ドーパミンは「単純なRPE信号」ではない——現代的理解の出発点
報酬学習の神経基盤として、ドーパミンが「報酬予測誤差(Reward Prediction Error; RPE)」を符号化するという仮説は、神経科学の教科書的な知識として定着している。しかし近年の実験的・計算論的な知見の蓄積により、「ドーパミン=RPE」という単純な図式では説明しきれない現象が次々と報告されている。
本記事では、ドーパミン信号の多面的な役割を整理したうえで、期待値学習(TD学習・Q学習・モデルベース学習)との対応関係、さらにPOMDPや階層ベイズを活用した統合的な報酬予測モデルの構築指針までを体系的に解説する。計算神経科学に取り組む研究者や大学院生が実務的に活用できる内容を目指している。
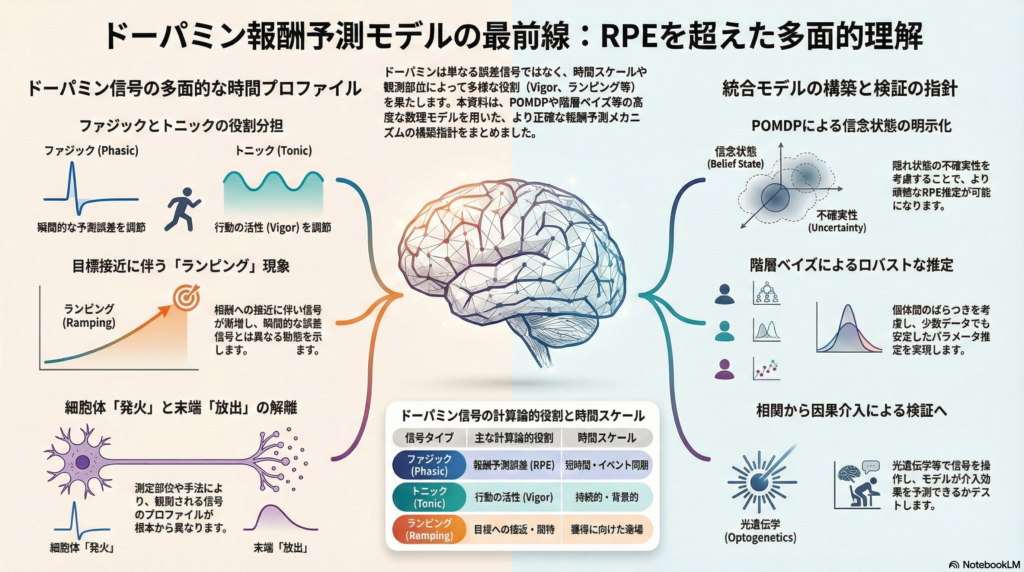
ドーパミン仮説の現代的理解:ファジック・トニック・ランピング
ファジックとトニックの違いとその計算論的意味
ドーパミン信号は大きく「ファジック(短時間・イベント同期的)」と「トニック(背景的・持続的)」という二つの時間スケールで議論される。古典的なRPE仮説は主にファジック成分に着目しており、条件づけ学習における発火パターンの「位相シフト」——学習前は報酬提示時に反応し、学習後は予測手がかり(CS)提示へとシフトする——を計算論的に説明する枠組みとして強力な支持を受けてきた。
最も基本的なRPEは次式で表される。
δ_t = r_t − r̂_tここで r_t は観測された報酬、r̂_t は予測値であり、この差分 δ_t が学習シグナルとして機能するというのがRPE仮説の核心である。
一方でトニック成分については、「平均報酬率(opportunity cost)」を介して行動の活性(vigor:応答速度や努力投入)を調節するという計算論的整理が提案されている。つまり、ドーパミンは「今の予測が外れたか」だけでなく、「どれだけ積極的に行動するか」という側面にも関与している可能性がある。
ランピングと「発火」と「放出」のズレ
さらに重要な問題として、実験で測定しているのが「細胞体の発火(spiking)」なのか「終末での放出(terminal release)」なのかによって、観測される現象が大きく異なりうる点がある。
たとえば、線条体で高速走査サイクリックボルタンメトリー(FSCV)を用いて測定されたドーパミン放出が、ファジックな成分だけでなく**ランピング(目標接近に伴う漸増)**を示す例が報告されている。これはRPE的な「瞬間的誤差信号」とは異なる時間プロファイルを持ち、観測モデルの設計を誤ると解釈が根本から崩れるリスクがある。
近年は遺伝子コード蛍光センサーの普及により、行動中のドーパミン動態をより高速かつ高精度に観測できるようになっており、RPE・ランピング・局所的な投射差を同時に検証する環境が整いつつある。
期待値学習と神経基盤の対応:TD学習からモデルベースまで
TD学習と線条体回路
時間差(Temporal Difference; TD)学習では、状態価値 V(s) を以下のように更新する。
δ_t = r_t + γV(s_{t+1}) − V(s_t)
V(s_t) ← V(s_t) + α δ_tこのTD誤差 δ_t がドーパミンのファジック応答と対応するという整理は、計算神経科学の基礎として広く受け入れられている。線条体の直接路(D1受容体優位)と間接路(D2受容体優位)の回路構造が、ドーパミンの上下動に対する非対称な感受性と対応するという仮説も提案されており、回路レベルでの生物学的足場となっている。
Q学習と行動価値の神経表現
Q学習は、状態‐行動価値 Q(s, a) を直接更新するモデルフリー手法であり、次式で表される。
Q(s_t, a_t) ← Q(s_t, a_t) + α[r_t + γ max_a Q(s_{t+1}, a) − Q(s_t, a_t)]線条体信号やドーパミン信号が価値・誤差変数と相関するという知見は、Q学習変数の脳内対応付けに頻繁に用いられる。ただし、潜在状態の取り違えが生じると「RPEらしさ」が偽陽性・偽陰性になるため、タスク設計と状態推定の質が解釈の信頼性を左右する。
モデルベース学習と前頭皮質の役割
モデルベース学習は、遷移確率 P(s’|s,a) と報酬モデル R(s,a) を学習し、内部モデル上での計画(planning)によって行動価値を計算する。モデルフリーとモデルベースの両要素がヒトの意思決定に共存することが行動・fMRI研究から示されており、線条体BOLD信号が両者の影響を同時に受ける可能性が指摘されている。
眼窩前頭皮質(OFC)が「タスク状態(task state)」を表現する認知地図として機能するという理論も注目されており、部分観測環境における「信念状態(belief state)」の神経基盤としてPOMDP的枠組みと接続している。
POMDP・状態空間モデル・階層ベイズ:数理表現の比較と選び方
POMDPによる「信念状態」の明示的な扱い
実際の神経科学実験では、被験者(あるいは動物)が真の状態を直接観測できない「部分観測」の状況が多い。この問題を正面から扱う枠組みがPOMDP(部分観測マルコフ決定過程)であり、信念状態 b_t(s) = P(s_t = s | o_{1:t}, a_{1:t-1}) を確率分布として逐次更新しながら学習・行動選択を行う。
重要な点は、RPEが「観測された報酬 vs 予測」だけでなく、この隠れ状態推定(belief更新)に依存して変化するという事実である。状態表現を誤って固定してしまうと、見かけ上RPE様の神経信号が出現したり消滅したりする「状態誤同定問題」が生じる。
状態空間モデルと推定アルゴリズムの選択
一般的な状態空間モデル(SSM)は次の形で書ける。
x_{t+1} = f(x_t, u_t) + w_t (状態方程式)
y_t = g(x_t) + v_t (観測方程式)線形ガウス系ではカルマンフィルタが最適推定を与え、非線形・非ガウス系では粒子フィルタ(Sequential Monte Carlo; SMC)が候補となる。実務的には、粒子退化(多様性消失)対策として再サンプリングやRao-Blackwellizationの検討が推奨される。
神経データへの適用では、観測モデルの選択が特に重要である。スパイクデータにはポアソン過程モデル、カルシウムイメージングや蛍光センサーデータには畳み込みモデル、fMRIにはHRFを考慮したGLMが自然な選択となる。
階層ベイズの利点と実装の注意点
階層ベイズは個体間のばらつきを「部分プーリング」により安定的に推定できる手法であり、少数個体でもロバストなパラメータ推定が可能になる。PyMCやStanといったPPLを活用することで、複雑な階層構造を比較的容易に実装できる。
ただし、事前分布の選択やモデルのミスマッチに対して感度が高い点には注意が必要であり、事後予測チェック(posterior predictive check)による検証が不可欠となる。
モデル比較と同定性:実践的な落とし穴と対処法
同定性を壊す三つの典型パターン
計算モデルと神経回帰を組み合わせる研究で頻出する同定性問題は、主に次の三類型に集約される。
第一は説明変数の共線性であり、V_t と δ_t がタスク構造上強く相関して分離できないケースが代表的である。第二は状態表現の誤同定であり、POMDPが適切な状況でMDP前提の回帰子を作ると擬似的なRPE相関が生じる。第三は観測モデルのミスマッチであり、発火と放出、あるいはBOLDの遅延・平滑化を無視した推定は時間的なズレにより結果が歪む。
AIC・BIC・PSIS-LOO:目的に応じた使い分け
モデル比較においてはAIC・BICだけで結論を固定しないことが重要である。研究目的が「メカニズムの説明」にあるのか「予測性能の評価」にあるのかによって、適切な指標が異なる。PSIS-LOOやWAICは汎化性能の評価として実用的であり、ArviZなどのライブラリで実装済みのため積極的に活用したい。
モデル検証の最低限のワークフローとして推奨されるのは、①パラメータ復元(parameter recovery)の確認、②事後予測チェック、③複数指標によるモデル比較の三ステップである。
実験的検証:相関から因果へ
計算モデルの検証において最も説得力があるのは、「相関」ではなく「因果介入」による確認である。動物実験では、光遺伝学的活性化により報酬タイミングに同期したファジック活動を付加・抑制し、学習速度や価値更新への影響を行動指標で測定するアプローチが有効である。
ヒトを対象とした実験では、2段階意思決定課題とfMRIを組み合わせ、ドーパミン作動薬の有無による行動パラメータ変化と線条体BOLD変化の整合性を確認する設計が典型的である。いずれの場合も、モデルが介入効果を事前予測できるかどうかが決定的な検証基準となる。
まとめ:統合モデル構築に向けた要点整理
本記事で取り上げた要点を改めて整理すると、次のように集約できる。
ドーパミン信号はRPE単体ではなく、測定スケール・タスク位相・回路投射によってRPE・不確実性・vigor制御などが混在しており、観測モデルを明示した統合モデルが必要である。期待値学習(TD/Q)の神経対応付けは有用だが、潜在状態の推定が不十分だと解釈が崩れるため、POMDPや状態空間モデルによる「状態の不確実性」の明示的な取り扱いが実務的に有効である。モデル比較はAIC/BICだけで完結させず、パラメータ復元・事後予測チェック・交差検証を組み合わせることで同定性問題と過学習の両方への耐性が高まる。そして何より、実験的検証は相関ではなく因果介入によって計算変数を操作し、神経指標と行動指標のズレをモデルで説明できるかをテストするアプローチが決定的である。
コメント