ニューロン集団コードの「協働」を数字で捉える意義
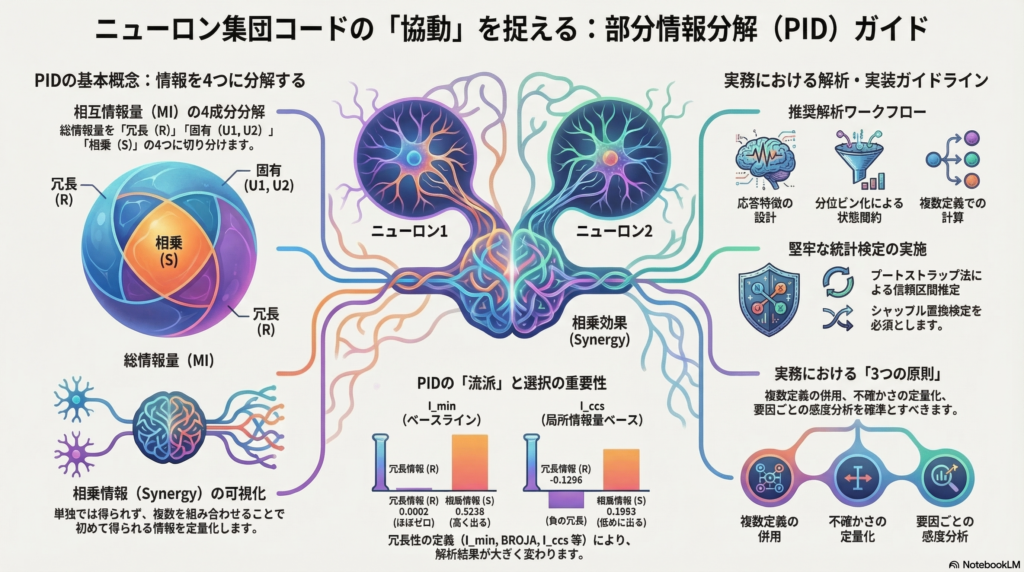
複数のニューロンが同時に活動するとき、その集団は単独ニューロンの足し算を超えた情報処理を行う可能性がある。これを「相乗情報(synergy)」と呼び、神経科学における集団符号研究の核心的テーマの一つだ。しかし、相互情報量(mutual information)だけでは「どの部分が重複していて、どこが協働しているのか」を区別できない。この問題を解決するフレームワークが、**部分情報分解(Partial Information Decomposition; PID)**である。
本記事では、PIDの理論的発展から主要定義の比較、スパイク列への実践的な推定適用、さらに公開NWBデータを用いた実装手順まで、研究実務に直結する形で解説する。
PIDの基本概念:相乗・冗長・固有情報の分解
相互情報量の限界とPIDの登場
2つのソースニューロン(X₁、X₂)から刺激カテゴリ(Y)への相互情報量 I(X₁,X₂;Y) は、集団コードの総情報量を示すが、その内訳を明かさない。Williams & Beer(2010)は「冗長格子(redundancy lattice)」の概念を導入し、以下の分解を提案した。
I(X₁,X₂;Y) = R + U₁ + U₂ + S各成分の意味は次のとおりだ。
- 冗長情報(R):両ニューロンが共通して伝える情報。どちらか一方を見るだけで得られる。
- 固有情報(U₁、U₂):各ニューロンだけが持つ、他方には含まれない情報。
- 相乗情報(S):単独では得られないが、2つを組み合わせることで初めて得られる情報。
この分解は「集団コードが”足し算以上”か否か」を定量的に評価する枠組みを提供する。しかし重要なのは、この式が一意に定まるわけではない点だ。実質的にはRの定義の違いが、PIDの「流派」の違いを生み出す。
PID理論の発展:二大系統の分岐
Williams & Beerの提案以降、冗長性の定義をめぐって研究は大きく二系統に分かれた。
第一系統:意思決定論・最適化ベースのアプローチ
Bertschinger ら(2014)が提案したBROJA系がその代表だ。周辺分布 P(X₁,Y) と P(X₂,Y) を固定した分布集合Δ_P 上で条件付き相互情報量を最小化することにより、固有情報を操作的に定義する。「相関に由来する見かけの相乗・冗長を分離したい」という設計思想が特徴だ。
第二系統:局所情報量(surprisal)の共通変化を用いるアプローチ
Ince(2017)が提案した I_ccs(common change in surprisal)がこれにあたる。各観測タプル (x₁, x₂, y) ごとに局所的な surprisal 変化の符号が一致する部分だけを冗長とみなす。負の冗長(共通ミスインフォメーション)を許容することで、局所的な透明性を高めた定義だ。
主要PID定義の比較:実務選択のガイド
神経データ応用を念頭に置いたとき、どの定義を選ぶべきか。以下に代表的な定義を整理する。
I_min(Williams & Beer)
各刺激値 y ごとの「特異情報(specific information)」の最小値を冗長とみなす。実装が容易で高速、かつ冗長が非負になりやすいため、ベースラインとして広く使われる。ただし「同一の情報」を扱うコピー問題など、直観と合わない事例が指摘されている。
BROJA系(Bertschinger ら)
凸最適化により固有情報を定義し、そこから冗長・相乗を整合的に導出する。理論的厳密さと相関由来のバイアス抑制において優れるが、数値最適化が重く、状態数が増えると計算コストが急増する。小状態空間の離散データに向いている。
I_ccs(Ince)
局所的な surprisal 変化の「共通増減部分」を冗長と定義する。負の冗長を許容することが特徴で、これにより同じ総MIでも相乗情報の推定値が I_min より小さく出るケースがある。後述の合成データデモでも、この定義差が顕著に現れる。
実務における推奨戦略
神経データの実務では、I_min をベースラインとして算出した後、I_ccs またはBROJA系を第2定義として併用し、定義依存性を頑健性チェックとして報告するのが現実的だ。synergy が大きいからといって「高次特徴を符号化している」と短絡せず、(i) 応答特徴の設計と (ii) PID定義の哲学が synergy の意味を規定することを常に意識したい。
スパイク列へのPID推定:有限サンプル問題との戦い
情報量推定のバイアス問題
PIDの実計算は最終的に確率分布推定に帰着する。離散化した場合のプラグイン推定(経験分布から直接エントロピーを計算)は、サンプル不足のとき大きなバイアスを生じることが古くから知られている(Strong ら, 1998)。スパイク列への情報量推定では「状態空間に比べ試行数が不足していると推定が壊れる」という問題が常に付きまとう。
推定法の選択肢
プラグイン推定 + Miller–Madow 補正は最も実装が容易で、適度なアンダーサンプリングへの保険として有効だ。一方、観測されない状態が多い強アンダーサンプリング下では、NSB(Nemenman–Shafee–Bialek)ベイズ推定の方が適切な推定を与える可能性がある。ただし計算コストが高い。
連続応答(LFPの特徴量、連続発火率、潜在表現など)には、ビニング依存のないkNN情報量推定(KSG推定)が標準的な選択肢だ。高次元化に伴う分散増大には注意が必要で、次元削減・正則化を組み合わせることが推奨される。
推奨ワークフロー:2ニューロン × 刺激カテゴリの最小単位
実務向けの標準的なPID解析フローを示す。
- 研究設計の固定:ターゲット Y(刺激カテゴリ、行動選択など)をNWBのtrial設計に整合させる。
- 応答特徴の設計:スパイク列なら「刺激後200ms〜1200msの窓内スパイク数」などを設計する。既存論文(例:Chandravadia ら, 2020)の窓設計を踏襲すると比較が容易だ。
- 状態簡約(離散化):カウントを0〜5にクリップ、または分位ビン化し、joint状態数 |X₁||X₂||Y| を抑える。次元の呪いへの防御策として必須の工程だ。
- PID定義を最低2つで計算:I_min をベースライン、I_ccs または BROJA 系を対照として算出する。
- 不確かさ推定:試行単位のブートストラップで信頼区間を推定し、シャッフル置換検定(帰無仮説: synergy=0)を実施する。
- 感度分析:窓幅・離散化・推定器・PID定義の各要因に対するsynergyの変化を報告する。
公開データセット適用:NWBデータでのPID実装ブループリント
DANDIデータセット(dandiset 000004)の選定理由
DANDI(dandiset 000004)は、人MTL(内側側頭葉)単一ニューロン活動を記録したNWB形式の公開データであり、Chandravadia ら(Scientific Data, 2020)に詳細が記述されている。trial情報・刺激情報・units.spike_times が同一NWBファイルに統合されており、PID解析のパイプライン構築に適している。
視覚カテゴリ(5カテゴリ)に対する発火率比較・ブートストラップ検定手順も論文に示されており、「刺激後200msから1秒窓」というカテゴリ応答検定の窓設計をPIDの特徴設計にそのまま再利用できる点が魅力だ。
Pythonによる実装手順(概要)
python
# ステップ1:NWBファイルの読み込み(PyNWB使用)
from pynwb import NWBHDF5IO
io = NWBHDF5IO('sub-P11HMH_ses-20061101_ecephys+image.nwb', 'r')
nwbfile = io.read()
# ステップ2:unitsとtrialsのDataFrame化
units_df = nwbfile.units.to_dataframe()
trials_df = nwbfile.trials.to_dataframe()
# ステップ3:窓内スパイク数の抽出(例:刺激後200ms〜1200ms)
def count_spikes(spike_times, onset, t0=0.2, t1=1.2):
return ((spike_times >= onset + t0) & (spike_times < onset + t1)).sum()
# ステップ4:状態簡約(クリップ)
import numpy as np
x1_clipped = np.clip(x1_counts, 0, 5)
x2_clipped = np.clip(x2_counts, 0, 5)
# ステップ5:経験分布の推定とPID計算(I_min, I_ccs)
# → 各PIDライブラリを使用(または下記の擬似コードに準拠)
# ステップ6:ブートストラップCI(400回など)
# → 試行インデックスをリサンプルして (R, U1, U2, S) を繰り返し計算I_min の擬似コード(Williams & Beer)
Input: x1[1..N], x2[1..N], y[1..N] (離散)
1) 経験分布 p(x1,x2,y) を計数/N で推定
2) 周辺分布 p(x1,y), p(x2,y), p(y) を計算
3) 各 y について特異情報 I_spec(y;X) = Σ_x p(x|y) log2(p(y|x)/p(y)) を計算
4) R = Σ_y p(y) * min(I_spec(y;X1), I_spec(y;X2))
5) I1 = I(X1;Y), I2 = I(X2;Y), I12 = I(X1,X2;Y)
6) U1 = I1 - R, U2 = I2 - R, S = I12 - R - U1 - U2
Output: {R, U1, U2, S}合成データデモ:PID定義差が結果に与える影響
XOR型相乗の典型例
神経集団符号で相乗が現れる典型例として、**XOR型(単独では情報0、組み合わせると情報が生じる)**の合成データを用いたデモを示す。
条件:試行数 N=2000、ターゲット Y ∈ {0,1}(2カテゴリ)、ソース X₁,X₂ ∈ {0,1}(2ニューロンの離散応答)。X₂ に反転ノイズ ε=0.1 を導入(応答雑音に相当)。
| 成分 | I_min 平均 | I_min 95%CI | I_ccs 平均 | I_ccs 95%CI |
|---|---|---|---|---|
| 冗長 (R) | 0.0002 | [0.0000, 0.0009] | −0.1296 | [−0.1437, −0.1165] |
| 固有 (U₁) | 0.0002 | [−0.0000, 0.0013] | 0.1299 | [0.1170, 0.1440] |
| 固有 (U₂) | 0.0004 | [−0.0000, 0.0022] | 0.1302 | [0.1171, 0.1441] |
| 相乗 (S) | 0.5238 | [0.4798, 0.5682] | 0.3953 | [0.3646, 0.4279] |
| 総MI | 0.5246 | [0.4799, 0.5687] | 0.5246 | [0.4854, 0.5698] |
この結果が示す重要な教訓は、同一データに対しても定義の違いが冗長・相乗の割り当てに大きく影響する点だ。I_ccs では冗長が負値(共通ミスインフォメーション)となり、相乗が I_min より小さく推定されている。総MIは一致しているため、分解の合計値は正しいが、「どの成分か」が定義によって変わる。
この定義感度の可視化と、ノイズ増加に伴う synergy 低下のプロット(両定義を重ねて表示)は、実測データに移行した際も同一形式で報告すべきだ。
多ニューロン拡張と今後の課題
2ソースを超えるPID(多ニューロン集団)への拡張は、**理論(格子の複雑化)・推定(状態爆発)・解釈(どの相乗が本質か)**のすべてで難易度が増す。Williams & Beerの冗長格子は一般多ソースを視野に入れているが、実務的に安定した推定と解釈を得るには次の方向が現実的だ。
- ペアごとの2ソースPIDを組み合わせたsynergyマップの作成
- サブセット解析(3〜4ニューロンの組み合わせに絞った検討)
- 潜在変数モデル(次元削減)との統合設計(連続潜在表現にKSGを適用)
また、強アンダーサンプリングが疑われる場合は Miller–Madow補正やNSBベイズ推定の採用を検討し、推定器依存性も報告することが科学的誠実さにつながる。
まとめ:PID実践のための3つの原則
部分情報分解は、ニューロン集団コードの「協働」を定量化する強力なフレームワークだ。しかし、その有用性は適切な実装と報告の枠組みに依存する。本記事の内容を踏まえた実践的な原則を3点にまとめる。
- 複数定義の併用:I_min をベースラインとして、I_ccs またはBROJA系を対照で算出し、定義依存性を結論の一部として報告する。
- 推定の不確かさの定量化:試行単位ブートストラップで信頼区間を算出し、シャッフル置換検定で帰無分布を構築する。
- 感度分析の標準化:窓幅・離散化・推定器・定義の各要因に対する感度を報告し、「synergy の解釈が何に依存しているか」を明示する。
これら3点を標準形として採用することで、PIDによる集団コード研究は再現性・比較可能性・解釈の透明性を大きく向上させることができる。
コメント