量子セマンティクスが解決する英語の意味理解の課題
英語における文脈依存の意味変化をどう捉えるかは、自然言語処理における根源的な課題です。同じ単語でも周囲の語や文法構造によって意味が変わる現象は、従来の統計的手法では十分に扱えませんでした。こうした背景から、量子力学の形式を取り入れた意味論モデル、すなわち量子セマンティクスが注目を集めています。
本記事では、量子的発想に基づくディストリビューショナル意味論の基本概念から、語義曖昧性解消(WSD)タスクでの具体的成果、他言語への展開可能性まで、最新の研究動向を包括的に紹介します。
DisCoCatモデル:文法と意味の統合による新しいアプローチ
カテゴリ理論に基づく文法と意味の対応付け
量子セマンティクスの代表例として、Coeckeらが2010年に提唱した**Categorical Compositional Distributional Semantics(DisCoCat)**があります。このモデルはカテゴリ理論、特にコンパクト閉圏を用いて文法構造とベクトル空間表現を対応付ける枠組みです。
具体的には、Lambekのプレグループ文法のような文法タイプ体系と、単語のベクトル表現を持つヒルベルト空間を統合します。文の意味は、単語ベクトルをテンソル積や線形写像によって合成することで計算されます。この発想は量子力学の形式に由来しており、単語の意味を量子状態として扱う点が特徴的です。
文脈的語義選択タスクでの実証
Grefenstette & Sadrzadehは2011年、英国国立語料庫(BNC)を用いてDisCoCatモデルの実装を行いました。Mitchell & Lapataが提案した文脈的語義選択タスクにおいて、このモデルは競合手法と同等の精度を達成しました。
さらに注目すべき点は、文の構造が複雑になるほど従来モデルを上回る性能を示したことです。他動詞文への拡張など、文法構造を組み込んだコンポジショナルな意味表現の強みが実証された形となりました。
密度行列表現による曖昧性のモデル化
混合状態としての多義語表現
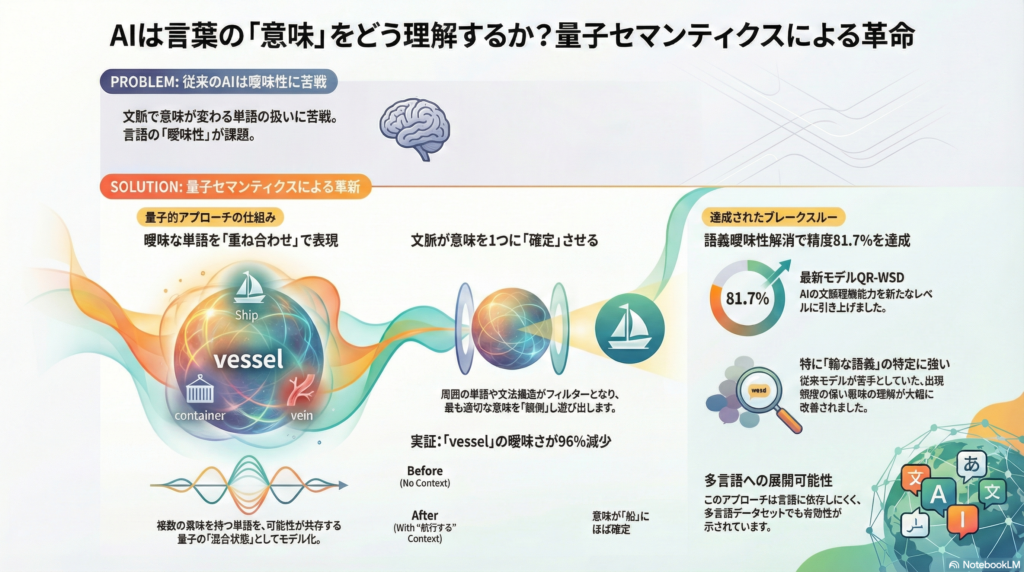
量子セマンティックモデルでは、語義の曖昧性や多義性を量子状態の混合や射影になぞらえて扱います。Piedeleuらは2015年、DisCoCatモデルを発展させ、単語の曖昧な意味を密度行列(密度演算子)による混合状態として表現する枠組みを提示しました。
多義語は、各語義ごとのベクトル状態の統計的混合として表されます。確率重みで各語義への分布を表現することで、単語が複数の意味を同時に保持している状態をモデル化できます。
文脈による曖昧性の解消メカニズム
このモデルで重要なのは、文脈が語義を選別する作用と位置付けられる点です。文章全体の意味を計算する際、各単語の密度行列に対して文法タイプに対応する線形マップ(射影演算子)が適用されます。
Piedeleuらの小規模実験では、「vessel(船/容器など複数の意味を持つ単語)」の密度行列のフォン・ノイマンエントロピーが0.25だったのに対し、「vessel that sails(航行する船)」という文脈を加えると0.01まで低下しました。これはほぼ純粋状態に対応し、適切な文脈の下で単語の曖昧さが解消され、一意な語義に収斂したことを意味します。
語義曖昧性解消タスクでの高精度達成
量子確率論に基づくWSDアルゴリズム
語義曖昧性解消(WSD)は、文脈中の単語がどの意味で使われているかを特定するタスクです。Tamburiniは2019年、量子確率論に基づくWSDアルゴリズムを提案しました。
このモデルではParagraph Vectorにより学習した複素数空間上の単語埋め込みを用い、量子論的な確率計算で文脈に適合する語義を選択します。大規模コーパスでの長時間の追加学習なしに、標準的なWSDベンチマークで当時の最先端性能を達成したと報告されています。
QR-WSDモデルによる81.7%の精度実現
近年では、ニューラルネットワークと量子セマンティクスを組み合わせたハイブリッドモデルが登場し、WSDの精度を大幅に向上させています。Zhangらが2023年にAAAIで発表した「QR-WSD」は、BERTなど大規模事前学習言語モデルと量子インスパイア型の語義表現を組み合わせたモデルです。
このモデルは、特に出現頻度の低い稀な語義(Long-Tail Sense)の表現に焦点を当て、量子的な重ね合わせ状態で複数の語義情報を保持します。標準的なWSD評価フレームワークにおいて、オールワードWSDタスクでF1スコア81.7%という高精度を達成しました。
従来のベースラインや他の量子モデルを上回り、頻出語義よりも稀な語義で相対的に大きな改善を見せた点が特徴的です。
量子干渉効果を導入したモデルの発展
Zhangらは2024年、量子的干渉効果に着目したWSDモデルをさらに提案しました。各単語の意味定義(グロス)を複数のベクトルにより多面的に表現し、それらを量子的重ね合わせ状態として統合します。
干渉項を導入することで、文脈中でその単語が特定の語義に属する確率を計算しつつ、干渉項が信頼度指標として機能するよう工夫されています。このQuantum Interference WSDモデルは英語のオールワードWSDでF1スコア81.6%という高精度を記録し、前述のTamburiniのモデルを大幅に上回る結果となりました。
密度行列モデルによる語義識別の向上
Meyer & Lewisは2020年、コーパスから単語ごとの密度行列を学習するニューラルモデルを3種提案しました。密度行列により単語が複数の語義にまたがる確率分布を内部にエンコードできるため、特に語義の無関係な多義(同形異義語など)に対処しやすい利点があります。
適切な合成手法(文脈と単語密度行列の結合)と組み合わせた場合、ベストモデルは従来のベクトルベースモデルや強力な文レベルエンコーダを上回る結果を示しました。これは密度行列モデルが単語レベルの微妙な意味の違いを保持しつつ文脈で区別する能力に優れることを示唆しています。
多言語展開と日本語への適用可能性
言語横断的な評価の進展
量子セマンティックモデルは理論上、言語固有の制約が少なく他言語へも適用可能な枠組みです。Zhangらの研究では、18言語の語義タグ付けデータセット(XL-WSD)を用いてモデルの汎用性を検証しています。
QR-WSDモデルは構築した長尾語義データセットおよびクロスリンガルデータセット上でも有効性を示し、英語同様の高性能を発揮したと報告されています。これは量子的アプローチが言語固有の知識(例えば英語のWordNetなど)に強く依存せず、言語間で共通の意味表現メカニズムとして機能し得ることを示すものです。
日本語文法への適用の試み
もっとも、他言語への適用には言語ごとの文法体系への対応が必要です。DisCoCatモデルは基本的に各言語の文法をカテゴリ論的タイプ体系で記述することを前提としており、語順や構造の異なる言語ではその調整が求められます。
Ryderは2022年、日本語文法を取り入れた量子カテゴリカル文法の基礎を論じています。英語のSVO型と大きく異なる日本語に対しても、Lambek型のタイプロジックを適切に拡張することでDisCoCatスタイルの意味計算が可能になるとされ、実際に日本語の自他動詞や助詞の振る舞いを図式的に表す試みがなされています。
将来的には、密度行列などの手法で文脈・文法情報を保持しつつ異なる言語間での意味対応(翻訳)を行う可能性も示唆されています。
量子コンピューティングとの連携可能性
高次元演算の効率化への期待
量子セマンティックモデルの多くはベクトルや行列の高次元演算を伴いますが、文法構造が複雑になるにつれて必要なテンソル次元が爆発的に増大する問題があります。
量子コンピュータ上で単語を多粒子量子ビットの状態として符号化し計算することで、古典計算機では扱いにくい巨大な状態空間を効率よく扱える可能性があります。Cambridge Quantum社(現Quantinuum)らのグループは量子回路上でDisCoCatモデルを実装するlambeqというツールキットを開発し、簡単な文の分類タスクなどで量子回路による実験を行っています。
現時点では小規模な回路実証に留まりますが、将来的に量子ハードウェアの発展とともに大規模言語タスクでの量子加速が期待されています。
深層学習モデルとの補完関係
ハイブリッドアプローチの有効性
現在主流のディープラーニング言語モデルとの補完関係も、量子セマンティックモデルの重要な位置づけです。大型言語モデル(LLM)は膨大な知識をエンドツーエンドで学習できますが、その内部表現の解釈性や論理的一貫性に課題もあります。
一方、量子意味論の枠組みは論理的構造と意味の幾何学を統合する明示的なモデルであり、LLMの文脈ベクトルを量子的に解釈し再構成することで、モデルのもつ曖昧な知識を明示化・操作できる可能性があります。
実際、QR-WSDや干渉WSDはBERTの埋め込みと量子的手法を組み合わせることで高性能化しており、「深層学習+量子セマンティクス」のハイブリッドは有望な方向性といえます。
まとめ:量子セマンティクスの今後の展望
量子セマンティックモデルは、文脈による意味変化を形式的に捉える強力な手法として台頭しています。語義曖昧性解消タスクでは81.7%という高精度を実現し、従来手法を大きく上回る成果を示しました。
密度行列による曖昧性のモデル化、カテゴリ理論に基づく文法と意味の統合、ニューラルネットワークとのハイブリッド化など、多様なアプローチが実証されています。多言語対応や論理的推論への応用という新たな展望も開けつつあり、計算言語学と量子計算の交差点で活発な発展が続くと考えられます。
今後の研究では、より複雑な文脈理解タスクへの適用、量子計算資源の実用化、他言語文法への拡張など、さらなる深化が期待されます。量子セマンティクスは、自然言語の意味理解における新たなパラダイムとして、その可能性を広げ続けています。
コメント