なぜ「注意機構」に因果推論を設計として埋め込む必要があるのか
画像・テキスト・動画といった複数のモダリティを扱うTransformerベースのモデルは、近年めざましい性能向上を遂げている。しかしその内部では、注意(attention)機構が学習データに含まれる共変量シフト・回答バイアス・モダリティ間の交絡を「因果関係」として誤認しやすいことが、VQAの分布改変ベンチマークや因果指向のVision-and-Language(V+L)研究で繰り返し指摘されている。
本記事では、Judea PearlのSCM(Structural Causal Model)と注意行列を接続するという設計思想のもと、実装可能な4つの注意機構設計案を提示する。あわせて理論的要件・評価計画・リスクについても整理し、研究の出発点となるような形でまとめる。
マルチモーダル因果推論とは何か——定義と応用領域
問題設定の整理
本記事における「マルチモーダル因果推論」とは、画像・テキスト・動画などの複数モダリティ観測が、潜在の因果変数集合(オブジェクト属性・状態・行為・環境条件など)から生成されるという前提のもとで、以下の3つを推論・予測する問題を指す。
- 因果構造:どの変数がどの変数の直接原因か
- 介入効果:P(Y∣do(A=a)) の推定
- 反実仮想:「もし介入が異なっていたら」という潜在結果の予測
高次元観測から因果表現そのものを学習する課題も含む点が、単純なパターン認識との大きな違いである。
実社会への応用例
この問題設定が重要視される背景には、複数の応用領域が存在する。
VQA・視覚言語推論の頑健化では、訓練データとテスト時の回答事前分布が異なる「分布改変」が起きると、言語バイアスに依存したモデルが著しく性能を落とすことが知られている。動画の因果・反実推論では、CLEVRER・Causal-VidQA・CRiPP-VQAなどのデータセットが整備され、表層的な理解だけでは太刀打ちできないことが示されている。さらに医療・ロボティクス・VLNのバイアス除去といった領域でも、因果的な頑健性の要請は年々高まっている。
標準的な注意機構が因果推論に不向きな理由
相関を集約するが因果方向を保証しない
TransformerのスケールドQKV注意は、Attn(Q,K,V)=softmax(dQK⊤)V
という形で計算される。この式が観測上の相関に強く反応する仕組みである以上、因果方向や識別条件を構造として保証することはできない。
注意重みは「説明」として成立しない場合がある
注意分布をモデルの判断根拠として可視化・解釈しようとする試みは多いが、注意重みが説明として機能しないケースの反例・反証は複数報告されている。注意可視化を因果帰属に直結させる解釈は危険であり、外的な基準(介入結果・真のグラフ・構造整合スコアなど)との照合が必要になる。
マルチモーダルでは交絡が構造的に生じやすい
言語と画像の間には、データ収集・アノテーション設計に起因する偏りが存在する。「言語→位置」のショートカット学習に代表されるように、交絡を因果グラフで捉え直さない限り、注意機構はスプリアス相関を拾い続ける可能性がある。
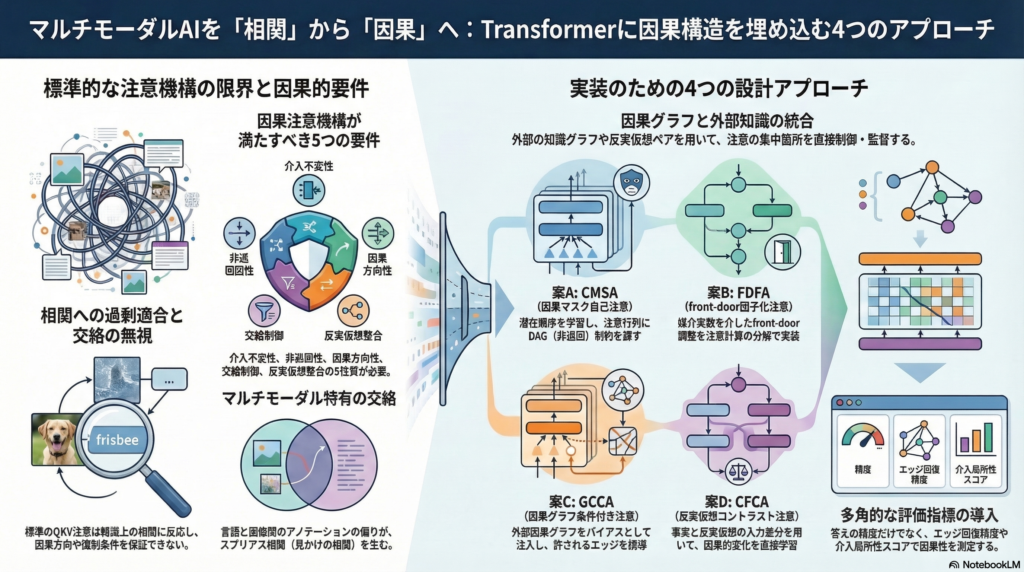
注意機構に課すべき5つの理論的要件
SCMと注意計算を接続する観点から、注意行列が「因果関係を捉える」ために満たすべき性質を以下に整理する。
介入不変性
独立因果メカニズム(ICM)の考え方に基づき、環境が変化しても因果機構が保たれる状況を想定する。注意行列の因果親に関する部分が環境をまたいで安定であることを正則化として組み込む。IRMが提示する「複数環境で不変な予測則を学ぶ」方向性の、注意設計における具体的実装として位置づけられる。
順序性と非巡回性
因果グラフがDAG(有向非巡回グラフ)であるという仮定のもと、NOTEARSが提示した滑らかな非巡回制約h(W)=tr(exp(W⊙W))−d=0
を注意行列に援用し、トポロジカル順序を学習することで非巡回性を保証する設計が考えられる。
因果方向性の表現
相関だけでは方向が定まらないという古典的問題に対し、非対称な方向別射影や順序バイアスを注意スコアへ導入することで、i→j と j→i の同時高スコアを抑制する。
交絡制御と識別可能性(front-door調整)
未観測交絡がある状況でも、媒介変数 M が観測できれば P(y∣do(x))=m∑P(m∣x)x′∑P(y∣x′,m)P(x′)
で識別できる場合がある(front-door公式)。この構造を注意の計算分解として実装する方向が、後述のFDFA設計案につながる。
反実仮想整合
反実入力を与えたとき、注意変化が「介入した原因周辺」に集中し、非介入要素への注意が大きく揺れない「局所性・安定性」を要件化する。
4つの注意機構設計案——理論から実装へ
設計案A:学習可能トポロジカル順序つき因果マスク自己注意(CMSA)
狙いは、注意行列を「原因→結果」方向のみ許すよう制約し、DAG性を担保することである。各トークンに潜在順序スコア si を学習させ、Sinkhorn等の置換近似からソフトマスク Mij=σ(α(si−sj)) を構成する。注意計算に logM をバイアスとして加えることで、因果方向を帰納バイアスとして埋め込む。
追加でNOTEARS風の非巡回正則化を層平均注意 Aˉ に課すオプションも有効である。
注意点:真の因果グラフが部分順序しか持たない場合、全順序仮定が過剰制約となる可能性がある。
設計案B:front-door因子化注意(FDFA)
狙いは、未観測交絡がある状況でもfront-door調整により識別を可能にすることである。モデル内部に「媒介トークン集合」Zm(概念辞書・オブジェクト属性ラベル・構文役割など)を明示的に設け、 y^=m∑IS-ATTgϕ(m∣x)⋅CS-ATT近似(B1b=1∑Bhψ(y∣x(b),m))
の形でfront-door式の構造を模倣する。CATTが提案したCross-sample attentionの考え方を、より一般のTransformerブロックへ再構成した設計である。
注意点:媒介トークンの設計がボトルネックであり、front-door条件が成立しない場面では逆効果になる可能性がある。
設計案C:因果グラフ条件付き注意(GCCA)
狙いは、外部因果グラフ(構文依存・知識グラフ・物理接触グラフ・VLCGなど)を注意バイアスとして注入し、注意が「許される因果エッジ」へ集中するよう誘導することである。グラフ隣接行列 AG からedge-type埋め込みを生成し、 B(ℓ)=λ⋅Embed(AG,edge-type)
として注意バイアス項に加算する。グラフ推定が必要な場合は、別ヘッドで A^G を予測しDAG整合損失を追加する構成もとれる。
注意点:外部グラフが誤っている・粗い場合にはモデルが誤誘導される。グラフの不確実性を確信度としてバイアスへ反映する工夫が必要になる。
設計案D:反実仮想コントラスト注意(CFCA)
狙いは、「注意が因果を捉えているか」を反実介入対(事実・反事実)で直接監督することである。介入生成器 T で反実入力 X~=T(X;do(A=a′)) を生成し、事実・反実の注意行列差 ΔA を介入対象周辺へ集中させる正則化 Lattn=∣ΔA⊙(1−GA)∣1−β∣ΔA⊙GA∣1
を加える(GA は介入箇所近傍マスク)。CALや反実サンプル学習の知見を、マルチモーダルTransformerへ一般化した設計である。
注意点:実データでの高品質な反実生成が難しい。合成SCMで先に原理検証し、実データでは弱教師・限定介入で補う進め方が現実的である。
評価計画——「答え精度」だけに頼らない指標設計
合成データセットの設計方針
明示SCM(因果グラフ+構造方程式)から潜在変数を生成し、画像・動画へのレンダリングとテキスト生成を経て、介入により反実ペアを作るパイプラインを構築する。CLEVR生成器を核として拡張する方法が現実的な出発点となる。
問い設計は以下の3階層で整理する。
- L1(観測):属性・関係質問
- L2(介入):変数を変えたら何が変わるか
- L3(反実):実際はAだったが、もしA’なら?
既存ベンチマークの活用方針
VQA-CPとCLEVRERを最小セットとし、Causal-VidQA・CRiPP-VQA・ACQUIREDを加えた中規模セット、さらにCausalVQA・CausalVLBench・ViLCaRまで含む大規模セットへと段階的に拡張する。
因果指向の評価指標
- エッジ回復精度:真のDAGと推定グラフのF1・SHD(合成データ)
- 反実質問正答率:L3タスクでのTop-1精度
- 介入局所性スコア:介入箇所近傍への注意差分集中度
- 介入一貫性:反実ペアで非介入要素への注意変化が小さいか
主要リスクと限界——設計者が知っておくべき境界
識別不能性の壁:観測データだけでは P(Y∣do(X)) が識別できない構造が存在し、注意設計だけでは突破できない場面がある。追加の介入データや外部知識が必要になる。
注意=因果の過信:注意重みを根拠とした結論には常に注意が必要であり、外的基準(介入結果・真グラフ・VLCG整合)に基づく評価が不可欠である。
反実生成の困難:実世界動画で「正しい反実」を生成することは技術的に難しく、合成環境での検証を先行させることが推奨される。
まとめ——因果注意設計の現在地と次のステップ
本記事では、マルチモーダルTransformerが「見かけの相関」を因果と誤認する問題に対し、SCMの理論を注意機構の設計要件として埋め込む4つのアプローチ(CMSA・FDFA・GCCA・CFCA)を整理した。
各設計案は「標準注意へのモジュール差し替え」として実装可能であり、合成SCMデータと既存ベンチマークの組み合わせで段階的に検証できる構成となっている。「答え精度」だけに依存しない評価指標の設計が、今後の研究の信頼性を左右する重要課題である。
コメント