はじめに:なぜ進化と学習を融合させるのか
人工知能研究の最前線で、従来の深層学習とは異なるアプローチが注目を集めています。それが深層学習と進化的アルゴリズムの融合です。この手法は、自律ロボットに単なる高性能な認識や制御能力だけでなく、創造性と適応性という、生物が持つ本質的な知能の特徴を実装しようとする試みです。
深層ニューラルネットワークは勾配ベースの学習により、画像認識や制御タスクで卓越した性能を発揮してきました。しかし、局所最適への陥りやすさ、報酬が疎な環境での学習困難さといった課題も抱えています。一方、進化計算は集団ベースの探索により、これらの制約から自由です。本記事では、両者を融合させることで生まれる新たな可能性について、最新研究の知見を交えながら解説します。
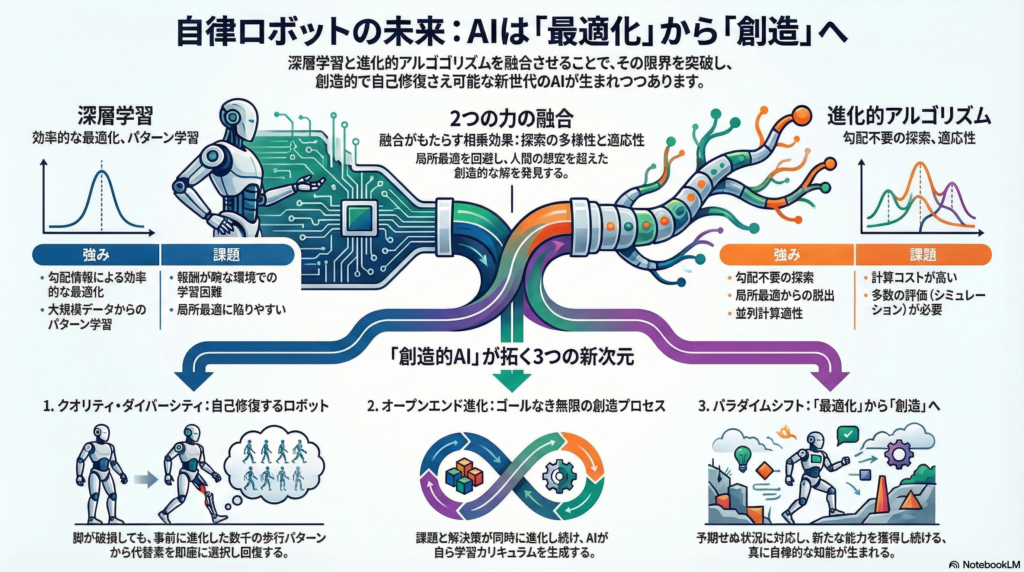
深層学習と進化的アルゴリズム:補完的な二つの力
それぞれの強みと限界
深層学習の強みは、大量のデータから複雑なパターンを学習し、高度な知覚や判断を実現できる点にあります。勾配降下法による効率的な最適化は、明確な誤差関数が定義できるタスクにおいて強力です。
しかし、ロボティクスの現場では以下のような困難に直面します:
- 非微分可能な目的関数
- 環境のノイズや不確実性
- 遅延報酬による学習の不安定性
- 局所最適への収束
進化的アルゴリズムは、これらの問題に対して異なるアプローチを提供します。自然選択のメカニズムを模倣し、解の集団を維持しながら探索を進めるため、勾配情報に依存しません。これにより、ネットワーク構造やハイパーパラメータ、さらには学習規則そのものを最適化対象とすることが可能になります。
融合がもたらす相乗効果
両者の融合により、以下のような相乗効果が期待できます:
探索の多様性:進化的手法は複数の解候補を並行して評価するため、探索空間の広い領域をカバーできます。これは、人間の設計者が想定しなかった創造的な解の発見につながります。
並列計算適性:進化的アルゴリズムは本質的に並列化可能であり、数百のCPUコアを活用した大規模探索が実現できます。実際、進化戦略を用いたヒューマノイド制御の学習が、数分で完了した事例も報告されています。
適応的な問題解決:単一の最適解に固執せず、多様な解を保持することで、環境変化や予期せぬ状況にも柔軟に対応できます。
ニューロエボリューション:脳を進化させる
学習ではなく進化による設計
ニューロエボリューションは、ニューラルネットワークの重み、構造、さらには学習特性を進化的アルゴリズムで最適化する手法です。この発想の背景には、自然界の脳が進化の産物であるという事実があります。
従来のバックプロパゲーションによる学習とは根本的に異なり、ニューロエボリューションは勾配情報を必要としません。そのため、以下のような状況でも有効に機能します:
- 報酬が疎で学習信号が不明瞭な環境
- 評価関数がブラックボックスで微分不可能な場合
- 探索空間に欺瞞的な構造(deceptive landscape)が存在する場合
深層ネットワークへの適用
近年の研究で特筆すべきは、数百万パラメータを持つ深層ネットワークに対しても、進化的手法が有効であることが実証された点です。Atariゲームやヒューマノイドの歩行制御といった複雑なタスクにおいて、遺伝的アルゴリズムが深層強化学習と同等の性能を達成しています。
この結果は、「常に勾配に従うことが最善とは限らない」という重要な示唆を与えます。特に、活性化関数、ネットワークトポロジー、学習アルゴリズムそのものを進化させる研究も登場しており、AutoMLやメタラーニングへの応用可能性が広がっています。
クオリティ・ダイバーシティ:多様性こそが創造性の源
単一解から解の生態系へ
クオリティ・ダイバーシティ(QD)アルゴリズムは、従来の最適化とは異なる哲学に基づいています。単一の最適解を求めるのではなく、多様で高品質な解の集合を探索することを目的とします。
代表的な手法には以下があります:
- Novelty Search:新規性そのものを目的関数とし、未踏の行動空間を探索
- MAP-Elites:行動特徴空間を区画化し、各区画で最良の解を保存
- 行動多様性ベース進化:行動の多様性を明示的に評価基準に組み込む
ロボティクスにおける革新的応用
QDの最も印象的な実証例の一つが、六脚ロボットの自己修復実験です。この研究では、ロボットが脚を損傷した際、事前に進化させた数千の歩容パターンを保存したマップから、現在の状態に適した代替行動を即座に選択し、数分以内に歩行を回復させました。
この実験が革新的なのは、診断や解析を行わず、単に「試して評価する」ことで適応を実現した点です。これは、以下のような利点をもたらします:
- 多様な運動スキルのレパートリー構築
- 未知状況への即応的適応
- 破損や障害時の創造的回復
- 人間の介入なしの自律的問題解決
QDは、自律ロボットが真に「創造的」であるための基盤技術と考えられています。
オープンエンド進化:終わりなき創造のプロセス
固定目標を超えて
オープンエンド進化は、さらに野心的な概念です。明確な最終目標を持たず、新しい課題と解決策を無限に生成し続ける進化プロセスを指します。これは、生物進化が単なる最適化ではなく、分岐的多様化のプロセスであることに着想を得ています。
POET:課題と解法の共進化
代表的な枠組みが**POET(Paired Open-Ended Trailblazer)**です。POETでは、環境(課題)とエージェント(解)が同時に進化します。
プロセスの概要:
- 簡単な課題から開始
- 徐々により困難な環境が自動生成される
- ある環境で進化したエージェントが別の環境に転移される
- 予期せぬ能力が新たな課題解決に貢献
この手法は、以下の重要な示唆を含んでいます:
カリキュラム学習の自動生成:手動で難易度を調整する必要がなく、エージェントの能力に応じた課題が自動的に生成されます。
セレンディピティの活用:偶然的な発見や予期しない能力の転用が、新たなブレークスルーにつながる可能性があります。
生涯学習的ロボティクス:継続的に新しい課題に直面し、適応し続けるロボットの実現に向けた理論基盤となります。
自律エージェントが獲得する能力
深層学習と進化的アルゴリズムの融合により、自律ロボットは以下のような能力を獲得します。
強化された探索能力
- 局所最適の回避:集団ベースの探索により、複数の有望な領域を同時に調査
- 遅延報酬への耐性:長期的な評価指標に基づく進化が可能
- 長期依存関係の捉え方:時間的に離れた行動の因果関係を学習
創造性の発現
進化的手法は、人間の設計者が想定しない戦略や構造を発見する可能性があります。物理的制約や環境特性を逆に「利用する」行動の創発も観察されています。これは、固定的なプログラミングでは実現困難な、真の意味での創造的問題解決です。
適応性とロバスト性
- 環境変化への即応:多様な解のレパートリーから状況に応じて選択
- 破損への耐性:部分的な機能不全があっても代替戦略で対応
- 複数戦略の保持:単一の最適解ではなく、状況依存的な切り替えが可能
特に進化戦略は並列計算に極めて適しており、計算資源を効率的に活用できます。数百のCPUコアを用いた分散学習により、従来は数時間から数日かかっていたヒューマノイド制御の獲得が、わずか数分で完了した報告もあります。
直面する課題と今後の展望
技術的課題
一方で、実用化に向けた課題も存在します:
計算コストとサンプル効率:進化的手法は多数の評価を必要とするため、計算リソースが大きくなる傾向があります。シミュレーション環境での効率化や、学習と進化のハイブリッド設計による改善が研究されています。
リアリティギャップ:シミュレーションで進化させた解が実機で機能しない問題は、ロボティクス全般に共通する課題です。ドメインランダマイゼーションやSim-to-Real転移学習との組み合わせが検討されています。
設計の複雑性:進化と学習をどのように組み合わせるか、どの要素を進化させどの要素を学習させるかといった設計判断は、依然として経験と試行錯誤に依存する部分が大きいです。
概念的課題
オープンエンド性の制御:無限に進化し続けるシステムをどう制御し、評価するかは理論的にも実践的にも未解決の問題です。
安全性と解釈可能性:進化により創発した行動が、なぜそのように機能するのか、安全性は保証されるのかといった問いに答えることは容易ではありません。
「実世界ロボットで進化は現実的か?」という根本的な問いは、研究コミュニティで活発に議論されています。
代表的な研究事例
実証された具体例を見ることで、この分野の現在地が理解できます。
自己修復六脚ロボット:前述の通り、破損後も行動マップから最適歩容を探索し、迅速に回復する能力を実証しました。
深層ニューロエボリューション:Atariゲームやヒューマノイド制御において、遺伝的アルゴリズムが深層強化学習と同等の性能を達成し、「進化も学習と同じくらい有効」という認識を広めました。
POET実験:課題と解法を同時に生成するオープンエンド学習により、従来の固定ベンチマークを超えた汎化能力を示しました。
QD × RL ハイブリッド:クオリティ・ダイバーシティと強化学習を組み合わせ、実ロボットでの高速適応を実証した研究もあります。
まとめ:最適化から創造へのパラダイムシフト
深層学習と進化的アルゴリズムの融合は、AI研究における重要なパラダイムシフトを示しています。それは、以下のような転換です:
- 「最適化」から「創造」へ
- 「固定課題」から「生成される課題」へ
- 「単一知能」から「進化する知能圏」へ
自律ロボットが真に自律的であるためには、単に与えられたタスクを高精度で実行するだけでなく、予期せぬ状況に創造的に対応し、新たな能力を獲得し続ける必要があります。深層学習と進化的アルゴリズムの融合は、そのような創造性・適応性・共進化的知能の理論基盤となる可能性を秘めています。
今後の研究では、計算効率の改善、実機での検証、安全性の保証といった実用的課題に加え、オープンエンド進化の制御や、創発的行動の理解といった根本的な問いにも取り組んでいく必要があります。生物進化が数十億年かけて達成した創造性と適応性を、人工システムでどこまで再現・超越できるか――その挑戦は始まったばかりです。
コメント