AI生成コンテンツが「作者」の概念を揺るがしている理由
生成AIの急速な普及は、私たちが長年当然視してきた「作者」という概念を根底から問い直している。テキスト、画像、音楽、動画――あらゆるメディアにおいて、AIが人間と遜色のないアウトプットを生み出すいま、「誰がその作品を作ったのか」という問いに単純には答えられない状況が常態化しつつある。
この問題は単なる哲学的な議論にとどまらない。著作権保護の範囲、誰が法的責任を負うか、プラットフォームでの表示義務、さらには創作物の信頼性まで、極めて実務的な論点と直結している。
本記事では、フェミニスト科学哲学者ダナ・ハラウェイの「状況に応じた知(situated knowledges)」という概念を理論的な軸として、米国・EU・日本それぞれの法制度と判例、そして産業実務の最新動向を横断しながら、AI時代における作者性の再定義を体系的に整理する。
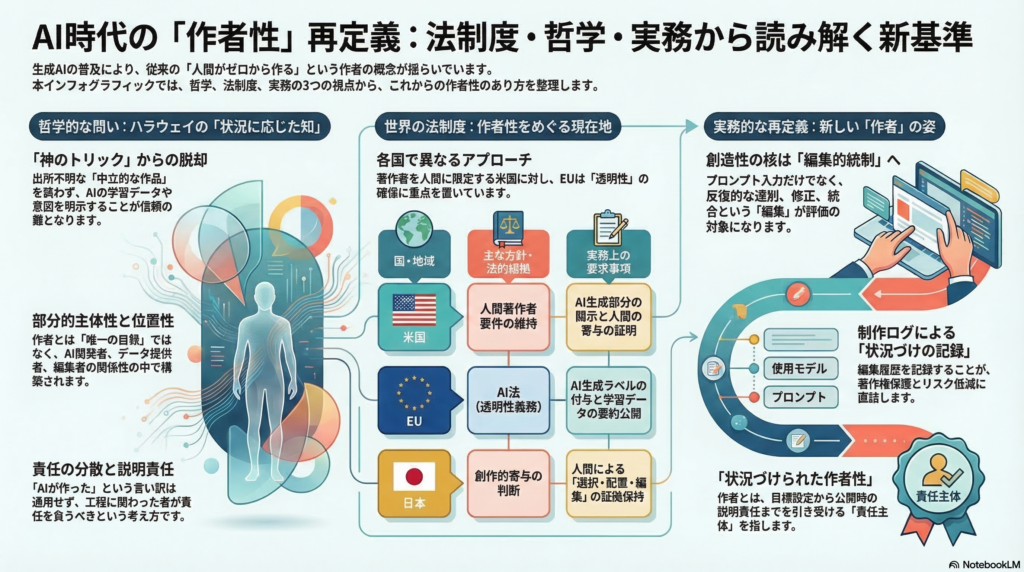
ハラウェイの「状況に応じた知」――AI作者性を読み解く理論装置
「神のトリック」という認識論的罠
ダナ・ハラウェイが1988年に提唱した「状況に応じた知」は、もともと科学哲学における客観性の問い直しから生まれた概念だ。彼女が批判したのは、「どこにもいない場所から、すべてを見通す」という認識のあり方、すなわち「god trick(神のトリック)」である。
この概念がAI生成コンテンツの文脈で鋭い批判的道具になる理由は明快だ。生成AIが出力するコンテンツは、その生成過程――学習データの出所、モデルの設計思想、プロンプトの設計者、編集の判断者――を不可視化したまま、あたかも「どこからでもない中立的な視点」から生まれた作品として流通しやすい。これはまさにハラウェイが批判した構造そのものである。
四つの主要概念と生成AIへの適用
ハラウェイの理論から本稿で重要な概念を四つ取り上げる。
部分的主体性(partial subjectivity) とは、知る主体が「完成された唯一の自我」ではなく、複数の関係性のなかで構築される存在であるという考え方だ。生成AIを使った制作では、プロンプトを打った人間、モデルを開発したチーム、学習データを提供した無数の著作者、編集を加えた担当者など、主体性はもともと分散している。
位置性(positionality) は、「知はつねに特定の場所から生まれる」という原則である。「どの学習データを使い、どんな意図でプロンプトを設計し、誰が最終的な編集判断を下したか」を明示することが、作者性の信頼を支えるという含意につながる。
責任の分散と説明責任(distributed responsibility / accountability) は、工程が分散していても誰も責任を逃れられない、という原則だ。「AIが作った」という言い訳は、ハラウェイ的な意味での「無場所性への逃亡」であり、倫理的・認識論的な失敗に近い。
物質性と技術的媒介 は、学習データ・モデル重み・配信プラットフォームといった具体的な物質的装置を無視できないという観点だ。これらを不可視化することで、あたかも作品が「空から降ってきた」かのように見せることが可能になってしまう。
生成AIの制作プロセスに潜む作者性の争点
多段階の工程に分布する「誰が作ったか」の問い
生成AIによる創作は、単一の行為ではなく多段階のプロセスで成り立つ。大まかには、①学習データの収集・前処理・モデル学習、②プロンプトによる入力と出力の生成、③人間による選択・編集・修正、④公開・流通というフローを経る。
重要なのは、作者性をめぐる争点がこの全工程に分布していることだ。誰がデータを収集したか、どんなフィルタリングを施したか、プロンプトをどう設計したか、複数の生成結果からどの案を選んだか、最終的にどう編集して公開したか――これらすべてが「誰がどの程度作者か」に影響する。
「編集的創造」という新たな評価軸
従来の創作観では、「ゼロから何かを生み出すこと」が創造性の核心とされてきた。しかし生成AIの登場により、プロンプトの設計、反復的な生成と選別、素材の統合と配置、最終的な編集判断といった「編集的創造」の価値が前景化している。
この転換は、著作権実務にも反映されつつある。米国著作権局は、人間が「選択・配置・編集」などの創作的寄与を行った部分については保護の対象になり得るとする運用を積み重ねており、「プロンプトを打っただけ」では人間の十分な統制とは見なされない可能性が示されている。
主要国の法制度と判例――作者性をめぐる制度的現在地
米国:人間著作者要件の維持と実務的適応
米国では、著作権法上の「author(著作者)」を人間に限定するという方向が、裁判所と行政の両面で明確化されている。D.C.巡回控訴裁判所のThaler v. Perlmutter判決では、AIが単独で生成した作品の著作権登録が否定された。さらに連邦最高裁は同事件のcertiorari(上告受理)を拒否し、下級審の判断が実質的に維持される形となった。
米国著作権局は2023年のガイダンスおよび2025年報告書において、AI生成部分を原則として保護対象外とし、登録申請に際してはAI生成部分の開示と人間による寄与の説明を求める運用を定着させている。
法制度の方向性は明快だ。AIを「道具」として使った人間の創作的判断は保護され得るが、AIを「著作者」として認めることはしない。この枠組みのなかで、「どれだけ人間が統制・編集したか」を証明するためのログや制作記録の重要性が急速に高まっている。
EU:透明性義務という「作者性の周辺条件」の制度化
EUは著作権の帰属問題を直接解決するのではなく、「透明性」を社会的統治の軸として制度化する方向を取っている。EU AI Act(Regulation (EU) 2024/1689)の透明性義務条項(Art.50)は、AIとの対話であることの告知、合成コンテンツへの機械可読な標識付与、ディープフェイクの開示などを規定する。
また汎用AIモデル義務(Art.53)では、学習データの要約公開と著作権遵守方針の整備をモデル提供者に求める。これは、作者性を「誰が作ったか」という帰属の問題としてではなく、「いかに透明性を確保し説明責任を果たすか」というプロセスの問題として扱う設計といえる。
日本:著作権法上の整理とガイダンスによる実務対応
日本の著作権法は「著作物=思想又は感情を創作的に表現したもの」「著作者=著作物を創作する者」と定義しており、創作主体を人間の行為に接続する基本的な構造を持つ。AI単独の生成物の著作物性については、人間の「創作的寄与」の程度が判断基準となる方向性が示されている。
学習段階については、著作権法第30条の4が「享受目的でない情報解析等の利用」に一定の権利制限を認める一方、「権利者の利益を不当に害する場合」は例外とされており、その射程については解釈上の不確実性が残る。文化庁は「AIと著作権に関する考え方」としてステークホルダー別のリスク低減チェックリストを公開し、実務的なガイダンスを提供している。
英国の動向:学習と侵害の境界線
英国高等裁判所のGetty Images v Stability AI判決(2025年)では、モデルの学習過程で著作物の複製が生じ得る可能性は認めつつも、学習後のモデル重み自体を「侵害コピー」と見なすという中心的主張を退ける判断が示された。この判決は、「学習=侵害」という構造をどのように立証・制度化するかという難題を改めて浮き彫りにしている。
産業実務の最前線――プラットフォームと来歴技術の動向
プラットフォーム規約による「作者性の社会実装」
著作権法が追いつかない部分を、プラットフォームの利用規約が先行して埋めつつある。YouTubeはリアルな合成・改変コンテンツへのラベル表示を義務づけており、OpenAIの利用規約(2026年1月版)では、入力の責任は利用者が負い、出力は適用法の範囲で利用者に帰属するとされるとともに、AIが作ったコンテンツを「人間が生成した」と偽ることを禁じている。
ただし、プラットフォーム規約が出力の「所有」を利用者に認めても、それが各国著作権法上の「著作権が成立する」ことを直接意味しない点には注意が必要だ。「所有」と「作者性(authorship)」は法的に別の概念であり、この非同一化は実務上の大きな落とし穴になり得る。
Content Credentials(C2PA)と来歴の可視化
C2PA(Coalition for Content Provenance and Authenticity)が推進するContent Credentialsは、コンテンツの来歴情報を機械可読なメタデータとして埋め込む技術標準だ。使用したモデル、生成日時、編集履歴などを「栄養表示ラベル」のように付与する発想は、ハラウェイの位置性の概念を技術インフラとして実装しようとする試みともいえる。
一方、作家団体による「Human Authored(人間執筆)」表示の動きも広がっており、透明性の要求が「AI生成コンテンツの表示」だけでなく、「人間が書いたことの明示」にまで拡張されつつある状況は注目に値する。
「状況づけられた作者性」という新しいフレーム
ハラウェイの概念とここまでの法制度・実務の動向を統合すると、AI时代の作者性は次のように再定義できる可能性がある。
作者=編集的統制と位置開示の主体。生成AIを使った制作において作者性が宿るのは「プロンプトを打った」という事実そのものよりも、目標・文脈の設定、反復生成と選別の判断、修正・統合の編集、そして公開時の説明責任(使用ツール・来歴・意図・責任の所在)といった「位置づけ行為」の集積にある。
責任=工程ごとの分散配置、ただし最終責任は消えない。EU AI Actが提供者と利用者(deployers)双方に透明性義務を課しているように、責任は工程に分散するが、誰も「AIが作ったから知らない」という無責任な立場には逃げられない制度設計が求められる。
評価=美学だけでなく「配置の倫理」を含む。何を学習素材として使い、どの程度の編集統制を加え、どのように開示したか。これらは作品の社会的評価(信頼・正当性)を規定する要素となりつつある。
実務への提言――今すぐ取り組める「状況づけの記録」
短期(〜1年):制作ログと二段階の表示
組織内で取り組める即効策として、「制作ログ」の整備が挙げられる。使用モデル、参照素材、プロンプトの設計方針、生成回数と選別の判断、人間による編集点、公開時のラベルの有無を作品単位で記録・保管する。これは著作権登録時の証拠にもなり、紛争発生時のリスク低減にも直結する。
表示は「合成・改変の開示(誤認防止)」と「編集責任主体の明示(説明責任)」の二段構えにすることが望ましい。前者だけでは不十分であり、誰が最終的な編集判断を下したかを示すことで、社会的信頼を支える基盤となる。
中期(〜3年):来歴標準の制度接続と学習適法性の整備
Content Credentials等の機械可読な来歴標準を、高リスク領域(報道・広告・政治)から優先的に実装することが求められる。また、著作権法第30条の4の射程や、EUの汎用AI義務が求める学習データ透明性への対応は、業界横断の標準契約や団体交渉の枠組みを通じて整備していく必要がある。
長期(〜5年):分散制作に対応した権利・監査制度の構築
モデル提供者・統合者・配信者・利用者の責任分界の明確化、来歴改竄への制裁、削除・訂正手続の整備は、中長期的に立法・行政・業界標準の三者が協調して取り組むべき課題だ。「人間著作者要件」を維持しながらも、編集・統合・監督の「責任主体」をどう指定するか――法人・共同制作・編集責任者などの形で――が、次世代の著作権制度設計の核心となる可能性がある。
まとめ――作者性の再定義は「運用→制度→標準」の順で進む
生成AIの普及が「作者の死」をもたらすかどうかは、まだ誰にも断言できない。しかし少なくとも確かなのは、作者性が「単一の天才が作品を生む」という神話から、「媒介の束を自覚し、位置を引き受け、責任を負う主体」へと再編されつつあるということだ。
法制度はまだ「人間著作者要件」を中核に据えながら、透明性を外部補助線として強める段階にある。ハラウェイが批判した「神のトリック」を回避するために必要なのは、出所・媒介・責任を隠して「自然な創作」を装わないことであり、誤情報や侵害が生じた際に「誰が訂正・補償に応じるか」を事前に設計しておくことだ。
作者性の再定義は、理論より先に「運用→制度→標準」の順で現実化する蓋然性が高い。その流れに対して、企業・クリエイター・法律家・研究者がそれぞれの立場から「位置を引き受ける」ことが、いま求められている。
コメント