介変数を列挙する
- 反証の促進:過信を防ぐため、反証可能な仮説を生成し検証ループを駆動する
- 設計・監査文書の整形:プロンプト、DAG版、推定版など、監査可能なドキュメントを整備する
一方、データ駆動の因果推定・検定・反証はあくまで中核として人間の監督下に置かれます。
HACIFが依拠する因果推論の理論基盤
HACIFは以下の確立された理論を土台とします。
- 構造的因果モデル(SCM)と因果図・do-calculus(ジューディア・パール):因果図(DAG)とdo-calculusにより、観察分布と介入分布の差を計算可能にする
- 制約ベース/スコアベースの因果発見(スパイツ、グライマー、シャインズ):観察データの条件付き独立関係から因果構造を推定する
- 潜在アウトカムと交絡(ルービン、エルナン、ロビンズ):交換可能性・陽性性・整合性を前提に、観察研究での因果効果を識別する
これらの理論を踏まえた上で、HACIFは「モデル→識別→推定→反証」という4ステップを、人間とLLMの協調で制度化することを目指します。
人間専門家の知識をどう形式化するか:ハード制約とソフト制約
専門家知見の2層表現
専門家が持つ知識は、自然言語で語られることが多く、そのままでは計算機が扱えません。HACIFでは、専門家知見を以下の2層で表現します。
ハード制約(Hard Constraints)
- 時間順序:「Aの後にBが起きる」といった因果方向の制約
- 禁止辺:制度上あり得ない因果方向
- 必須辺:必ずある因果関係
- 測定不能変数の存在宣言
これらは因果図の探索空間を絞り込む役割を果たします。
ソフト制約(確信度つき仮説)
- 辺や因果経路の事前確率
- 交絡の強さの事前分布
ソフト制約は推定・反証のなかで更新され続ける「暫定的な前提」として扱われます。
専門家バイアスの校正
専門家判断には認知バイアス(たとえば基率の過小評価など)が含まれる可能性があります。このため、HACIFは**構造化専門家判断(Structured Expert Judgment)**の枠組みを参照します。
複数専門家の統合方法として、デルファイ法のような反復合意形成と、線形オピニオンプールなどの数理統合を組み合わせ、合意を「最終投票」ではなく**「更新可能な暫定合意」**として扱うことが特徴です。
LLMの能力と限界:因果推論における役割の正しい理解
LLMが得意なこと
LLMは次のような領域で因果推論プロセスに貢献できます。
- 論文や報告書から因果要因・メカニズムを列挙する
- 候補交絡変数のリストアップと説明文の生成
- 反証視点(「なぜこの解釈が誤りかもしれないか」)の提示
- 因果議論の外形を整えた説明文書の作成
LLMの重大な制限
一方で、以下の限界は実務上深刻です。
- データなしでの推論:観察データを直接見ない状態で因果関係を断言する傾向
- ベンチマーク問題:既存の因果推論ベンチマークは「知識検索で解けてしまう」問題があり、性能評価が過大になりやすい
- 幻覚(Hallucination):根拠のない情報を自信満々に生成するリスク
- 失敗モードの予測困難性:どの場面で誤るかが事前に判断しにくい
これらの理由から、HACIFではLLM出力に必ず「不確実性(確信度)」「根拠の所在(出典・ログ)」「反証可能な予測」を付与し、後段の反証ループに接続する設計を採用します。
ReAct的な「行為」の活用
LLMに推論と外部ツール参照を組み合わせさせる設計(ReActパターン)は、幻覚や誤り伝播を抑制する可能性があります。HACIFでも、LLM単体の「思考」だけでなく、因果推論ツール・文献検索・ログ照合などのツールユースをプロトコルに組み込むことで、信頼性を高めます。
統合設計の核心:仮説生成から反証ループまでの実装
知識融合の3原則
HACIFにおける人間知識とLLM知識の統合は、以下の3点を核とします。
- 同じ表現空間への写像:専門家の自然言語知見を因果図のパス制約として形式化し、LLMが生成した仮説と同じ土俵で比較可能にする
- データによる更新規則の明確化:LLM由来の因果仮説を「事前(prior)」として位置づけ、データ駆動の因果発見で全体整合性を保ちながら更新する
- 反証で壊れる設計:placebo検証・ブートストラップ・未観測交絡テストなどの反証APIを組み込み、どんな仮説も反証可能にしておく
能動的質問による専門家負担の軽減
HACIFでは、LLMを「仮説生成者」だけでなく**「質問設計者」**としても活用します。候補グラフ分布を保持しながら、情報利得が高い関係に絞って専門家へ質問し、専門家の投入コストを最小化する人間参加型の因果発見設計を採用します。これにより、専門家は「すべての変数関係を一から確認する」のではなく、「最も不確実で重要な箇所だけを判断する」作業に集中できます。
合意形成アルゴリズム
HACIF内の合意形成は次の組み合わせで実現します。
- 重み付き意見プール:専門家とLLMの主張を信頼度で重み付けして統合
- ベイズ更新:新たなデータや反証結果が出るたびに信念を更新
- 反証駆動ループ:推定が崩れるケースを積極的に探し出し、修正を繰り返す
実装要件:ツールチェーンとデータ設計
推奨ツールチェーン
HACIFの実装では、以下のツールを組み合わせることが推奨されます。
- DoWhy:「モデル→識別→推定→反証」の4ステップAPIを提供し、因果仮定の明示と反証を標準化する
- Tetrad:PC・FCI・FGESなど古典から最新の因果発見アルゴリズムを実装し、Python/Rから呼び出せる
- EconML:異質効果推定(Heterogeneous Treatment Effects)のための機械学習ライブラリ。二重機械学習(DML)や因果フォレストの推論・交差検証・解釈ツールを備える
これらを分離したモジュールとして構成し、インターフェースで結合することで、推定器の交換が容易になります。
目標試験(Target Trial)の明示
観察データを用いる場合、目標試験(target trial)を明示して設計することが不可欠です。「どの母集団に・どんな介入を・何と比較し・どのアウトカムを・いつまで追うか」を明文化しないと、immortal time biasなどの系統的誤りが生じやすくなります。
プライバシーと監査のバランス
HACIFでは「ログに何を残すか」が最重要設計点のひとつです。監査可能性のためのログ保存と個人情報最小化の両立が求められます。日本の個人情報保護委員会が示す、要配慮個人情報の収集段階での低減措置などを踏まえ、ログ設計を事前に確定しておくことが重要です。
評価指標:多層メトリクスによる品質管理
HACIFでは、単一の推定精度(ATE誤差など)だけでなく、以下の多層メトリクスで評価します。
| 評価対象 | 主なメトリクス |
|---|---|
| 因果構造(DAG) | SHD、辺のPrecision/Recall、制約違反率 |
| 識別の正しさ | 識別可能判定の正答率、識別条件の説明完全性 |
| 効果推定 | ATE誤差、CI被覆率、感度分析での破綻点 |
| 反証 | placebo/negative controlの検出率、修正回数 |
| 透明性・監査 | プロンプト・モデル版・データ版の完全性、再実行可能性 |
| 人的負担 | 専門家の投入時間、質問回数 |
| 計算コスト | LLM呼出回数、探索時間 |
検証では「人間のみ」「LLMのみ」「協調(HACIF)」の三条件を比較し、協調設計が全体整合性の担保において優位かどうかを確認します。
ケーススタディ:医療と政策評価への適用
医療EHRでの因果効果推定
MIMIC-IVなどの公開EHRデータを用い、「治療介入が30日死亡に与える影響」を推定するケースを想定します。専門家が目標試験テンプレートを確定し、LLMが候補交絡・媒介・測定誤差要因を不確実性タグつきで列挙します。DoWhyの4ステップで識別・推定・反証を実行し、感度分析とDAG修正ループを回します。評価は再現性・透明性・人的負担の三軸で行います。
政策・公衆衛生領域での合成コントロール
州レベルの政策介入(タバコ対策など)の因果効果を合成コントロール法で推定するケースでは、専門家が政策の施行内容・同時期の共変政策・禁止比較単位を整理し、LLMが潜在的な同時ショックや代替説明を列挙してplacebo設計候補を提示します。推定頑健性と透明性(除外理由の監査可能性)が主要評価指標になります。
ガバナンス:責任分担と監査設計の制度化
HACIFのガバナンス設計は、米国NISTのAI RMFが示す「透明性がアカウンタビリティの前提」という考え方を基本とします。また日本の経済産業省・総務省のAI事業者ガイドラインが示す「主体別(開発者/提供者/利用者)のリスクベース設計」も埋め込みます。
EU AI Actは高リスクAIに対して自動ログ(record-keeping)を要求しており、国際展開を視野に入れる場合はログ設計を早期から整合させることが望ましいとされています。HACIFでは、プロンプト・モデル版・データ版・DAG版・推定版・反証結果をすべてログとして記録し、監査可能なトレーサビリティを実現します。
まとめ:HACIFが示す「人間とAIの正しい役割分担」
本記事では、人間専門家とLLMを協調させた因果推論フレームワーク「HACIF」の全体像を解説しました。要点を整理します。
- LLMは因果推論の「代替推定器」ではなく、仮説生成・反証促進・文書整形の補助者
- 専門家知見はハード制約とソフト制約として形式化し、探索空間を絞る
- 推定と反証(DoWhy型プロセス)を中核に据え、信頼を更新し続ける
- ログと監査をプロトコルに内蔵し、透明性とアカウンタビリティを担保する
因果推論は、「相関関係を見つけること」ではなく「介入した場合に何が起きるかを推定すること」です。その難しさに正直に向き合い、人間とAIそれぞれの強みを正確に位置づけるHACIFのアプローチは、研究と実務の両面で参考になる設計思想といえます。
コメント