身体化AIが注目される理由:言語だけでは「意味」が完結しない
大規模言語モデル(LLM)の性能は急速に向上し、文章生成・要約・推論においては人間に匹敵する出力を生み出すようになりました。しかしその一方で、「テキストだけを操作するAIは本当に意味を理解しているのか」という根本的な問いが研究者の間で改めて議論されるようになっています。
この問いに対する一つのアプローチが、LLMに「身体」を与えること、すなわち**身体化(Embodiment)**です。視覚・触覚・力覚といったセンサや、ロボットアームや移動機構といったアクチュエータを通じて物理世界と相互作用させることで、言語の「参照先」を現実の行為と結びつける試みです。
本記事では、身体化LLMの定義と分類から、主要な技術的アプローチ、認知的影響の仮説、代表的な研究事例、評価指標、そして倫理・安全性まで、体系的に解説します。
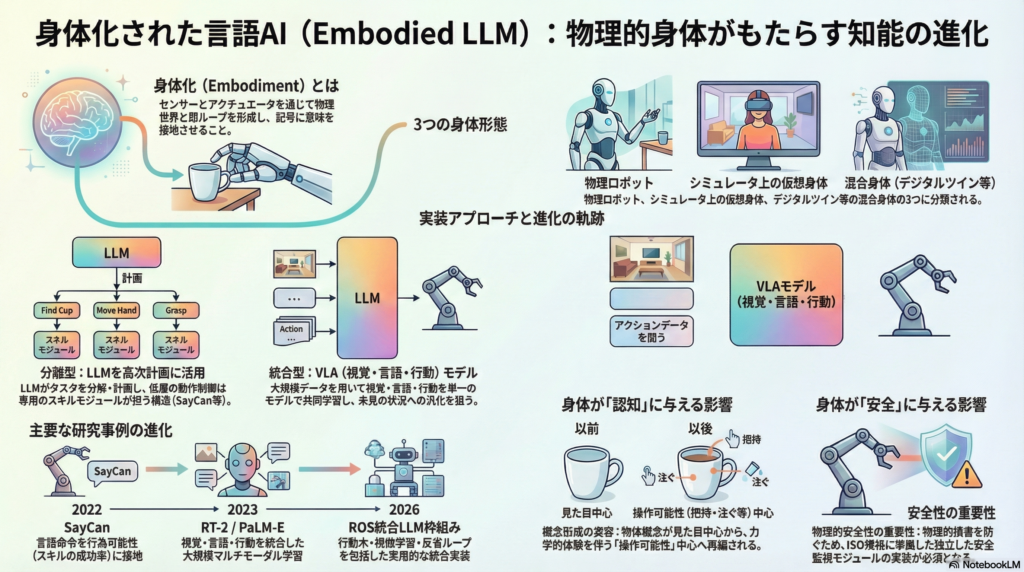
身体化(Embodiment)の定義と3つの分類
身体化とは何か
身体化を「認知を成立させる情報の流れが、身体と環境の相互作用によって制約を受けること」と定義すると、その議論は次の3軸に分解できます。
- どの環境で感覚と行為が起きるか(物理/仮想/混合)
- どの程度ループが閉じているか(観測のみ/能動探索/力制御まで)
- どの種類の身体チャネルを持つか(視覚・触覚・固有感覚・移動など)
これは1990年代に提唱された「象徴接地問題(Symbol Grounding Problem)」に直接応えようとする試みとも言えます。記号を操作するだけでは意味が内在化しない、という問題設定から出発し、知覚・行為のループに意味を「接地(ground)」する必要性が論じられてきました。
3つの実用的分類
① 物理的身体(Physical Embodiment) 実際のロボット(アーム・移動ロボット・ヒューマノイドなど)が対象です。RGB-Dカメラ・力覚センサ・触覚センサ・IMUなどのセンサと、関節駆動・把持機構・移動機構などのアクチュエータが物理世界と閉ループを形成します。
② 仮想身体(Virtual Embodiment) シミュレータ上のエージェントです。センサとアクチュエータは仮想ですが、視覚・行動・状態遷移の因果関係が定義されます。HabitatやAI2-THORのような高品質な仮想環境でのエージェントがこれに当たります。
③ 混合・代理身体(Hybrid/Proxy Embodiment) デジタルツイン、遠隔監督制御、ROSを介した抽象APIなど、身体と制御権が階層化された形態です。現実のロボットをLLMが高次レベルで制御し、低層の動作は別のモジュールが担うアーキテクチャがこれに該当します。
LLMに身体を与える技術的アプローチ
二大アーキテクチャの方向性
身体化LLMの実装アプローチは大きく2つに分かれます。
アプローチ①:LLMを高次計画・コード生成に使い、実行は別モジュールへ
LLMはタスクの分解・計画生成・コード出力・失敗時の反省(Reflection)を担い、低層の動作制御は専用のスキルモジュールや制御器が担います。Google DeepMindのSayCanやCode as Policiesがこの代表例です。
SayCanは、LLMの「次に何をすべきか」という常識的な手順知識と、ロボット側のスキル価値関数(その場で成功しそうかの推定)を組み合わせ、言語命令をロボットの行為可能性へ接地する設計を示しました。「飲み物を持ってきて」という指示を受けたとき、LLMが候補行動を列挙し、ロボットが実行可能かを評価して選択するという仕組みです。
Code as Policiesは、LLMがPythonコードとして動作方策を生成し、ロボットAPIを呼び出しながらフィードバックに応じて修正するアーキテクチャで、複数の実機ロボットでのデモが報告されています。
アプローチ②:視覚・言語・行動を単一モデルで学習するVLA(Vision-Language-Action)型
GoogleのRT-1・RT-2やDeepMindのPaLM-Eがこの方向性を代表します。RT-2はウェブ規模の視覚・言語事前学習をロボット制御へ接続し、未見の物体や状況への一般化を狙っています。PaLM-Eは連続センサ値・画像・言語を単一言語モデルへ直接取り込み、複数のエンボディメントとタスクにまたがる転移学習を実現しようとした「身体化マルチモーダル言語モデル」の先駆けです。
ROSとLLMエージェントの統合(2026年の到達点)
2026年にはNature Machine Intelligenceにおいて、ロボットOS(ROS)へLLMエージェントを接続し、行動木(Behavior Tree)・インラインコード・模倣学習・反省ループを含む包括的な枠組みが報告されています。長期タスクの遂行・再配置・遠隔監督制御などで頑健性と拡張性が確認され、実装一式が公開されました。これは「LLMが考え、ROSが動き、失敗から学ぶ」というサイクルを統合した、現時点での実装水準を示す一例です。
認知的影響の仮説:何がどう変わるのか
LLMに身体を与えることで、「言語モデルが突然人間のように考える」わけではありません。より保守的に言えば、情報の入出力制約が変わることで推論・記憶・注意の最適化目標が変形すると考えるのが適切です。以下、主要な認知領域ごとに仮説を示します。
注意(Attention)の変化
仮説: 身体化により、注意は「言語的に重要な語」よりも「行為の成否に因果的に効く観測」へシフトし、能動的な知覚行動(視点移動・触って確かめるなど)が増える可能性があります。
テキストのみの計画と、視覚・触覚フィードバックを伴う身体化条件を比較すると、観測要求の回数や視点の切り替えパターンに差が生じるかを検証できます。
記憶(Memory)の変化
仮説: 身体化は「エピソード記憶(状況ログ)」と「手続き記憶(スキル)」の分化を促し、RAGやスキルライブラリを介した再利用が増える可能性があります。
VoyagerのようなMinecraft上のLLMエージェントは、スキルライブラリを自律的に蓄積しながら長期探索を行うことで、この方向性を示しています。2025年に報告されたELLMERは、GPT-4とRAGを用いた長期家事タスク(コーヒー作りなど)において、過去の実行事例を検索して計画へ織り込む枠組みを提示しました。
概念形成(Concept Formation)の変化
仮説: 物理フィードバック、特に力覚・接触情報を含む条件では、物体概念が「見た目」中心から「操作可能性(把持・開閉・注ぐなど)」中心へ再編成され、未見物体への汎化が改善する可能性があります。
「注ぐ」「押す」「引く」などの動詞は、視覚情報だけでなく力学的な体験と結びついて初めて意味が完結するという考え方です。この仮説を検証するには、視覚中心タスクと力制御が必須なタスクを同じ語彙で比較し、ゼロショット汎化の差を測定する必要があります。
言語理解・生成の変化
仮説: 身体化は「言語の参照先」を行為系列へ拘束し、曖昧な指示(「あれ」「いい感じに」など)への対処が、質問生成・確認行動・観測行動として外化される可能性があります。
対話型タスクベンチマークであるTEACh(指示者とロボットのチャット付き家事タスク)は、この言語接地・確認・訂正のプロセスを評価できる枠組みとして重要です。幻覚率(存在しない物体や状態を断定する頻度)の変化も、重要な測定指標になります。
メタ認知(Metacognition)の変化
仮説: 実環境の不確実性により、自己評価(「できる・できない」「確信度」)と安全制約が重要になり、異常検知→介入要請→計画修正のループが成立するほど、過信や暴走が減る可能性があります。
安全監視モジュールの有無と、反省(Reflection)プロンプトの有無を交差させた実験で、危険行動の予兆検知率・介入の適時性・失敗後の方略更新が定量化できます。
学習速度への影響
仮説: 身体化は学習を遅くも速くもします。実機データの収集コストや遅延が学習を遅くする要因である一方、「物理制約が教師になる(誤差の情報量が濃い)」こととマルチエンボディメント学習の転移が速くなる要因として働く可能性があります。
Open X-Embodiment(22種のロボットから得た軌跡データの統合)やDROID(多様な実環境での大規模収集)は、転移学習の観点からこの仮説を検証する重要なデータ基盤です。
主要研究の時系列レビュー
理論的基盤(1990〜2008年)
象徴接地問題(Harnad, 1990) は、記号操作だけでは内在的な意味が生まれないことを指摘し、知覚に根ざした表象による接地の必要性を提起しました。行動ベースロボット研究(Brooks, 1991) は、知能を「知覚・行為・環境」ループの増分構築として捉え、表象中心の設計を相対化しました。
その後、人間を対象とした研究では、文章理解が運動・行為表象と相互作用する可能性(ACE効果, Glenberg, 2002)が示されました。ただしこの効果の再現性や効果量には後続研究で議論があり、条件依存性が高いことが確認されています。Grounded Cognition総説(Barsalou, 2008) は、知覚・行為・内受容を基盤とする認知観を行動・神経科学的証拠で体系的に整理しました。
仮想身体と評価基盤の整備(2018〜2022年)
- Habitat(Meta AI, 2019): 高速・モジュラーなシミュレーション環境として、大規模なEmbodied AI研究を可能にしました。
- ALFRED(2020): 視覚観測と高・低レベル言語指示を組み合わせて長期行動列を生成する難タスクのベンチマークです。
- BEHAVIOR(Stanford, 2021): 100種類の家庭活動を論理記述で定義し、多面的な評価指標を提示しました。最先端システムでも困難とされ、計画・言語・操作の統合評価の難しさを示しています。
- TEACh(2022): 指示者と実行者の対話付き家事タスクで、言語接地・確認・訂正を同時に評価できる設計が特徴です。
LLM×ロボット統合の加速(2022〜2026年)
| 研究 | 年 | 主な貢献 |
|---|---|---|
| SayCan | 2022 | 言語の行為可能性への接地設計 |
| Code as Policies | 2022/23 | コード生成による反応的方策の表現 |
| PaLM-E | 2023 | 連続センサ+視覚+言語の共同学習 |
| RT-1/RT-2 | 2022/23 | VLA型の大規模データ学習と汎化 |
| Open X-Embodiment | 2023 | 22ロボットの軌跡統合による転移 |
| ELLMER | 2025 | RAGによる長期家事タスクの遂行 |
| ROS統合LLM枠組み | 2026 | 行動木・模倣・反省の統合実装 |
評価指標とベンチマーク:「成功率」を超えた設計へ
現在の身体化LLM研究の大きな課題は、評価がタスク成功率に偏りすぎている点です。認知機能を媒介変数として測定する設計が不足しています。以下の3層評価を組み合わせることが有効と考えられます。
行動的(Behavioral)指標
タスク成功率・部分達成率・所要時間に加え、外乱への回復率、危険イベント(衝突・過大力)の頻度、試行回数などを測定します。多様な環境での汎化を評価軸に含めることが重要です。
言語的(Linguistic)指標
曖昧指示への確認質問率、訂正後の回復率、計画説明と実行ログの整合性(言っていることとやっていることの一貫性)、幻覚率などが対象です。TEACh型の対話付きタスクはこの評価に適しています。
認知的代理指標(AI内部)
外部メモリの検索ログ、反省(Reflection)の頻度、観測要求のパターン、自己評価の較正(確信度と実際の成功率の一致度)などを統一フォーマットで記録・比較可能にすることが必要です。ROS統合枠組みが示すログ標準化の方向性はここにも活かせます。
倫理・安全性:物理行為の誤りは言語の誤りとは次元が違う
身体化LLMの倫理と安全は、純粋な言語AIとは質的に異なります。テキストの誤りはやり直せますが、ロボットの誤動作は物理的な損害を生む可能性があります。
物理安全の設計原則
協働ロボット・産業用ロボットの安全規格(ISO 10218・ISO/TS 15066・ISO 13482)を前提とした設計が求められます。速度制限・力制限・作業領域制限・非常停止・安全監視モジュールの独立実装は必須要件です。
特にLLMが「計画・コード生成」を担い、低層制御が実行するという多層アーキテクチャでは、事故発生時にどの層に原因があったかを監査可能にするログ設計が不可欠です。
責任の分界とアカウンタビリティ
プロンプトの設計・知識ベースの内容・スキルモジュールの動作・センサの故障・人間側の指示の曖昧さ、これらのどこに責任があるかを追跡できる設計が社会実装の前提になります。NIST AI RMF(AIリスク管理フレームワーク)とロボット固有の安全規格を統合した運用が求められます。
プライバシーとデータガバナンス
家庭内や職場の視覚・音声データは個人情報を含む可能性があります。オンデバイス推論(低ビット量子化技術:LLM.int8、GPTQ、AWQなど)による処理はクラウド依存を減らし、プライバシーリスクを低下させる可能性があります。ただしオンデバイス化すると、端末内での安全な動作をどう保証・監査するかという新たな課題が生じます。
規制環境
EU AI Actは2024年8月1日に発効し、段階的な要求事項の適用が進んでいます。身体化AIは用途によっては高リスク分類に該当する可能性があり、リスク管理・データガバナンス・技術文書・透明性確保を開発プロセスに組み込む設計が求められます。
社会的影響と過信の問題
長期タスクのデモが生む「できる感」は、ユーザーの過信を誘発する可能性があります。異常検知・介入設計・失敗時の停止と説明生成は、社会実装上の必須要件です。人間がロボットを過度に擬人化したり、能力を過大評価したりするリスクは、HRI(人間ロボットインタラクション)設計において継続的に注意が必要です。
まとめ:身体化LLMは何を変え、何を残すか
身体化LLMの研究は、「テキストを操作するだけのAIには何かが足りない」という問いに実験的に応えようとする試みです。SayCan・RT-2・PaLM-EなどのアーキテクチャはLLMの言語能力とロボットの物理能力を接続する有望な方向を示しており、2025〜2026年の研究はその実装水準をさらに引き上げています。
一方で、いくつかの重要な課題が残っています。評価がタスク成功率に偏りすぎており、注意・記憶・概念形成といった認知機能を独立変数として切り出す設計が不足しています。また、身体化の「効果」を主張するには、身体あり/なしで他の条件を揃えた比較実験が必要ですが、現状はモデル規模・データ・スキル・制御器が一緒に変わることが多く、因果同定が難しい状況です。
身体化が「何を変えるか」を正確に知るには、認知機能を媒介変数とした実験設計と、行動・言語・メタ認知の3層評価を組み合わせた新しいベンチマークの整備が鍵になります。
コメント