はじめに:不気味の谷とバーチャルヒューマンの課題
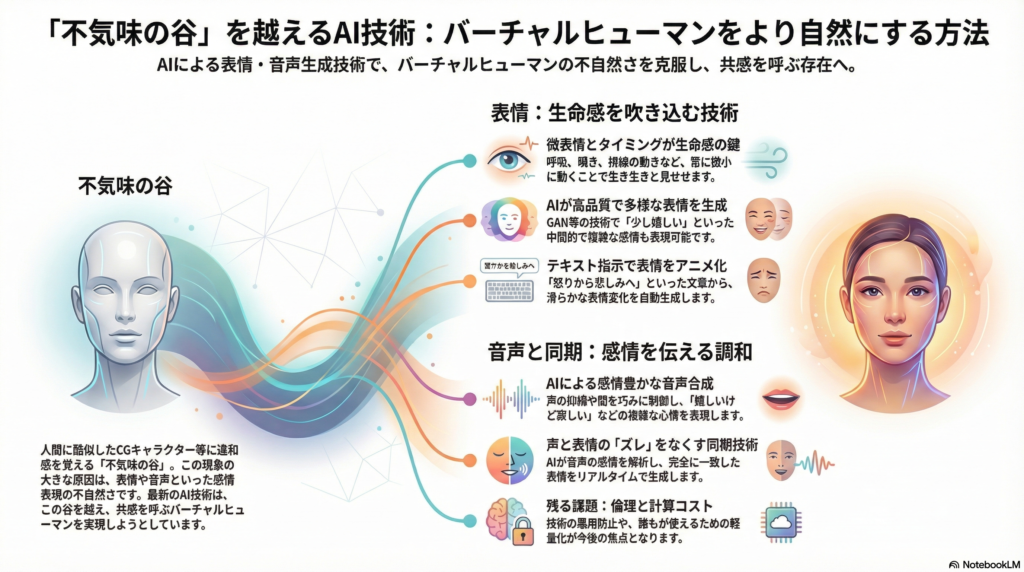
人間に酷似したロボットやCGキャラクターを見たとき、「ほぼ人間だが何かが違う」という違和感を覚える現象が「不気味の谷」です。特に表情や音声といった感情表現の不自然さは、ユーザーの共感や信頼感を大きく損なう要因となります。
近年、ディープラーニング技術の進展により、バーチャルヒューマンの感情表現は飛躍的に向上しています。本記事では、表情生成と音声合成の両面から、不気味の谷を克服し自然で共感的なバーチャルヒューマンを実現するための最新技術動向をレビューします。顔の微妙な表情変化、感情豊かな音声合成、音声と表情の同期技術、そして実装事例と残る課題について詳しく解説していきます。
表情生成技術の最前線
微表情とタイミング制御による生命感の創出
人間らしい表情には、顔筋の細かな動きやタイミングの巧みさが不可欠です。瞬きの頻度、視線の動き、表情の移ろい方といった要素が、キャラクターに生命感をもたらします。
大阪大学の研究チームが開発した波形重畳による動的表情合成は、この課題に対する革新的なアプローチです。この手法では、顔の各パーツの動きを正弦波的なゆらぎとしてモデル化し、リアルタイムに重ね合わせます。「呼吸」「瞬き」「顎の上下」といった動きを個別の波として同時並行的に発生させ、内部のムード(興奮度や眠気)に応じて波の振幅や周波数を変調することで、常にどこかしらが微小に動いている生き生きとした表情を実現します。
従来のプリセットシナリオ切り替え方式では難しかった状況に応じた細やかな表情変化も、内部状態に応じた波形変調で実現できる可能性があります。この技術により、表情の遷移時に生じがちなぎこちなさを抑え、人とロボットの豊かな感情コミュニケーションに繋がると期待されています。
微表情生成の分野でも進展が見られます。深層学習によるモーション転写を用いたアプローチでは、ある顔から捉えた微小な表情の動きを別の顔に転写したり、学習した潜在空間から微表情を合成する試みが報告されています。DMT-FMEGというモデルでは、微表情データセットで訓練した深度モーションリターゲットネットワークを用いて、新たな人物にも微表情の動きを生成できることが示されています。
目や眉の動きの自然さも極めて重要な要素です。研究では、顔の上半分(眉・目元)の表情が乏しいキャラクターは感情が伝わりにくく、不気味さが増すことが示されています。最近の高度なデジタルヒューマンでは、まばたきや視線の逸らし方まで統計的に人間らしくなるよう調整されており、不自然に凝視し続けることを避けることで共感度を高めています。
GANとディープラーニングによる高品質表情合成
GAN(敵対的生成ネットワーク)や拡散モデルの発展により、人間の多様な表情を高品質に合成する研究が進んでいます。StyleGANシリーズは人物顔の高解像度生成で知られますが、その潜在空間を操作することで表情属性を連続的に変化させる応用も可能です。
EmoStyleモデルでは、StyleGAN2の潜在空間上で感情の連続2次元指標(快・不快と覚醒度)に対応する潜在ベクトル操作を行います。これにより、喜び・怒りといった離散的なカテゴリだけでなく、「少し嬉しい」「混乱した驚き」といった中間的な表情も連続値で指定して画像合成できます。高品質かつ本人の個性を保ったまま表情変化を生成できる点が特徴です。
GANによる表情編集の先駆けとしては、入力顔画像に対し表情ラベルや表情強度を与えて別表情に変換するGANimationやStarGANといった研究があります。近年ではこれを動画ベースで行い、元の人物の顔動画に別人の表情や喋り方を転写する顔リインアクトメント技術も進展しています。
これら生成技術は表情のリアルさを高める一方、オリジナルと生成結果の僅かな不整合が不気味さにつながる可能性も指摘されます。最新の研究では、識別器の評価指標に人間の知覚モデルを組み込み、より人が違和感を覚えにくい合成を目指す試みもなされています。
3Dフェイスモデルとテキスト駆動型表情生成
顔の立体的な構造と運動特性を組み込んだ3Dフェイスモデルも重要な役割を果たしています。Epic GamesのMetaHumanやAppleのFaceID用アニ文字技術では、高解像度の顔メッシュとテクスチャに加え、50以上の表情パラメータを用いて人間のあらゆる表情を再現可能です。
注目すべき研究として、テキスト指示で3Dアバターの表情を変化させるフレームワークが提案されています。「この顔を怒りから悲しみに変えて」といった文章を入力すると、開始顔画像から目標表情への滑らかな遷移シーケンスを自動生成します。指示駆動型表情デコンポーザというモジュールでテキスト記述と表情特徴をマルチモーダル学習し、指示に沿った表情変換ベクトルを生成する仕組みです。
この技術により、笑顔から泣き顔への「途中の複雑な心境変化」すらも表情アニメーションで表現できるようになっています。3Dモデルは見る角度や照明が変わっても一貫した形状を保てるため、VR/ARや映像作品など様々な視点でのリアルさ向上に寄与します。
課題は計算コストです。詳細な3D顔メッシュの変形をリアルタイムで行うにはGPUリソースが必要です。近年は軽量化のためにNeRF(Neural Radiance Field)などの新技術を使い、顔のレンダリングと表情変化を高速に行う研究も生まれています。
感情表現豊かな音声合成技術
感情音声合成とプロソディ制御の高度化
音声は表情と並んで感情を伝達する重要なチャネルです。近年のテキスト読み上げ音声合成技術はディープラーニングによって飛躍的に自然性が向上しつつあり、さらに話者の感情表現を制御する研究が活発です。
Emo-DPOは、大規模言語モデルを組み込んだ画期的な手法として注目されています。テキストと目標感情を入力して音声を生成するTTSモデルに、指示に基づくチューニングと好み直接最適化という2段階の学習を行います。これによりモデルは複数感情にまたがる微妙な表現の差異まで捉えられるようになり、客観評価でもプロソディの良さや感情類似度で既存モデルを上回る性能を示しました。
Daisy-TTSというモデルでは、音声の基本周波数やリズムなどのプロソディ情報から感情分離可能な埋め込みを学習し、それを操作することで多様な感情をシミュレートします。主成分分析を用いて韻律埋め込み空間を解析し、喜びと怒りの中間のような複合感情も再現可能としています。知覚実験では、従来の単純な感情指定の手法に比べて感情らしさの知覚や音声の自然さで優れていることが示されました。
声の抑揚や間といったプロソディ要素を巧みに操作することで、単に声色を変えるだけでなく「嬉しいけど寂しい」など複雑な心情を含んだ音声表現も可能になりつつあります。テキストの内容だけでなく文脈上期待される感情まで考慮して音声を合成することで、ユーザーとの対話においてより共感的で説得力のある発話が可能になると期待されています。
音声と視覚表情の同期技術
バーチャルヒューマンが不気味に感じられる一因に、「喋っている内容や声の感情と、顔の表情が噛み合っていない」ことがあります。この声と顔の感情同期を実現するため、マルチモーダルな生成モデルの研究が進んでいます。
AVI-Talkingは音声から直接顔の動きを学習させるのではなく、一度大規模言語モデルに音声内容とその感情を解析させ、そこから「この発話にはこういう表情変化が伴うはず」という視覚的指示を生成します。声の調子や言葉遣いからLLMが「この発話は嬉しそうに話している」という指示を出し、それを受けてディフュージョンモデルベースの顔生成ネットワークが笑顔寄りの口元・目元動作を合成する仕組みです。
このアプローチにより、音声の持つ文脈的な感情ニュアンスを余すところなく顔アニメーションに反映でき、唇の同期精度を保ちつつ豊かな表情変化と一貫した感情状態の3Dトーキングヘッドを生成できる可能性があります。従来手法では音声スペクトルと下顎・唇動作の対応に留まりがちでしたが、LLMを用いることで音声中の感情キューまで考慮できる点が革新的です。
PESTalkは個人差のある感情表現まで考慮した音声駆動型アニメーションを可能にしています。音声特徴抽出に時間ドメインと周波数ドメインの二重のネットワークを用い、声の微妙な高低やヒソヒソ感なども逃さず捉えます。さらに話者ごとの感情スタイルを学習するモジュールを設け、話者の声紋情報からその人固有の表現癖を推定し、アニメーションに反映します。
マルチモーダル統合によって、発話内容・声のトーン・顔の表情・頭や体の動きがすべて調和したバーチャルヒューマン表現が追求されています。これによりユーザーはキャラクターの感情状態を直感的に理解でき、対話への没入感や信頼感が高まります。
ユーザースタディと評価手法
共感度と不気味の谷の定量評価
技術が進歩しても、最終的に「不気味かどうか」「共感できるか」を判断するのは人間ユーザーです。バーチャルヒューマンの感情的リアリズムや共感度を測る指標としては、主観評価と客観評価の双方があります。
主観評価では、アンケートによる印象評価が一般的です。不気味の谷を測る指標として「不気味さ」「親近感」「人間らしさ」等の尺度が用いられてきました。近年はGodspeed Questionnaireの中で、「人間らしさ」「好ましさ」「賢さ」「不気味さ」といった項目が使われることも多いです。
共感度については、ユーザーがキャラクターの感情にどれだけ感情移入できたかを尋ねる質問や、キャラクターへの親近感・信頼感を7段階評価させる方法があります。研究では、ポジティブな感情(喜びなど)を適切に表現したキャラクターはユーザーからの好感度が上がり共感も得やすい一方、ネガティブな感情(怒りや悲しみ)を下手に表現すると不気味さが増して受け入れられにくくなる傾向が示されています。
不気味の谷現象そのものを定量化する試みもあります。一連の顔画像やアニメーションに対して「どのあたりで不気味さのピークが来るか」を統計的に測定し、リアルさとの関係を曲線で示す研究です。こうした分析により、「目の動きだけリアルで口が不自然」など部分的なリアルさの不均衡が不気味さを引き起こす原因になることがわかってきました。
客観評価指標としては、ユーザーの生理反応や行動ログが活用されます。心拍変動や皮膚コンダクタンスの測定によって、不気味なキャラクターを見たときのストレス反応を捉える試みがあります。また視線追跡によってユーザーがキャラクターのどこに注目したかを記録し、自然な場合は目を見ているが不気味に感じると視線を逸らしがち、などの傾向を分析することもあります。
実装事例と不気味の谷克服の工夫
対話エージェントとデジタルアシスタント
顧客対応やコンシェルジュとして画面上に登場する対話エージェントは、近年ますます人間らしい外見・振る舞いを備えるようになっています。Soul Machines社が制作したデジタルヒューマンのAVAは、実写と見紛う精巧な顔立ちで、会話中に眉をわずかに上げたり首をかしげたりといった共感的なボディランゲージを見せるようデザインされています。
公開当初のユーザーの反応は賛否両論で、「確かにリアルだがどこか不気味」「目が魂のない人形のようだ」といった声も聞かれました。これは極めてリアルな外見であっても、完全に人と同じ振る舞いにはまだ到達しておらず、微かなズレが不気味さとして認識された例といえます。徐々に改良を重ねた結果、最新のデジタルヒューマンでは「目の輝き」や「瞬きのタイミング」が自然になり、初期よりも好意的に受け入れられるようになった可能性があります。
対話エージェントの別の方向性として、あえてリアルすぎないデザインで親しみやすさを狙う例もあります。日本のGateboxのようにアニメ風のキャラクターがホログラムで投影される製品では、ユーザーは最初から「これはキャラクターだ」と認識するため不気味の谷を感じにくいと考えられます。スタイライズ(意図的な様式化)されたビジュアルで成功している事例として、バーチャルインフルエンサーやVTuber文化も挙げられます。
メタバースアバターとパーソナライズ
メタバースやVRチャット空間では、自分の分身となるアバターの存在が重要です。Meta(旧Facebook)はVR空間で使える「Meta Avatar」を開発していますが、当初は敢えて脚のないコミカルなデザインで、人間そっくりには作りませんでした。これは不完全な動きや表情しか再現できない現状では、下手にリアルアバターにするよりシンプルなキャラの方が受け入れられるという判断でした。
技術向上に伴い、最近では足や微表情も含めた高度なアバターへ移行しています。Codec Avatarsというフォトリアルなアバターを用いて、VR内で本人と見紛うほどの再現を実現する試みもなされています。限定的な実験では「十分リアルだとむしろ不気味さを感じない」という声もあり、技術が閾値を超えれば不気味の谷を脱する可能性を示唆しています。
VR上のアバターの人間らしさとユーザー体験に関する研究では、「アバターの外見がリアルかどうかは、交流の満足度に有意な影響を与えなかった」という結果が報告されました。それよりもアニメーション(動き)のリアリズムの方がユーザーの楽しさや没入感に大きく寄与しており、どんなに精巧なアバターでも動きがぎこちないと興ざめしてしまう可能性があります。
残る課題と今後の展望
汎用性と適応性の向上
現在の高度な表情・音声生成モデルの多くは、大量のデータと計算資源を投入して特定の条件下で高性能を発揮するものです。しかし人間の表情・音声は千差万別であり、トレーニングしていない状況や人物に対してもうまく機能する汎用性が求められます。
年齢による表現差、文化圏ごとのボディランゲージの違いも考慮する必要があります。真に誰に対しても自然に感じられるバーチャルヒューマンを作るには、より広範なデータと適応技術が不可欠でしょう。
データ収集とプライバシー保護
リアリズムを追求するには高品質な訓練データが必要ですが、その収集にはプライバシーや倫理の問題が伴います。顔画像分野では大規模データセットが相次いで公開停止になる事態も発生しました。
このため研究コミュニティでは、実写データに頼らず合成データでモデルを訓練・評価する動きが活発です。GANで多数の表情画像を生成してデータ不足を補ったり、ゲームエンジンでレンダリングした架空人物の映像で学習させたりするアプローチがあります。今後は、プライバシーに配慮しつつ高品質な感情データを集める方法の確立が求められます。
計算コストとリアルタイム性
ディープラーニングモデルの高性能化に伴い、その計算資源コストも増大しています。一般ユーザーのPCやスマホで同等の体験を提供するには最適化が不可欠です。エッジデバイス上での軽量モデル推論や、クラウド側で処理して映像ストリーミングする仕組み、専用チップの活用などが検討されています。
音声合成分野ではFastSpeech系で大幅な高速化が進み、表情生成分野でもモーション補間を巧みに使って計算量を削減する研究が出てきています。将来的にはリアルタイム・省電力で動く感情表現AIが鍵となるでしょう。
倫理と社会受容性
人間そっくりのバーチャルヒューマンが普及することへの倫理的・社会的課題にも触れておく必要があります。技術的に不気味の谷を乗り越え、「見分けがつかないほど自然な」デジタルヒューマンが登場した場合、ディープフェイクへの悪用や、人間との区別が付かないことによる混乱が懸念されます。
産業界ではデジタルヒューマンであることを明示するガイドライン策定や、深層偽造コンテンツの検知技術開発が進められています。技術は人の幸せに資する形で使われるべきであり、共感的なバーチャルヒューマンも人間の良きパートナーとなるよう設計されねばなりません。
まとめ:不気味の谷を超える未来へ
感情表現に関する最先端技術と人間側の受容性に関する研究は、不気味の谷を克服し自然で共感できるバーチャルヒューマンを実現する上で車の両輪です。ディープラーニングや3Dモデリングの力で表現のリアリズムは飛躍的に向上しましたが、同時に「人は何に違和感を覚えるのか」という心理的理解も深まっています。
今後、技術と心理双方の知見を融合させながら、文化や個人差にも寄り添う形でバーチャルヒューマンが進化していけば、いずれ人々がデジタル存在に対しても心からの共感や信頼を寄せる時代が来る可能性があります。マルチモーダルAIや大規模言語モデルとのさらなる統合、個々のユーザーに適応するパーソナライズドAIの発展により、不気味の谷という概念自体が過去のものになる日も遠くないかもしれません。
コメント