記憶の「文脈効果」とは何か:再現が難しい現象の本質
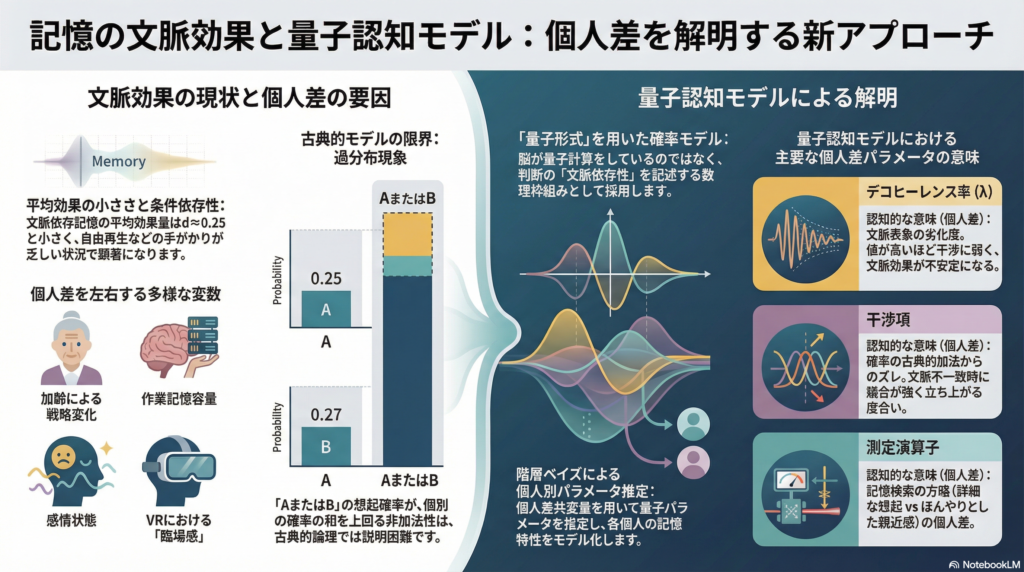
同じ場所で覚えたことは、同じ場所で思い出しやすい——この直感的な現象が「文脈依存記憶(Context-Dependent Memory)」です。1975年にGoddenとBaddeleyが行った水中・陸上での自由再生実験は、その代表例として長く引用されてきました。しかし近年の追試やメタ分析は「平均効果は小さく(効果量 d≈0.25 程度とされる場合も)、条件に強く依存する」という現実も明らかにしています。
本記事では、この文脈効果の個人差がなぜ生まれるのかを、最新の量子認知モデル(Quantum Cognition Model)の観点から体系的に整理します。古典的な心理学の知見から、VR・実世界GPSデータ・階層ベイズ推定まで、現在進行中の研究フロンティアを俯瞰します。
文脈効果の個人差を左右する主な要因
環境・内的文脈と符号化の関係
文脈効果は大きく「環境文脈(場所・背景・匂い・BGMなど)」と「内的状態文脈(気分・薬理状態・運動状態など)」に分かれます。Tulvingが提唱した「符号化特定性(Encoding Specificity)」の原理によれば、有効な検索手がかりは符号化時に何が記銘されたかによって決まります。つまり、同じ環境や状態で学習・再生が行われるほど、記憶成績が高まりやすいとされています。
一方で、この効果が「出やすい条件」と「出にくい条件」が存在することも重要です。Eich(1980)の整理によると、状態依存的な記憶検索の効果は、明示的な検索手がかりが提供される状況ではほぼ消失し、手がかりが乏しい自由再生状況でのみ安定して観察されます。この「手がかり依存性」は、個人差研究においても大きな意味を持ちます。
加齢・認知能力・感情状態の影響
文脈効果の大きさは、参加者の特性によっても変化します。Ward(2017)の研究では、高齢者と若年者の両群で文脈再現が再認を促進したものの、高齢者では項目と文脈の明示的なペア同定(recollection)が弱まり、親近性(familiarity)への依存が高まる傾向が示されています。これは、文脈を「手がかりとして利用する戦略」自体が加齢で変化することを示唆します。
また、作業記憶容量(WMC)や注意特性も、文脈情報の符号化・保持・再活性化のそれぞれに影響を与えます。感情・気分に関しては、Bower(1978)の古典的研究が、複数リスト間の干渉が大きい状況で気分一致記憶が強く現れることを示しています。BGMの調(長調)が再生成績を向上させるという田中(2013)の知見も、内的感情状態が文脈の一部として機能する可能性を支持しています。
VR・実世界データが示す文脈操作の可能性
近年、VR(仮想現実)を使った研究が文脈操作の精度を飛躍的に高めています。Shin(2021)は、火星と水中を模したVR環境を用いた実験で、同一文脈での自由再生成績が有意に高いことを示し、さらに「文脈に統合可能(有用)」と判断された項目でその効果が特に強くなることを報告しました。
Essoe(2022)の研究では、VRで異なる文脈に分けて外国語ペアを学習させると干渉が減り、1週間後の保持率が大幅に向上した(例:92% vs 76%)という結果が得られています。ただし、この恩恵は「VRをどの程度現実的と感じるか(presence:臨場感)」という個人差に依存することも明示されており、VRの有効性が一様でないことに注意が必要です。
一方、Choi(2025)はスマートフォンのGPS位置情報を使った5週間の実世界追跡調査で、低頻度の場所ほど文脈一致利益が強くなること(効果量 d≈0.49)を報告しています。日常生活に根ざしたこの手法は生態学的妥当性が高く、今後の個人差研究への応用が期待されます。
量子認知モデルとは何か:文脈依存性を数理的に表現する
量子確率論の基本的な考え方
量子認知モデル(Quantum Cognition Model)は、脳が物理的に量子計算を行っているという主張ではありません。「確率法則の枠組みとして量子形式(状態・測定・非可換性)を採用する」という方法論的立場です。この形式が認知科学に有用なのは、文脈依存性・順序効果・非加法性といった現象を、自然な形で表現できるためです。
具体的には、記憶の状態を複素数成分を持つベクトル(または密度行列)として表現し、質問や判断を「測定」として定式化します。測定の順序が結果に影響する「非可換性」は、人間の判断が質問の順序によって変わるという経験的事実と対応します。
量子エピソード記憶(QEM)と過分布現象
記憶の領域で特に注目されるのが、再認課題における「過分布(overdistribution)」です。これは、排他的に見えるカテゴリの受容確率の和が、それらを合わせた合成質問の受容確率を上回る現象です。古典的な確率論ではこの現象を自然に説明しにくいのに対し、量子確率モデルでは干渉項によって比較的少数の仮定から導くことができます。
Brainerd(2015)らが提唱した量子エピソード記憶(QEM)では、記憶状態を「逐語(verbatim)」「要旨(gist)」「非一致」などの基底ベクトルの重ね合わせとして定式化します。質問を射影測定として表すことで、過分布のような加法律違反を系統的に説明することが可能になります。さらにTrueblood(2016)は、測定の「非両立性(incompatibility)」を中心に据えた一般化QEM(GQEM)を提案し、階層ベイズによる個人レベルの当てはめの重要性を強調しています。
主要パラメータの意味と個人差への対応
量子認知モデルには、個人差を表現できる複数のパラメータが存在します。
デコヒーレンス率(λ) は、文脈表象の劣化や混合の程度を表します。高いデコヒーレンスは「文脈情報の拡散」や「干渉への脆弱性」に対応する可能性があります。文脈効果が大きい参加者ほどデコヒーレンス率が低い(つまり文脈表象が安定している)という仮説が立てられます。
干渉項(interference term) は、互いに両立しない測定が行われるときに確率が古典的加法からずれる度合いを示します。記憶の過分布はその代表例です。文脈不一致時に競合する文脈が強く立ち上がる参加者では、この干渉項が大きくなる可能性があります。
位相(phase) は、状態ベクトルの成分間の相対的な関係を表し、干渉の符号と大きさを左右します。「文脈間の整合・不整合」「符号化差」などとの対応が仮説として検討されますが、解釈には慎重を要します。
測定演算子の非両立性 は、記憶検索の方略(recollection対familiarity、明示的手がかり利用対自由再生など)が個人によって異なることを表現できます。
個人差と量子パラメータをつなぐ研究設計
二層構造の実験デザイン
文脈効果の個人差と量子モデルパラメータを同時に研究するには、次のような二層構造の実験設計が有効です。
層1(文脈一致効果の行動測定) では、VRや実世界的文脈(場所・背景・匂い・BGM)を用い、学習文脈と想起文脈が一致する条件・一致しない条件を設けます。VRで項目を文脈に統合するカバーストーリー(有用性判断など)を加えると、効果が増大する可能性が示されています。
層2(量子記憶モデルに適合する多質問形式) では、複数のリスト(例:List1・List2・List3)に単語を分配して学習させ、テストで「このリストに出たか?」という個別質問に加え「いずれかのリストに出たか?」という合成質問も行います。この設計により、過分布・非加法性が誘発され、量子パラメータの推定が可能になります。
階層ベイズによる個人別パラメータ推定
個人差を扱う研究では、集計平均への当てはめでは重要な異質性を見落とす可能性があります。そのため、個人別量子パラメータ(θ_i)を階層ベイズで推定し、個人差共変量(年齢・WMC・注意特性・感情状態・VR臨場感など)で予測する「二段モデル」の採用が推奨されます。
数式的には、観測された反応 y_it を密度行列と射影測定を用いてモデル化し、個人差共変量ベクトル x_i によってパラメータ θ_i が系統的に変化すると仮定します。推定にはStan等のHMC/NUTSが実装として適しており、弱情報事前分布(回帰係数にN(0,1)、デコヒーレンスにBeta(2,2)など)を基本とします。
重要な実装上の注意点として、位相や回転角は同値変換で不識別になりやすいため、基底の固定や成分の制約が必須です。また、パラメータ回復シミュレーション(真のパラメータから擬似データを生成し、推定の精度を評価する手続き)は、個人差解析を行う研究では不可欠とされています。
モデル比較と検証指標
量子モデルと古典モデル(信号検出理論・多項プロセスツリー・retrieved-contextモデルなど)の比較には、PSIS-LOO(予測精度の指標)やWAIC(情報量規準)が基本ツールとして推奨されます。Bayes factor(BF)を補助的に用いることで、モデル構造上の仮説比較が可能になります。量子モデルの優位性を主張するには、(a) 文脈一致利益、(b) 過分布などの非加法性、(c) 個人差の構造、を同時に説明できることを示す必要があります。
主要な仮説と期待される研究成果
現在の知見に基づき、検証可能な仮説が複数立てられます。
文脈結合の忠実度仮説では、文脈効果が大きい参加者ほど推定デコヒーレンス率が低く、VR臨場感(presence)が高いほどその関係が強まると予測します。
干渉制御仮説では、多質問形式で干渉が強く現れる参加者ほど、文脈不一致時に競合文脈が立ち上がりやすく、文脈一致利益が大きくなると予測します(ただし明示的手がかりが存在すると効果が縮小するとも予測)。
加齢・親近性仮説では、高齢群では明示的な項目と文脈のペア同定が弱まり、測定演算子(recollection対familiarity)の寄与が年齢によって変化すると予測します。
文脈スキーマ統合仮説では、項目を文脈スキーマに統合できた参加者ほど、初期状態の振幅配置が文脈特異的なサブスペースへの射影が強い方向に寄り、文脈一致利益が項目レベルでも顕著になると予測します。
まとめ:量子認知モデルが開く記憶研究の新地平
本記事では、記憶の文脈効果と個人差を量子認知モデルのパラメータで説明しようとする研究潮流を概観しました。要点を整理すると次のようになります。
文脈依存記憶は「条件依存の小さな効果」として再評価されつつある一方、VR・実世界データ・スキーマ統合などの設計によって効果が増大しうることが示されてきました。量子認知モデルは、過分布(非加法性)や文脈依存の個人差を、デコヒーレンス・干渉・位相・測定演算子といったパラメータで体系的に表現できる枠組みを提供します。階層ベイズと組み合わせることで、個人別のパラメータ推定と個人差指標との対応関係を検証可能な形で実装できます。
この研究アプローチは、教育・訓練の設計(文脈を意図的に分離し、精神的再現で転移を促す学習法の最適化)や、加齢・認知機能低下に応じた記憶支援の個別化など、実務的な応用にもつながる可能性があります。今後の研究では、量子モデルの有意義な予測性能が、古典的代替モデルと厳密に比較検証されることが重要です。
コメント