破滅的忘却がAI開発を阻む理由
AIモデル、特に自然言語処理(NLP)システムは、新しいタスクを学習すると以前の知識を失ってしまう「破滅的忘却(catastrophic forgetting)」という問題に直面します。これは単なる技術的課題ではなく、AIが人間のように連続的に学習し続ける能力を獲得するための最大の障壁の一つです。
本記事では、破滅的忘却の基本概念から、正則化、リプレイ、動的ネットワーク、パラメータ分離、記憶ネットワーク、メタラーニングという6つの主要な解決アプローチまで、理論と実践の両面から解説します。
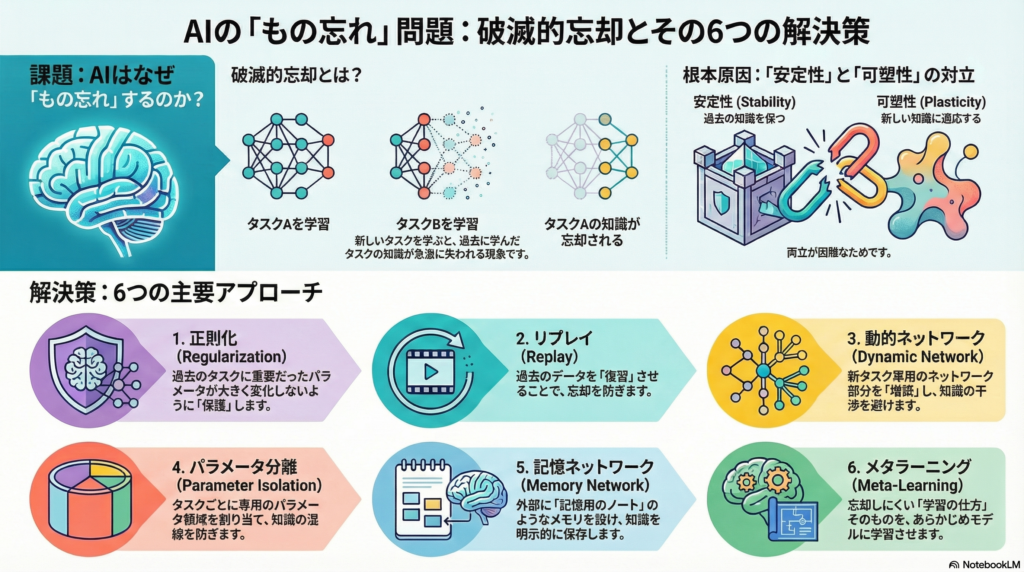
破滅的忘却の基礎知識
定義と発生メカニズム
破滅的忘却とは、ニューラルネットワークが複数のタスクを順次学習する際、新しいタスクを学習すると以前のタスクの知識が急激に劣化してしまう現象です。例えば、あるモデルがタスクAを学習した後にタスクBを学習すると、タスクBに適応するためのパラメータ更新がタスクAで獲得した重みを上書きし、結果的にタスクAの精度が大幅に低下します。
この問題は「安定性と可塑性のトレードオフ」として知られています。過去の知識を保持する「安定性」と新タスクに適応する「可塑性」の両立が、ニューラルネットワークでは本質的に難しいのです。
NLPにおける特有の課題
NLP分野では、継続学習の設定が特に多様です。英語のテキスト分類を学習した後に日本語の機械翻訳を学習するといったように、連続するタスクの種類が多岐にわたります。
さらに重要なのは、NLPではタスク間で語彙や意味の共通性が高いため、単に忘却を防ぐだけでなく「知識の転移」も考慮する必要がある点です。前向き転移(新タスク学習への旧タスク知識の活用)と後向き転移(新タスク習得が旧タスク性能を向上させる現象)の両方を実現することが、効果的な継続学習には不可欠です。
主要な解決アプローチ6選
正則化ベースの手法:重要なパラメータを保護する
正則化ベースの手法は、新しいタスクの学習時に損失関数にペナルティ項を追加し、過去タスクにとって重要なパラメータが大きく変化しないよう制御します。
代表的手法:EWC(Elastic Weight Consolidation) EWCでは、フィッシャー情報行列を用いて各パラメータの重要度を定量化します。重要なパラメータが新タスクで過度に更新されると損失が大きくなるように正則化項を設定することで、新タスク学習中も既習タスクの重要パラメータを極力保持します。
Synaptic Intelligence(SI) SIは各重みの「シナプス知性」を導入し、学習過程でパラメータがタスクの損失に与えた寄与を逐次積算します。オンライン方式で重要度評価を行うため、タスク間でフィッシャー行列を再計算する必要がなく効率的です。
長所:
- 追加のメモリや大規模パラメータ増加が不要
- 過去データを保持しなくても動作するためプライバシやメモリ効率の点で有利
短所:
- 新タスク習得とのトレードオフが避けられない
- 正則化が強すぎると可塑性が阻害され、弱すぎると忘却を防げない
リプレイベースの手法:過去を再現して記憶を保つ
リプレイベースの手法は、過去タスクのデータやその要約を再利用することで忘却を防ぎます。
Experience Replay(経験再生) 以前のタスクから一部のサンプルをメモリに保存し、新タスクの訓練データと混ぜて学習します。理論的には、完全な過去データリプレイができれば忘却は生じません。実際には、各タスクから限られたサイズのメモリバッファを確保し、代表サンプルを選択する戦略が模索されています。
Generative Replay(生成型リプレイ) 過去データそのものは保存せず、生成モデルから擬似データを生成してリプレイします。生成モデル(VAEやGAN)が過去タスクの特徴的なデータをサンプリングし、それを使ってメインモデルを新タスクと並行学習させます。
NLPでは、**LAMOL(Language Modeling for Lifelong Learning)**が注目されています。LAMOLは全てのNLPタスクを言語生成タスクに変換し、GPT-2モデルにタスクをまたいで言語モデリングさせます。新タスク到来時にはモデル自身に旧タスクの擬似サンプルを生成させ、それと新タスクデータを混ぜて再学習します。
長所:
- モデルが直接過去のデータ分布を再経験できるため忘却防止効果が高い
- 生成型リプレイはプライバシ保護やメモリ節約の観点で有利
短所:
- メモリ使用量の問題がつきまとう
- 生成モデル自体の訓練コストや生成データの品質が課題
動的ネットワークアーキテクチャ:構造を拡張して干渉を回避
動的ネットワークアーキテクチャでは、ニューラルネットワークの構造自体をタスク追加に応じて拡張したり変化させたりします。
Progressive Neural Networks(逐次拡張型ネットワーク) タスクごとにニューラルネットの「カラム(縦列)」を新設し、以前のタスクのネットワークは凍結して残します。各新タスクのカラムは、過去タスクの各層からの横方向の接続を受け取ることで、既習知識を再利用できます。
DEN(Dynamically Expandable Networks) 新タスク到来時に必要最小限のニューロンと結合をネットワークに追加し、ネットワーク容量を動的に調整します。まず既存ネットワークの重みの一部を選択的に再学習して新タスクに適応させ、それでも不足する表現は新しいユニットを追加して学習します。
NLPでは、事前学習言語モデルに対し各タスク専用のアダプタ層(小規模の追加パラメータモジュール)を挿入するアプローチが使われています。各タスクの推論時には全アダプタを順に適用してパープレキシティが最も低いものをそのタスクのものと判定します。
長所:
- 過去タスク部分を保護するため、理論上は完全に忘却を防止できる
- 知識転用により新タスク学習のサンプル効率向上が見込める
短所:
- タスク数だけネットワークが線形に肥大化するためメモリ使用量が増加
- タスクIDに依存または推定機構を組み込む必要がある
パラメータ分離:専用領域で干渉ゼロを実現
パラメータ分離手法は、各タスクに固有のパラメータ集合を割り当て、タスク間でパラメータの干渉を防ぎます。
HAT(Hard Attention to the Task) 各タスクに対して層ごとにバイナリマスク(0/1のフィルタ)を学習します。新タスク学習時には、過去タスクのマスクで使用されていたニューロンには勾配が流れないようブロックし、結果的に過去タスクで使われたパラメータは不変に保たれます。
SupSup(Supermasks in Superposition) 大きな基盤モデルに対し、各タスクごとに同じサイズのバイナリマスクを学習し、異なるタスクは異なるサブネットワーク(重みの部分集合)で処理されます。
長所:
- 各タスクが専用パラメータで保護されるため干渉が原理的にゼロ
- 旧タスク性能を劣化ゼロで維持できる可能性
短所:
- タスク数に比例して必要パラメータ総数が増大
- 知識の再利用ができず後向き転移・前向き転移のメリットが得られない
記憶ネットワーク:外部メモリで知識を保存
モデルの重みとは別に経験を蓄積するメモリ構造を設け、必要に応じて情報を読み書きすることで忘却を防ぎます。
FearNet 脳にインスパイアされた二重メモリシステムを備えたモデルです。海馬に相当する短期記憶ネットワークと大脳皮質に相当する長期記憶ネットワークの2つを使い分けます。新しい知識はまず短期メモリに蓄積され、一定時間後に長期メモリに統合されます。
NLPでは、エピソディックメモリを対話モデルに組み込み、過去に会話した事実情報をメモリから検索して新たな問いに答える研究が行われています。
長所:
- 理論上無限に知識を蓄積可能な拡張性
- 重要情報を明示的に保存できる解釈性
短所:
- モデル全体の複雑さが増す
- メモリ内容のメンテナンスや検索の計算量など解決すべき工学的課題が多い
メタラーニング:学習法そのものを学ぶ
メタラーニングを用いたアプローチは、モデル自身が忘却しにくいように事前に訓練されている、または新タスクに素早く適応できるよう学習戦略を習得していることを目指します。
OML(Online Meta-Learning) メタトレーニングで多数の小規模タスクを順番に学習させ、表現層が新タスクを学習しても既存タスクの損失があまり増えないような特徴を抽出するよう訓練します。こうして得られたモデルは、新たなタスク系列に対して干渉の少ない内部表現を持つため、シンプルなオンライン更新でも忘却が起こりにくくなります。
長所:
- 汎用性の高い解をデータから自動で見つけ出せる
- 追加のメモリや構造変更なしに忘却を緩和でき、他手法とも組み合わせ可能
短所:
- メタラーニング自体の計算コストや複雑さが高い
- メタトレーニングに含まれない種類のタスクが後から来ると対処できない可能性
各手法の比較と実用的考察
現状では、どの手法も一長一短であり、万能な解決策は存在しません。実際の継続学習システムでは、これらのハイブリッドが用いられることも多くなっています。
例えば:
- 正則化 + リプレイ:プロンプトの蒸留とリプレイ生成を併用
- 動的拡張 + 正則化:旧モジュールの変化を抑えながら新モジュールを追加
- メタラーニング + リプレイ:リプレイデータ選択を学習
タスク設定ごとのベストプラクティスも確立されつつあります。例えば、クラス増分学習にはリプレイ + 出力層再調整 + タスク推定の組み合わせが効果的です。
NLPタスクへの応用例
文分類タスク
感情分類や意図検出などでは、ドメイン増分学習が頻出シナリオです。製品レビューの感情分類システムが新しい製品カテゴリーごとに順次学習を更新する場合、数例の旧データをリプレイしつつクラス不均衡を補正することで、過去のインテント分類性能を高く保つことができます。
機械翻訳
一般ドメインで訓練した翻訳モデルを特定ドメインに微調整すると、元の一般ドメイン性能が急落します。この問題に対し、逐次知識蒸留(新旧モデル間の動的な出力蒸留)とバイアス補正を組み合わせることで、一般ドメイン性能の低下を抑えながらドメイン内性能を向上させることができます。
質問応答・対話システム
対話エージェントが新しいドメインのQA能力を習得すると、以前のドメインのQA精度が下がる問題があります。エピソード記憶を導入したQAモデルでは、各QAペアからキーとなる表現をメモリに格納し、推論時に質問と近いキーを検索してそのメモリ内容でモデルを微調整することで、忘れていた知識を一時的に復元します。
言語モデルの継続学習
GPTやBERTのような言語モデルにおいて、新しいデータで継続学習を行うと既存の知識が書き換わる問題が起こります。モデルの全パラメータを更新するのではなく、一部の低ランク行列やプロンプトベクトルだけを新知識に合わせて学習させることで、既存知識の保持率が向上することが示されています。
まとめ:継続学習の未来と次なる研究テーマ
破滅的忘却は、AIが人間のように終わりのない学習を続けるための最大の障壁です。本記事で紹介した6つのアプローチは、それぞれ異なる理論的背景を持ち、状況に応じて使い分けることが重要です。
今後の展望として、以下の方向性が期待されます:
- 大規模言語モデルへの適用:GPT-4のような超大規模モデルに対し、パラメータ効率手法やモデル編集技術を組み合わせた継続学習の実現
- 知識の動的管理:すべてを記憶するのではなく、モデルが自律的に記憶すべき内容を判断し、能動的に忘却をコントロールするアルゴリズムの開発
- 理論的解析の深化:タスク間の干渉度を測る新たな指標や、パラメータ空間上の安定性を評価する理論枠組みの確立
継続学習は真に人間のような適応的知能に向けた重要分野であり、NLPを含むAI全般の基盤技術として今後も発展が期待されます。
コメント