量子情報哲学と知識表現論をつなぐ「概念性解釈」とは何か
AIや知識工学の研究領域では、「知識をどのように表現し、どのように更新するか」という問いが長年にわたって探求されてきた。論理表現、オントロジー、ベイジアンネットワーク、分散表現——それぞれが異なる設計哲学を持ち、異なるトレードオフを抱えている。
こうした状況に、量子情報哲学という新たな視点が接続しようとしている。量子状態の解釈・測定問題・エンタングルメント・情報の物理性を中心とする哲学的研究は、「知識とは何か」「観測とは何か」という根本問題を、単なる比喩を超えて形式的に問い直す可能性を秘めている。
特に注目されるのが「概念性解釈(conceptuality interpretation)」と呼ばれる立場だ。量子粒子を物質的粒子としてではなく概念的な存在として捉え、測定装置を「概念内容を受け取るインターフェース」とみなすこの解釈は、量子認知の実験的知見(文脈依存性・順序効果)と接続しながら、知識工学の設計原理に具体的な含意を与えうる。
本記事では、この学際的接点を「状態表現」「非可換更新」「エンタングルメント統合」「不確実性処理」という4つの設計軸から読み解き、知識工学への応用シナリオと評価指標を整理する。
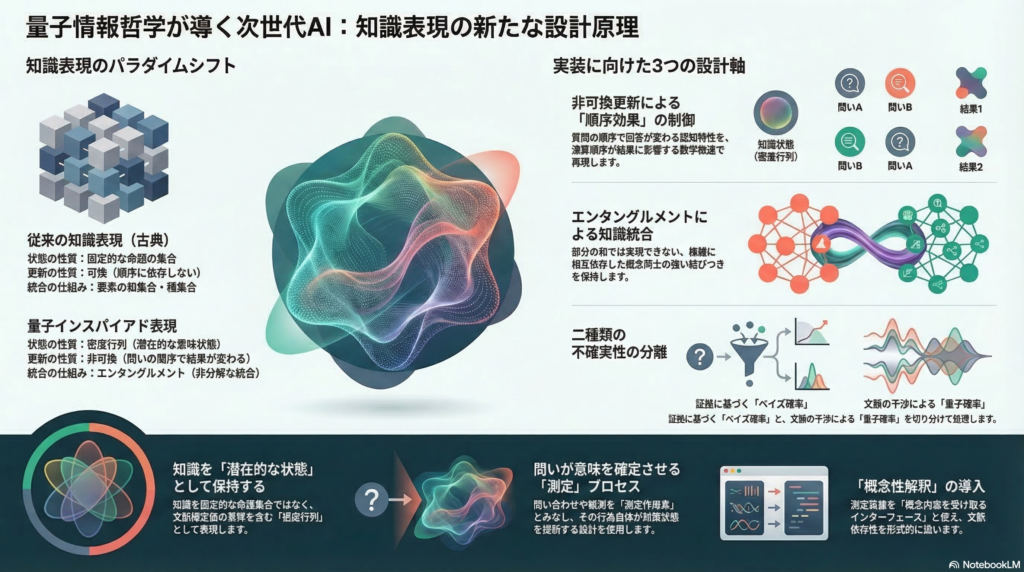
量子情報哲学の主要概念と知識表現への対応
量子状態を「信念・意味状態」として捉える解釈論の系譜
量子力学の解釈には、大きく分けて「実在論的解釈(量子状態は物理的実在を直接記述する)」と「認識論的解釈(量子状態は観測者の信念や情報の整理原理にすぎない)」という対立軸がある。
量子ベイズ主義(QBism)は後者の代表格であり、量子状態を「エージェントが将来の経験を予測するための確率判断の道具」と位置づける。この解釈では、量子状態の更新は客観的な物理プロセスではなく、エージェントの信念改訂として理解される。
知識表現論の文脈に引き寄せると、これは「知識ベースとは命題の固定集合ではなく、エージェントの問い合わせと観測に応じて動的に変化する信念状態である」という設計哲学に親和性が高い。古典的な知識表現が「可能世界の集合」として知識状態を固定的に表現しようとするのに対し、量子インスパイアドな枠組みは「密度行列(ρ)」によって、まだ文脈が確定していない潜在状態を保持する。
数学的には次のように表現される。確率はp(i)=Tr(ρEi)
の形で与えられ、問い合わせ後の状態更新(射影更新)はρ′=Tr(ρP)PρP
となる。これは「問いを発すること自体が状態を変化させる」という測定問題の構造を、知識更新の基本操作として形式化したものだ。
概念性解釈が示す「意味の顕在化」プロセス
概念性解釈における核心的な主張は、量子粒子が物質と「概念的に相互作用する」という点にある。測定装置はただの機械的装置ではなく、「概念内容を受け取るインターフェース」として機能し、相互作用の結果として意味(測定結果)が確定する。
この枠組みを知識工学に移植すると、知識獲得プロセスが次のように再定義される可能性がある。従来、知識獲得は「専門家の知識を命題として形式化する」作業とみなされることが多く、これが「獲得ボトルネック」の源泉となってきた。概念性解釈を踏まえると、知識獲得は「潜在状態(まだ文脈が確定していない意味・意図)の保持」と「問い合わせ・対話・観測による顕在化(更新)」という二層構造として再設計できる。
非可換更新と順序効果:知識工学への形式的含意
古典論理では扱いにくい「問い合わせ順序依存性」
古典的な論理推論では、入力の順序は(単調性が成立する限り)推論結果を変えない。しかし現実の知識更新は、常にそのような単純な性質を持つわけではない。質問の順序によって回答分布が変わる「順序効果」は、心理学・認知科学の実験で広く観測されており、量子認知はこれを量子確率の干渉構造で説明する。
量子測定の非可換性は、次の構造として形式化される。一般に、PAPB=PBPA
であり、問い合わせの順序が更新後の状態を変える。知識工学にこの構造を導入するということは、推論を「命題集合に対する演繹」ではなく「状態に対する作用(更新列)」として設計し直すことを意味する。
ハイブリッド推論エンジンの設計原理
量子インスパイアドな推論エンジンは、次の二層構造として設計できる可能性がある。
第一層は「論理制約」であり、整合性チェックや公理的推論を担う。これは説明可能性が高く、既存の記述論理・OWL推論エンジンとの整合性を持つ。
第二層は「状態更新(非可換)」であり、文脈に応じた意味変化・確率変化を扱う。問い合わせ最適化においては、古典的な情報利得最大化だけでなく、「非可換更新による意味ドリフト」を含む目的関数を設計することが提案される。
以下に最小実装の骨格を示す(Python風擬似コード)。
python
import numpy as np
def born_prob(rho: np.ndarray, E: np.ndarray) -> float:
# p = Tr(rho E)
p = np.trace(rho @ E).real
return max(0.0, min(1.0, p))
def projective_update(rho: np.ndarray, P: np.ndarray) -> np.ndarray:
# rho' = P rho P / Tr(rho P)
denom = np.trace(rho @ P).real
if denom <= 1e-12:
return rho.copy()
rho_post = P @ rho @ P
return rho_post / np.trace(rho_post)
def sequential_query(rho: np.ndarray, projectors: list) -> np.ndarray:
# 非可換性 = 順序依存性として現れる
for P in projectors:
rho = projective_update(rho, P)
return rhoこの実装が示す本質は、推論が状態(ρ)に対する作用(測定作用素の列)として定式化されるという点であり、古典的な真理条件意味論から逸脱した設計が可能になる。
エンタングルメント類比による知識統合:非分解統合の設計と制御
「部分の和では全体が決まらない」知識統合の問題
複数の知識ソースを統合する際、単純な和集合・積集合・マージでは表現できない「相互依存構造」が生じることがある。片方の概念の解釈が、もう一方の解釈を強く拘束するケースがその典型だ。
量子情報では、合成系の状態 ρAB が部分系の直積 ρA⊗ρB に分解できない「エンタングルメント」として、この種の非局所的相関が形式化される。部分トレース(marginalization)を取っても、全体の状態は復元できない。
この数学構造は、知識統合における「非局所的整合制約」——例えば、AとBの属性解釈が相互に依存して確定されるような状況——を表現する抽象モデルとして活用できる可能性がある。
二層運用戦略:エンタングルメント統合状態と説明可能な要約
現実的な知識工学への応用では、次の二層運用が提案される。
保持層:統合状態 ρAB を保持し、強い依存関係を無理に独立モデルへ押し込めずに表現する。
要約層:問い合わせ時に部分トレースに相当する「射影的要約(marginalization)」を適用し、説明可能な断面(古典的事実集合)を生成する。
この設計により、従来手法では「矛盾」として棄却されていた相互依存的な知識が「非互換コンテキスト」として構造化され、統合設計の整理が可能になる可能性がある。ただし、テンソル合成による次元爆発が実用上の主要課題となるため、低ランク近似やテンソルネットワーク法との組み合わせが現実的なアプローチとなる。
量子概念に基づくオントロジー設計:互換性と非互換性の形式化
「同時に確定できない属性群」を設計対象に含めるオントロジー
OWL・記述論理は、形式意味論と推論効率のトレードオフを明示化した標準的なオントロジー言語として定着している。一方で、「一つの概念が複数のコンテキストで異なる顔を持つ」という現象は、従来のオントロジー設計では注釈やサブクラス化で対処されることが多く、推論機構の設計から切り離されがちだった。
概念性解釈の枠組みを応用すると、オントロジー設計に「互換な属性集合(同時に確定できる)」と「非互換な属性集合(コンテキストによって排他的に現れる)」という区別を導入できる可能性がある。量子論理の系譜——古典論理の分配法則が成立しない構造の存在を示した研究——は、この設計思想の形式的根拠を与える。
具体的な設計原理として、コンテキストを「メタレベルの注釈」ではなく「更新作用素」として表現することが提案される。コンテキストごとに異なる観測基底(分類軸)を持つことで、概念定義の衝突を「矛盾」としてではなく「非互換なコンテキスト間の差異」として構造化できる。
評価指標の設計
このアプローチを評価するには、次のような指標の組み合わせが考えられる。
- コンピテンシークエスチョン達成率:設計したオントロジーが期待される推論を正しく返せるか
- 矛盾検出率:従来は矛盾とみなされていたケースが、非互換コンテキストとして正しく分類されるか
- 説明可能性:どのコンテキストでその推論結果が導出されたかを人間が理解できるか
- 推論時間:非可換更新の導入が計算コストに与える影響
不確実性処理の拡張:ベイズ更新に「文脈的不確定性」を加える
量子確率と古典確率の決定的な違い
ベイジアンネットワークをはじめとする確率的グラフィカルモデルは、不確実性推論の標準として広く実用化されている。しかし量子認知や量子IRの研究が示すのは、「独立性仮定」と「すべての事象が同一標本空間上で共存できる」という前提が、現象レベルで破れる(ように見える)領域があるという点だ。
古典確率の混合(「どちらかに決まっているが不明」)と量子の重ね合わせ(「位相を含む振幅の重ね合わせ」)は、合成時に干渉項の有無という形で区別される。この干渉構造こそが、語や条件の提示順依存性・文脈依存性を説明する核心である。
二種類の不確実性を分離して扱う設計
量子インスパイアドな不確実性処理の提案原理は、不確実性を次の二種に分解することだ。
確率的不確実性(ベイズ):証拠に基づく信念更新。ベイジアンネットワーク等で扱う領域。
文脈的不確定性(干渉・非可換更新):文脈の違いや問い合わせ順序によって変化する確率分布。密度行列と測定更新で形式化する領域。
ただし、この二層分離には重要な限界がある。文脈的不確定性を扱うパラメータ(作用素設計・基底選択・位相相当の自由度)は恣意性が入りやすく、実装には評価駆動のアプローチが不可欠だ。
3つの応用シナリオと評価設計
シナリオ1:文脈応答型推論・検索(量子インスパイアドIR)
問い合わせを測定作用素とみなし、文脈に応じて状態(ρ)を更新しながら関連性や回答分布を出力する設計。干渉項を導入することで、語や条件の依存関係・提示順依存の関連性判断をモデル化できる可能性がある。
期待効果:多義性・曖昧性の高い問い合わせでのランキング品質改善や、順序効果を含む状況での一貫した応答の実現。
評価指標:nDCG/MAP/MRR(情報検索)、タスク成功率(対話)、Brier score(確率出力の較正)、順序を変えたときの頑健性(order-robustness指標)。
シナリオ2:非互換コンテキストを形式化するオントロジー設計
概念の属性群を「同時確定可能集合」と「コンテキスト排他的集合」に分け、後者を非可換観測としてモデル化する。これにより、従来注釈化されていた文脈差を推論機構へ組み込む設計が可能になる。
期待効果:概念定義の衝突を「矛盾」ではなく「非互換コンテキスト」として整理し、異種オントロジー統合の構造化。
評価指標:コンピテンシークエスチョン達成率、整合性検査精度、推論時間、説明可能性(どの文脈でその結論か)。
シナリオ3:エンタングルメントを模した複数ソース知識統合
複数ソースの統合を直積的マージではなく「統合状態 ρAB」として保持し、問い合わせ時に部分系へ射影・要約する。
期待効果:強い依存関係を独立モデルへ押し込めずに表現できるため、統合後の「意味漂流」を抑えられる可能性がある。
評価指標:エンティティ整合(alignment)精度、統合後クエリ応答の一貫性、矛盾発生率、要約後の情報損失(再現率・適合率)、計算資源(メモリ・時間)。
なお、上記3シナリオはいずれも「量子ハードウェア前提」ではなく、量子形式(ヒルベルト空間・作用素・更新則)を古典計算機上で実装する「量子インスパイアド」路線であるため、計算速度の優位が保証されるわけではない。主眼は、文脈・順序・非分解統合の表現力を評価可能な形で設計へ落とすことにある。
従来手法との比較:利点と限界を整理する
量子インスパイアドな知識表現が従来手法に対して持つ利点と限界は、以下のように整理できる。
表現力の側面では、従来のオントロジーや論理表現は文脈差を注釈化する傾向があるのに対し、量子概念を取り入れた手法は文脈依存性・順序効果・干渉・非分解統合を第一級の設計対象として扱える。
計算複雑性の側面では、記述論理がプロファイルごとにトレードオフを明示しているのに対し、テンソル合成や作用素更新は次元爆発しやすく、近似・因子化が必須となる。
説明可能性の側面では、論理・因果構造に基づく従来手法が優れている。密度行列・状態ベクトルは直観的な説明が難しいため、「脱コヒーレンス相当の要約」や説明生成のメカニズムを別途設計する必要がある。
実装容易性の側面では、OWL/推論エンジンや成熟ライブラリが豊富な従来手法に対し、量子インスパイアド手法は作用素設計・基底選択・位相相当の自由度など設計難度が高く、評価駆動開発が必須となる。
これらの限界を踏まえると、量子インスパイアドKRは「すべてを置き換える」新パラダイムというよりも、「既存手法が苦手とする文脈依存性・順序効果・非分解統合を補完するモジュール」として位置づけるのが現実的だ。
まとめ:学際的接続がもたらす設計原理の転換可能性
本記事では、量子情報哲学の「概念性解釈」を媒介として、量子形式(密度行列・測定作用素・エンタングルメント)が知識表現論にもたらす設計原理を整理した。
核心的な転換点は、知識状態を「確定命題の集合」から「潜在状態(密度行列)+問い合わせ履歴(非可換更新列)」として設計し直す発想にある。これにより、文脈依存性・順序効果・非分解統合を例外処理としてではなく、推論の基本設計として受け入れる動機が生じる。
ただし、計算複雑性・説明可能性・パラメータ推定の恣意性という限界は無視できない。評価設計を中核に据えた実装駆動のアプローチと、従来手法との適切な組み合わせが、実用的な展開の鍵となるだろう。
コメント