はじめに
自然言語処理と量子計算の融合は、情報検索や文書要約の分野に新たな可能性をもたらしています。特に「量子もつれ」という概念を活用することで、従来の古典的手法では捉えきれなかった文脈の相関性や非線形的な語の関係性を表現できる可能性があります。本記事では、量子もつれを活用した文書要約・検索システムの研究設計について、実装可能な形で体系的に解説します。
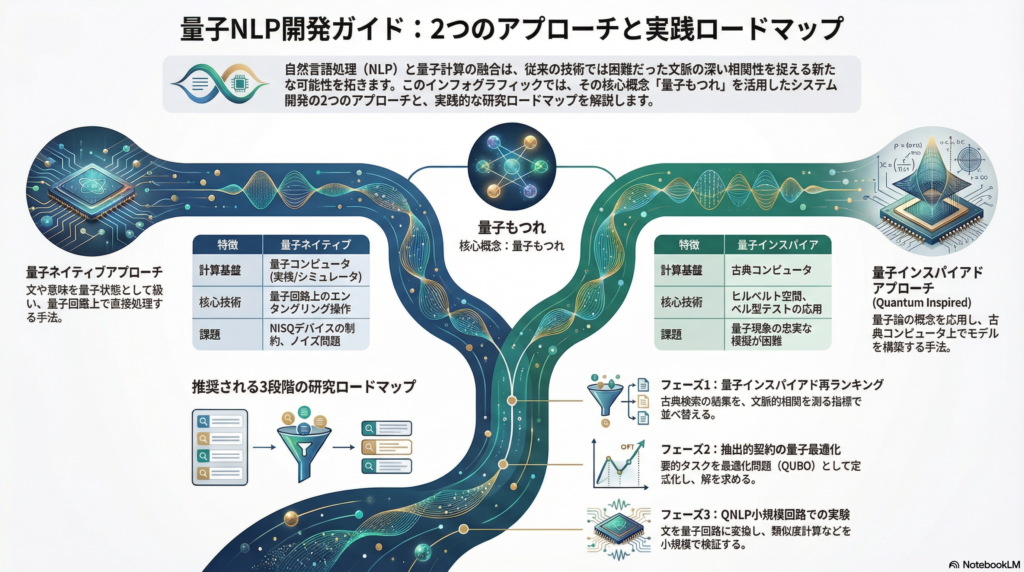
量子もつれ活用の2つの研究路線
路線A:量子ネイティブアプローチ
量子ネイティブアプローチでは、文や意味表現を量子状態として扱い、量子回路上のエンタングリング操作で語の結合や文構造を表現します。QNLP(Quantum Natural Language Processing)として知られるこの分野では、文を量子回路へ写像するツールとしてlambeqなどが開発されています。
量子回路上で文法構造をエンタングリング操作として表現することで、語と語の間の複雑な関係性を量子的に処理できる可能性があります。ただし、現状では小規模データやNISQ(Noisy Intermediate-Scale Quantum)デバイスの制約、古典資源への依存などの課題が指摘されています。
路線B:量子インスパイアドアプローチ
量子インスパイアドアプローチは、実機量子計算を必ずしも必要とせず、ヒルベルト空間や非可換性、ベル型テスト、テンソルネットワークといった量子論的な概念を応用します。もつれを相関の指標として利用し、情報検索や要約のモデルを構築する手法です。
例えば、ベル型テストとHAL(Hyperspace Analog to Language)を組み合わせた検索・ランキング手法では、二語検索における「もつれ」を文脈の非可換性として扱うアプローチが提案されています。この路線は、概念と効果の検証を古典コンピュータ上で行えるため、研究の初期段階として取り組みやすい特徴があります。
推奨される研究ロードマップ
現実的な研究ロードマップとしては、まず量子インスパイアドアプローチで概念と効果を検証し、その後に量子ネイティブアプローチで小規模回路に実装していく順序が推奨されます。
システム仕様の明確化:2つの核心タスク
文書要約・検索システムとして、以下の2つのタスクが中核となります。
タスク1:情報検索(Retrieval)
クエリに対して関連性の高い文書や文章を抽出するタスクです。従来のキーワードマッチングやベクトル類似度に加えて、量子的な相関性を活用したランキング手法の導入が考えられます。
タスク2:文書要約(Summarization)
文書や文章群から要約を生成するタスクです。特に注目すべきは、クエリ駆動型要約(Query-driven Summarization)です。この手法では、検索と要約が同一の目的関数で接続されるため、量子もつれを挿入する余地が大きくなります。
研究設計における入力ポイントの体系化
コーパス入力:文書側の設計変数
文書粒度の定義
文書単位、章・節単位、段落・チャンク単位のいずれで処理するかを明確にする必要があります。検索と要約で粒度が異なる場合は、チャンク分割やスライディング窓などの変換規則を定義します。
文書構造の活用
学術論文の場合、見出し、引用、図表キャプション、参考文献などの構造タグは強力なシグナルとなります。これらの構造情報を要約における中心性の定義にどう反映させるかが重要です。
言語とドメインの選定
日本語のみか日英混在かによって、構文解析の接続方法が変わります。QNLPでは文法構造を量子回路に変換するため、日本語構文解析をどう接続するかが研究の成否を左右する可能性があります。また、学術論文、法務文書、ニュース記事など、ドメインによって評価セットの選択も変わります。
クエリ入力:ユーザ側の設計変数
クエリ形式の設計
キーワード列か自然文質問か、複数意図や否定条件の有無などを定義します。量子回路に落とす場合は、語彙サイズが回路入力の規模に直結するため、クエリ長と語彙制約の仕様が必須となります。
コンテキスト入力の設計
会話履歴(マルチターン)やユーザプロファイル(専門性、目的、立場)を含めるかどうかを決定します。文脈性や好みの形式化は、量子的アプローチとの相性が良い領域です。
量子もつれの定義:研究の核心部分
もつれの対象設定
量子もつれを比喩で終わらせず、計算上の対象として明確に定義することが重要です。対象候補としては以下が挙げられます。
- 語×語のもつれ:共起関係、係り受け関係、照応関係
- 語×文脈窓のもつれ:HALのような局所文脈との相関
- クエリ×文書のもつれ:検索スコアそのものを量子的相関として扱う
- 文×文のもつれ:要約での冗長性制御(類似文の同時選択を避ける)
もつれの生成機構
QNLPでは、文法構造がエンタングリング操作として量子回路に現れます。一方、量子インスパイアドアプローチでは、ベル型パラメータで強い相関を検出してランキングに使う手法や、テンソルネットワークの結合構造でモデル容量としてのもつれを規定する手法があります。
もつれの測定方法
研究として強い主張を行うには、以下のいずれかを採用して測定方法を固定する必要があります。
- 相関の非分離性を示す量子情報由来の指標
- 非可換性・文脈依存性を検出するベル型テスト
- もつれ相当のパターンを古典統計から推定する立て付け
検索モジュールの設計ポイント
インデックス表現の選択
古典ベクトル(BM25や埋め込み)による1次検索と、量子的手法による再ランキングの2段構成が現実的です。最初から量子表現で索引化する方法もありますが、現状では前者のアプローチが堅実です。
ランキング関数の設計
コサイン類似度の置き換えを狙うのか、二語の順序やユーザ嗜好をランキングに組み込むのかを明確にします。ベル型テスト系の手法では、語順や嗜好の影響を扱えることが報告されています。
評価指標の選定
MAP(Mean Average Precision)、nDCG(normalized Discounted Cumulative Gain)、Recall@kなど、どの指標を主張の軸にするかを決定します。
要約モジュールの設計ポイント
要約タイプの選択
抽出的要約(Extractive Summarization)か生成的要約(Abstractive Summarization)かを選択します。研究としては、目的関数と制約を明示できる抽出的要約から始めるのが効果的です。
目的関数の設計
- 中心性:重要文を選択する基準
- 冗長性:類似文の重複を避ける基準
- クエリ整合性:クエリ指向型の場合の適合度
これらを組み合わせた目的関数を設計します。
制約条件の設定
文数固定、総トークン長固定、必須語の包含、引用必須などの制約条件を定義します。
量子最適化への変換
QUBO(Quadratic Unconstrained Binary Optimization)やIsingモデルへの変換仕様を明確化します。制約をペナルティとして目的関数に含めるか、量子回路で制約部分空間に閉じ込めるかを選択します。
実際に、抽出的要約を制約付き最適化として定式化し、制約を保つQAOA(XY mixer)で最大20量子ビット規模の実験を行った研究事例があります。この研究は、要約と量子計算を正面から結びつける重要な参照点となります。
ハードウェア・計算資源の制約条件
量子ネイティブアプローチを採用する場合、以下の制約条件が研究の入力条件として必須となります。
- 使用環境:シミュレータか実機か
- 量子ビット数上限:利用可能な量子ビット数
- 回路深さ上限:ノイズによる制約
- 学習方式:量子回路パラメータ最適化(ハイブリッド方式)の採用可否
NISQデバイスの制約や現状のQNLP研究の限界については、最新のレビュー論文で整理されています。
研究の主張を形成する3つの貢献軸
Claim 1:検索における貢献
文脈性(非可換性)や二語関係の強い相関を活用した再ランキングが、古典的な類似度計算より有効となる条件を明らかにします。ベル型テストとHALを組み合わせたランキング枠組みや、情報検索における量子もつれ導入の議論(QQEなど)が参考になります。
Claim 2:要約における貢献
抽出的要約を制約付き最適化問題として定式化し、量子最適化アルゴリズム(QAOAなど)または量子インスパイアド最適化で解く手法を提案します。制約を量子回路に組み込みつつ実機で実験した先行研究が存在します。
Claim 3:人間との協調・共進化への接続
ユーザのフィードバック(好み、目的、立場)を文脈入力としてモデル化し、検索・要約の振る舞いがどう変化するかを測定します。文脈性、選好、順序効果を扱う量子的枠組み(非可換性・ベル型テストなど)を認知科学的な問いへ橋渡しすることで、研究領域との接続点を作ります。
評価設計とデータセット選定
日本語評価環境の整備
情報検索の評価フレームワークとしては、NTCIRが情報アクセス技術の評価ワークショップとして継続されており、評価設計の参照点となります。日本語要約については、朝日新聞由来のJNC/JAMULなどのコーパス群が自動見出し・自動要約生成用途として整備されています。
クエリ指向型評価の活用
検索と要約を接続するクエリ指向要約データセットとして、英語圏ではQuerySumなどの大規模データセットが提案されています。日本語のクエリ指向マルチ文書要約としては、TSC3を評価データとして活用する事例があります。
実装可能なプロトタイプ案:3段階アプローチ
フェーズ1:量子インスパイアド再ランキング
1段目として通常の検索(BM25や埋め込み検索)を実行し、2段目で二語関係・語順・ユーザ嗜好を入力に含め、ベル型テスト風の指標で文脈的相関をスコア化して再ランキングを行います。
研究課題:どのクエリ条件・どの文書条件で、古典的な類似度計算より優位性が出るかを明らかにします。
フェーズ2:抽出的要約の制約付き最適化
検索上位k件から候補文集合を作成し、中心性・冗長性・クエリ整合性でQUBOを組みます。古典ソルバと量子最適化(XY-QAOAの考え方を参照)で比較実験を行います。
研究課題:制約をどう組み込むと要約品質と制約遵守が両立するかを検証します。
フェーズ3:QNLP小規模回路での意味表現実験
lambeqなどを用いて文を量子回路に変換し、短文分類や類似度を小規模で検証します。QNLPは量子現象(もつれなど)を利用する自然言語処理として位置づけられています。
研究課題:文法構造由来のもつれが、検索や要約のどの部分に寄与するかを明らかにします。
研究設計で最優先すべき3つの決定事項
膨大な設計変数の中から、論文の核として最初に固定すべき3つの決定事項は以下です。
- 要約は抽出的か、クエリ指向か:検索と接続するならクエリ指向型が強力です。
- もつれの対象は何か:語×語、クエリ×文書、文×文など、具体的な対象を定義します。
- 量子ネイティブで行く範囲:再ランキングのみか、要約最適化のみか、両方を含むかを決定します。
まとめ
量子もつれを活用した文書要約・検索システムの研究は、量子ネイティブと量子インスパイアドという2つの路線があり、現実的には後者から始めて前者へ段階的に進むアプローチが有効です。研究を成功させるには、コーパス入力、クエリ入力、もつれの定義、検索・要約モジュールの設計、評価設計など、多岐にわたる入力ポイントを体系的に固定する必要があります。
特に、もつれの対象を明確に定義し、計算可能な形で測定方法を確立することが研究の核心となります。抽出的要約を制約付き最適化問題として定式化し、量子最適化手法を適用する路線や、ベル型テストを用いた再ランキング手法は、実装可能性と新規性を両立させる有力な選択肢です。
本記事で提示した設計変数チェックリストと3段階プロトタイプ案を基に、具体的な研究計画を立案することで、量子計算と自然言語処理の融合という挑戦的なテーマに取り組む道筋が明確になるでしょう。
コメント