因果的世界モデルとは何か
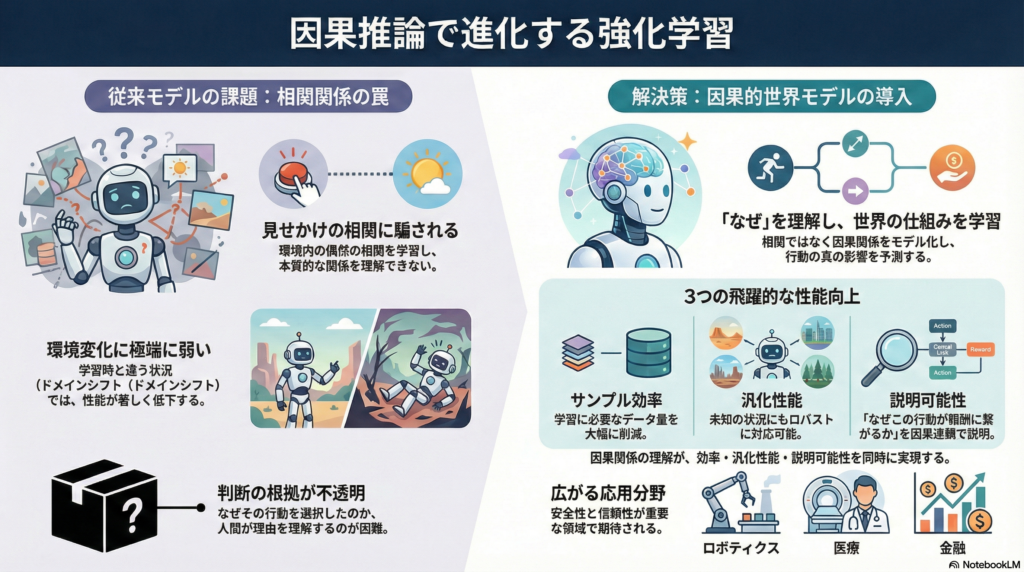
強化学習(RL)における因果的世界モデルは、環境のダイナミクスや報酬構造を単なる相関ではなく因果関係に基づいて表現・学習するモデルです。従来のモデルベース強化学習では観測データから状態遷移を予測しますが、スプリアスな相関まで学習してしまうため、環境が変化した際に性能が著しく低下する傾向がありました。
因果的世界モデルは構造的因果モデル(SCM)や因果グラフを組み込むことで、do演算による介入や反実仮想推論を可能にします。これにより、エージェントは純粋な相関ではなく因果的影響に基づいて学習・判断できるようになり、ドメインシフトに対するロバスト性やサンプル効率の向上が期待されています。
理論的基盤:因果的マルコフ決定過程(C-MDP)
C-MDPの形式化とその意義
Luらが2022年のCLeaRで提案した因果的マルコフ決定過程(C-MDP)は、強化学習に因果構造を導入するための理論的枠組みとして重要な位置を占めています。C-MDPは従来のMDPに状態遷移関数・報酬関数の因果グラフ構造を組み合わせたもので、エージェントが事前の因果知識を活用できる設定を提供します。
この研究で開発されたアルゴリズムC-UCBVIは、因果構造を利用することで探索効率を指数的に改善できることを理論的に証明しました。特筆すべきは、後悔(regret)の上界からアクション空間サイズへの依存が消え、因果グラフ上の少数の親ノード数にのみ依存する点です。これは大規模な行動空間を持つ問題において、因果構造の活用が本質的な効率化をもたらすことを示唆しています。
C-MBPOによる実装アプローチ
Caronらが2025年に提案したC-MBPO(Causal Model-Based Policy Optimization)は、モデルベースRLに因果推論を統合する具体的な枠組みです。この手法はオンラインで収集した軌跡データから局所的なSCMを学習し、状態遷移ダイナミクスと報酬の因果ベイジアンネットワークを構築します。
得られた因果モデルをC-MDPと見立て、エージェントはそのモデル上で介入付きのロールアウト(反実仮想のシミュレーション)を実行します。このアプローチにより「何が原因で報酬に繋がるか」を明確に区別でき、従来モデルが学習してしまう非因果的な相関に惑わされにくくなります。小規模実験では分布シフトに対してロバストなポリシーが得られることが示されており、理論と実践の両面で注目を集めています。
主要な実装手法と実験結果
Causal Bisimulation Modeling(CBM)
Zizhao Wangらが2024年のAAAIで発表したCBMは、複数タスクに渡って再利用可能な因果状態表現を学習する手法です。この手法の核心は、タスクごとに必要最小限の変数だけを保持するタスク固有の最小抽象状態を導出する点にあります。
CBMはまずImplicitモデル(エネルギーベースのモデル)を用いて高精度の因果ダイナミクスモデルを学習し、これを環境内の全タスクで共有します。次にタスクごとの報酬に寄与する変数を因果解析で特定し、そのタスクに不要な変数を省いた抽象状態空間を構築します。この抽象状態は最適価値関数を保存する双模倣(bisimulation)に相当する最小表現となります。
ロボット操作環境やDeepMind Control Suiteでの実験では、CBMの学習した因果ダイナミクスモデルが既存の明示的モデルより正確に真の因果関係と状態抽象を回復しました。得られた抽象状態を用いたエージェントは近似オラクル並みのサンプル効率を達成し、全タスクでベースラインを上回る結果を示しています。
Causal Dynamics Learning(CDL)の成果と限界
Wangらが2022年のNeurIPSで提案したCDLは、タスクに依存しない因果的状態表現の先駆的手法として評価されています。CDLは条件付き相互情報量(CMI)に基づき、各状態変数についてエージェントの行動がその変数に影響を及ぼすかを統計的に判定します。これにより、行動で影響可能な変数全てを抽出し保持する抽象状態を構築できます。
しかしCDLにはいくつかの課題が指摘されています。第一に、全ての制御可能変数を保持するため抽象状態がタスクに対して冗長になりがちで、特定タスクでは不要な要素を含むため効率が低下します。第二に、行動で変えられない要素(行動無関連変数)を無視するため、例えば自動運転タスクで信号機の状態が除外されてしまう可能性があります。さらに次状態を直接予測する明示的モデルを用いているため、接触の有無で遷移が不連続になる物理環境では精度が悪化するケースが報告されています。
これらの欠点を克服するためにCBMではタスク依存の抽象化やImplicitモデルの採用が行われており、CDLは比較対象としての重要な役割を果たしています。
説明可能性を実現するカウザル世界モデル
Yuらが2023年のIJCAIで発表した研究は、因果的世界モデルをエージェントの意思決定の説明可能性(XRL)に活用した点で画期的です。この手法では、事前に因果構造が与えられない状況でエージェント自身が因果世界モデルを学習し、それを用いて行動の長期的影響を説明します。
まず観測履歴から各変数間の因果関係を発見してスパースな因果ダイナミクスモデルを構築し、エージェントの行動がどの環境変数に影響を与え、最終的に報酬につながるかを因果連鎖として可視化します。従来の説明手法(サリエンシーマップなど)は時系列依存の解釈が不得意でしたが、本手法では「行動の数ステップ後に特定の変数が変化し、それが報酬に寄与」といった形で長期効果を因果的に説明できます。
著者らは提案因果モデルの予測精度が十分高く、モデルベースRLにも直接利用できることを実証しました。この研究は、因果的世界モデルが性能向上だけでなくエージェントの決定過程の解釈にも有用であることを示した重要な貢献です。
オフライン強化学習への応用:FOCUS
Zhuらが2025年にFrontiers of Computer Scienceで発表したFOCUS(oFfline mOdel-based RL with CaUSal world models)は、オフライン強化学習の文脈で因果的世界モデルの効果を検討した研究です。
オフラインRLでは行動方策のバイアスによるデータ偏りから生じるスプリアスな相関がモデル学習を妨げる問題があります。Zhuらは環境モデルが観測データ中のポリシーバイアスによる擬似相関ではなく因果影響に焦点を当てるべきとの立場から、理論的に因果構造を取り入れたモデルの方が従来モデルよりも一般化誤差の上限を改善できることを示しました。
実験では、提案手法が与えられたオフラインデータから基礎となる因果構造を高精度に復元でき、得られた因果モデルに基づいて方策学習を行うことで従来のモデルベース手法および他の因果RL手法を上回る性能を達成しました。この研究により、オフライン強化学習における因果的モデルの有用性が理論・実証両面から明らかになっています。
階層的強化学習との融合
Khorasaniらが2025年のICMLで発表した研究は、階層的強化学習(HRL)の分野に因果的世界モデルの考え方を取り入れた先駆的な取り組みです。長期タスクを中間サブゴールに分解するHRLにおいて、サブゴール間の関係を因果グラフで表現し、エージェントがそれを学習する手法を提案しました。
具体的には、まず環境から探索によってサブゴールの因果グラフを発見し、どのサブゴールが他のサブゴールの達成に影響を与えるかをモデル化します。次に、その因果モデルに基づいて最終目標への寄与度が高いサブゴールに優先的に介入(探索)する戦略を採用します。
著者らは特に木構造や一部ランダムグラフの場合に理論的な効率向上を証明し、Minecraftのツール作成タスクなどで提案手法が既存の階層手法よりも学習コスト(必要ステップ数)を大幅に削減できることを示しました。因果的世界モデルが階層的タスク構造の発見と活用にも応用され始めており、複雑なマルチステップタスクを解決する一助となっています。
非因果モデルとの性能比較
因果的世界モデルの導入により、強化学習エージェントの性能向上やサンプル効率の改善、一般化能力の強化が各研究で報告されています。
CBM手法ではタスクに不要な状態情報を取り除くことで近似オラクル並みのサンプル効率を達成し、従来の非因果的手法を大きく上回る学習速度を示しました。Seitzerらの2021年NeurIPSの研究では、エージェントの行動が環境に与える因果影響を状況依存に測定し、影響が大きい局面に焦点を当てて探索させることで、ロボット操作タスクにおけるデータ効率を大幅に高めています。
オフラインRLの領域でも、FOCUSは因果モデルを用いることで未観測状態への一般化性能が向上し、非因果的なモデルでは攻略が難しいデータシフト下でも高い成功率を示しました。これらの比較研究から、因果的世界モデルは従来モデルが捉え損ねていた本質的な構造を学習することで、ベースライン(非因果モデル)よりも効率良くかつロバストにポリシーを学習できることが明らかです。
一方で因果モデル導入によるコストも検討すべき点です。因果構造の学習には追加の探索や統計的検定が必要であり、状態変数が高次元になると計算量が増大します。Dingらが2022年のNeurIPSで提案したGRADER手法では条件独立性検定を用いて因果グラフを学習しますが、高次元変数ではスケーラビリティの課題が残るとされています。
現在の研究動向としては、因果モデルの利点が顕著に現れる状況(大きなドメインシフトや変数間に隠れた構造がある場合など)を理論的・実証的に特定し、「いつ因果推論をRLに用いるべきか」を検討する動きも見られます。
実世界への応用領域
ロボティクスにおける活用
因果的世界モデルはロボティクスにおいて特に有効性を発揮します。Seitzerらの研究ではロボットアームで物体を操作するタスクに因果的探索を導入し、エージェントが「どの状況で何を動かせるか」を理解することで試行回数を削減しています。物理的な操作環境における因果関係の明示的なモデリングは、実世界でのデータ効率向上に直結します。
プランニングと模倣学習への展開
プランニング(計画問題)の分野でも、因果モデルは有望な応用先です。モデルベースのプランニング手法に因果グラフを組み込むことで、「あるアクションを取ればどの要因が変化するか」を明示的にシミュレーションでき、計画の一般化性能が向上します。C-MBPOの研究では因果モデル上でのロールアウトにより、環境ダイナミクスが変化した場合でも適応可能なプランニングが可能になることが示されました。
模倣学習の領域でも因果的視点が取り入れられています。専門家デモンストレーションに隠れた混乱要因(コンファウンダ)がある場合、単純な模倣では失敗しますが、構造的因果モデルを用いて専門家の行動生成プロセスを表現し、介入による効果的な模倣方策の学習が試みられています。一部の研究では前-doorやバック-door調整によって専門家の意図を推定し、模倣方策からスプリアスな相関の影響を取り除く枠組みが提案されています。
安全性クリティカルな領域での可能性
医療・金融などの安全性クリティカルな領域では、因果モデルに基づくRLが決定根拠の説明性や方策の妥当性検証に役立つと期待されています。因果的世界モデルはエージェントの意思決定プロセスを因果連鎖として明示できるため、高リスクな領域での信頼性向上に貢献する可能性があります。
今後の研究課題と展望
スケーラビリティの向上
環境が大規模になると、従来の単一因果モデルでは複雑な動作を捉えきれません。これに対し、2024年のICMLではオブジェクト指向表現を活用し環境をオブジェクト単位に分解して因果モデルを学習する研究が現れました。オブジェクト毎に因果関係を学ぶことで次元の呪いを緩和し、大規模マルチオブジェクト環境でも因果的世界モデルを適用しようとする試みです。
ICLR 2025に向けた研究では、環境内の因果メカニズムが一様でない場合(複数の因果モードが混在する場合)に着目し、エージェントが遭遇した状況に応じて異なる因果モデルを動的に適用する手法(Superposed Causal Models)が提案されています。これは単一の因果グラフでは対処できない多様な状況下でのモデル一般化に向けたステップといえます。
部分観測と潜在変数への対応
観測に現れない潜在要因がダイナミクスに影響する場合、因果モデルの学習と推論は一層難しくなります。今後はPOMDPにおける因果推論や、観測データから潜在因子とその因果構造を同時に同定する因果表現学習の発展が期待されます。さらに、因果モデルと深層学習による高次元表現(画像認識など)を統合する研究も盛んになる可能性があります。
階層的スキル学習との融合
階層型の因果世界モデルや因果スキルライブラリの提唱が始まっています。今後、エージェントが学習過程で獲得した因果知識をライブラリ化し、新たなタスクに迅速に適応する転移学習やメタ学習との連携も重要な研究課題となるでしょう。
評価基準の整備
因果的世界モデルの評価基準も整備が必要です。どの程度正確に因果関係を学習できているか、あるいは因果モデルの導入によって具体的にどのような汎化改善が得られたかを定量化する指標作りが求められます。今後の研究では、単にスコアや報酬で評価するだけでなく、学習した因果グラフの正解率や介入実験による検証など、因果モデルならではの評価方法が取り入れられる可能性があります。
まとめ
強化学習における因果的世界モデルの研究は、理論的な基盤構築から具体的アルゴリズム、応用実証、そして新たな課題への挑戦へと発展しています。C-MDPによる理論的形式化、CBMやFOCUSによる実装手法の確立、階層的RLへの応用など、多方面での成果が報告されています。
因果推論と強化学習の融合は、エージェントの効率・適応性・説明性を飛躍的に高める可能性を秘めています。スプリアスな相関に惑わされず本質的な因果関係を学習することで、サンプル効率の向上、ドメインシフトへのロバスト性、意思決定の説明可能性など、従来手法では困難だった複数の目標を同時に達成できる道筋が見えてきました。
今後はスケーラビリティの向上、部分観測への対応、階層的スキル学習との融合、評価基準の整備など、複数の課題に取り組みながら、安全で汎用的な「因果を理解するエージェント」の実現に向けた研究が加速していくでしょう。各分野の専門知識を横断した学際的アプローチが、この領域のさらなる発展を支えることになります。
コメント