はじめに
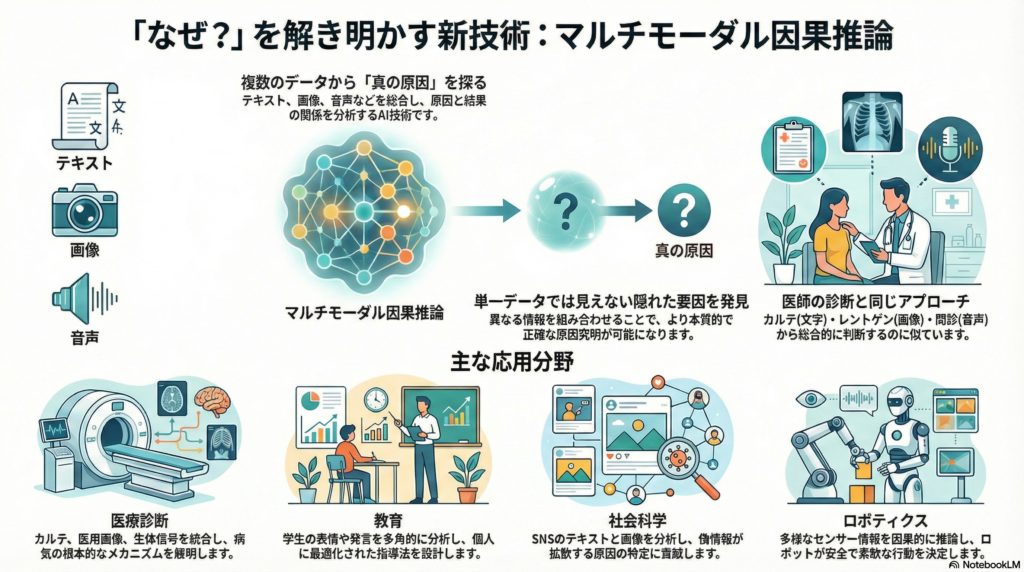
AI技術の進化に伴い、私たちが扱うデータは飛躍的に多様化しています。テキスト、画像、音声といった異なる種類のデータ(モダリティ)を組み合わせることで、単一のデータソースでは見えなかった「なぜそうなったのか」という因果関係を明らかにできる可能性が高まっています。これがマルチモーダル因果推論の核心です。
本記事では、マルチモーダル因果推論の定義から主要なアプローチ、実際の応用事例、そして今後の課題と展望まで、この最先端技術の全体像を包括的に解説します。
マルチモーダル因果推論とは何か
定義と従来手法との違い
マルチモーダル因果推論とは、複数の種類のデータを統合して原因と結果の関係を分析・推定する手法です。従来の因果推論は、主に数値やカテゴリなど構造化されたデータを対象としてきました。しかし現実世界では、医師が患者を診断する際にカルテのテキスト情報だけでなくレントゲン画像や問診での音声も参考にするように、複数の情報源を統合することで初めて本質的な因果関係が見えてくるケースが多くあります。
マルチモーダル因果推論には、従来手法と比較して三つの特徴的な違いがあります。
第一に、非構造化データからの要因抽出プロセスが必要です。従来は変数があらかじめ定義されていましたが、マルチモーダルでは画像や音声から因果に関連する特徴を見つけ出す「因子発見」の段階が加わります。
第二に、複数モダリティを組み合わせることで、単一モダリティでは観測できなかった潜在的な交絡因子を捉えられる可能性があります。これにより因果効果の推定精度が向上することが報告されています。
第三に、データの次元が非常に高くなり、モダリティ間でフォーマットや意味の不一致が生じるため、特徴の非整合性への対処が新たな技術的課題となります。
なぜ今、マルチモーダル因果推論が注目されるのか
近年の大規模言語モデルやマルチモーダルAIの発展により、非構造化データから意味のある情報を抽出する能力が飛躍的に向上しました。GPT-4やGeminiのようなモデルは、テキストと画像を同時に処理できるため、これらを因果推論の枠組みと組み合わせることで、AIの文脈理解や説明性を大きく高められると期待されています。
主要な技術的アプローチ
マルチモーダル因果推論を実現するために、いくつかの技術的アプローチが発展しています。
グラフィカルモデルとSEM
グラフィカルモデルは、ノードを変数、エッジを因果方向として因果関係を視覚的に表現する手法です。マルチモーダルの文脈では、画像由来の特徴量ノードと言語由来のキーワードノードを同じ因果グラフに含め、それらの関係をモデリングします。この手法は介入や反事実推論を理論的に扱える利点があります。
構造方程式モデリング(SEM)は、因果関係を連立方程式系で表現します。テキストから抽出した感情スコアのような潜在変数を含むSEMを構築することで、モダリティ横断的な因果構造を数式化できます。
潜在因子モデルと因果表現学習
観測データの背後にある低次元の因果的意味を持つ変数(潜在因子)を学習する因果表現学習は、マルチモーダル因果推論において重要な役割を果たします。
ある生物医学研究では、遺伝情報・睡眠パターン・身体計測データという複数モダリティから健康状態に関わる潜在因子を同定しました。この研究では「モダリティ間の因果結合は疎である」という現実的な仮定を導入することで、各モダリティからのデータを組み合わせたときに初めて因果因子が識別可能になることを示しています。
因果探索アルゴリズムの進化
観測データから因果グラフ構造を自動的に発見する因果探索技術も、マルチモーダル時代に対応して進化しています。
2025年に提案されたMLLM-CDフレームワークでは、大規模言語モデルを用いてテキスト・画像・音声から候補因果因子を抽出し、反復的な反事実介入で因果構造を洗練します。従来手法では見逃しがちなモダリティ横断の因果リンクを高精度に同定できると報告されています。
他にも、グレンジャー因果性を拡張した時系列解析手法や、注意メカニズム付きディープラーニングによる因果構造学習(TCDFなど)が登場しており、暗黙的なモダリティ間相互作用を捉える方向で研究が進んでいます。
モダリティ別のアプローチと事例
画像における因果推論
画像データに対する因果推論では、物体や出来事の原因と結果を捉える試みが行われています。
AAAI 2024で報告されたSEINフレームワークは、画像中の物体と関係をグラフ構造で表現するシーングラフを活用しています。画像ペア間の変化をOptimal Transportで整合させつつテキスト記述と融合することで、日常イベントの因果関係認識を向上させました。テキスト単独のモデルでは見落とす非コモンセンスな因果も、画像情報を加味することで修正できることが示されています。
自動運転システムにおけるカメラ映像からの危険状況の原因特定や、医用画像での異常所見の原因疾患推定など、物理的・空間的な関係が鍵となる応用が広がっています。
音声における因果推論
音声モダリティでは、発話や音響信号の背後にある原因構造を解明する研究が進んでいます。
2024年に提案されたCausalMERは、感情認識における課題に対処した手法です。従来のマルチモーダル感情認識システムは単一モダリティ(特にテキスト)に依存しすぎて、モダリティが欠落した状況で性能が低下する問題がありました。CausalMERは視覚・音声・言語の各モダリティから感情特徴を抽出し、反事実推論を用いて一つのモダリティへの過度な依存を抑制します。これにより従来より高い汎化性能を達成し、モダリティ欠落時でも安定した精度を示しました。
テキストにおける因果推論
テキストは因果関係を表現する言語表現が豊富なモダリティです。アプローチは大きく二つに分けられます。
一つ目は、文章中の因果表現(「XだからYとなった」など)から因果の対を抽出するタスクです。物語分析では出来事間の因果関係を定量的に調べる研究があり、自然言語処理技術を活用して因果を示唆する表現を手がかりに原因・結果を抽出するアルゴリズムが提案されています。
二つ目は、テキストを用いた因果効果の推定です。ソーシャルメディア上の発言をテキスト解析して介入変数とみなし、その影響を因果推論する社会科学的分析が行われています。
ただし現在の大規模言語モデルは、もっともらしい応答を返すパターンマッチング能力に長ける一方で、言葉の意味や因果関係を真に理解しているわけではないと指摘されています。このため、言語的知識グラフの構築や、LLMの出力を因果グラフにマッピングして検証可能にするアプローチが模索されています。
モダリティ統合による因果推論
統合的フレームワークの設計
複数モダリティを統合的に扱う因果推論では、各モダリティから抽出された情報を共通の表現空間にマッピングする工夫が重要です。
MLLM-CDフレームワークでは、事前学習済みマルチモーダルモデル(CLIPなど)を用いて意味的にアラインされた埋め込み表現を各モダリティから抽出し、異種データ同士でも比較可能な特徴量に変換しています。この共通化された特徴空間上で因果推論アルゴリズムを適用することで、モダリティ間のギャップを埋めつつ因果関係を学習できます。
2026年発表のMCDFフレームワークは、情報融合と因果解析を一体化した設計です。グラフニューラルネットワークでソーシャル関係を、Vision Transformerで画像特徴を、RoBERTaモデルでテキストをエンコードし、テンソル融合ネットワークでそれらを動的に統合します。さらにノイズゲーティング機構でモダリティ間の矛盾情報をフィルタリングし、DEMATEL法による因果推論モジュールで誤情報拡散の要因を定量化・可視化しています。
理論的基盤の発展
マルチモーダル因果表現学習の理論研究も、統合的アプローチに寄与しています。
2024年のLiらの研究では、複数モダリティに跨る潜在変数モデルを提案し、「ある潜在因子は特定のモダリティにしか影響しない」という現実に即した構造的疎性の仮定を導入しました。この前提により、マルチモーダルデータを組み合わせたときに初めて因果因子が識別可能になる条件を理論的に示し、データ統合の利点を裏付けています。
主な応用領域と実例
医療診断における活用
医療分野では、カルテテキスト・医用画像・生体信号を統合した因果分析が進んでいます。人間のフェノタイプデータセットでは、身体計測・睡眠ログ・遺伝情報といった複数モダリティを解析することで、疾患の背景メカニズムを解明し、新たなバイオマーカー発見や予測モデル構築に役立てています。
画像所見と言語報告を因果的に関連付けることで、診断根拠を説明可能にする研究も進んでおり、臨床意思決定の透明性向上に貢献する可能性があります。
教育分野での応用
マルチモーダル学習分析により、学生の学習プロセスを多角的にデータ収集し因果解析する試みがあります。
一対一のコーチング場面で映像(視線や表情)・音声(会話内容やトーン)・生体信号を同時記録し、教師の支援行動が学生の認知・感情状態に与える影響を因果モデルで解明する研究が報告されています。この分析から「どのタイミングでどんなフィードバックを与えると学習効果が高まるか」等の知見が得られ、パーソナライズされた指導法の設計に繋がっています。
HCIとロボティクス
ヒューマン・コンピュータ・インタラクションでは、ユーザの音声トーン・表情変化・発話内容を統合解析し、ストレスや満足度に影響する要因を探る研究があります。脳波・視線・音声を同時計測し、人間とAIロボットの協調作業中の因果関係ネットワークを可視化する試みも報告されています。
ロボット工学では、多様なセンサーから環境を認識し因果的に推論することで、安全で柔軟な行動決定を行う研究が進んでいます。ベイズ的マルチモーダル統合をロボットに実装し、センサー情報の不一致時には原因を分けて推論する仕組みを組み込むことで、現実世界の環境変化に適応しやすいシステム設計が模索されています。
社会科学・インフルエンス分析
ソーシャルメディア上のテキスト・画像投稿やユーザ間のネットワークデータを組み合わせて、偽情報の拡散原因を探る研究が登場しています。
ある研究では、SNS上の発言内容と拡散経路を融合し、因果分析手法によって「どの要因が拡散を促進したか」を定量化しました。その結果、誤情報が広がる主な要因(煽動的な画像の付与など)を明らかにし、政策立案者やファクトチェッカーに行動可能な知見を提供できることが示されました。
技術的・哲学的課題
モダリティ間の非整合性
異なるモダリティから得られる情報同士が食い違ったり、時間的にずれていたりする問題は、マルチモーダル因果推論の大きな課題です。画像は笑顔と判断しても音声のトーンは怒っているように聞こえるケースでは、どちらを信頼すべきか判断が難しくなります。
この問題に対処するため、信用できないモダリティ情報をダウンウェイトするノイズゲーティングや、ベイズ的因果推論モデルのように共通原因か否かを推定するレイヤーを加える試みが行われています。
因果同定の限界
観測データから因果構造を一意に特定することの難しさは、マルチモーダルでも根本的に存在します。むしろモダリティが増えることで潜在変数や交絡の可能性が増え、識別の曖昧さが深刻化する可能性があります。
この限界に対し、ドメイン知識に基づく構造制約の導入(モダリティ間の因果関係は限定的である等)や、因果探索と人間の知識をインタラクティブに組み合わせるアプローチが模索されています。また観測データだけでなく介入実験データを併用して識別性を高める研究も重要ですが、現実には全組み合わせでの介入実験は難しく、統計的仮定と部分的な介入で対処しているのが現状です。
認知的妥当性・解釈性
モデルが発見した因果関係が人間にとって直感的に理解可能か、妥当なものかという課題も重要です。マルチモーダル因果推論は複雑なモデルになりがちで、その出力する因果グラフや効果推定が「なぜそうなるのか」を説明するのが難しい場合が多くあります。
医療や社会分野の応用では説明可能性と専門家の知見との整合性が重視されるため、因果推論結果をヒューマンフレンドリーに可視化したり、因果グラフ上のパスを自然言語で説明する工夫が求められています。
今後の展望
大規模マルチモーダルモデルとの融合
GPT-4やGeminiのようなマルチモーダル対応の大規模モデルと因果推論手法を組み合わせたハイブリッドモデルの開発が進むと期待されます。大規模モデルの持つ柔軟な推論能力と統合表現力を、因果推論の厳密なフレームワーク(介入や反事実推論)で補完することで、より高性能かつ説明可能なAIシステムが実現できる可能性があります。
モダリティ間の交絡解消と識別性向上
マルチモーダルデータならではの利点を活かし、従来難しかった因果効果の識別に突破口が生まれる可能性があります。一つのモダリティでは観測できない交絡因子も、別のモダリティ情報で観測・制御できる場合があり、このようなモダリティ補完による因果同定法の体系化が期待されます。
ベンチマークと評価手法の整備
現状、マルチモーダル因果推論の性能を測る統一的なベンチマークは限られていますが、今後標準的な評価データセットや指標が提案されるでしょう。2025年に提案されたMuCRベンチマークは、テキストと画像の因果推論課題でマルチモーダルモデルの性能を評価し、現行モデルがテキスト単独の場合より大幅に性能が低下することを示しました。
評価指標も、精度だけでなく説明可能性やロバスト性(モダリティ欠落時の性能劣化の少なさ)などを含めた総合評価が求められるでしょう。
応用分野での深化と社会実装
医療分野では電子カルテ×遺伝子データ×画像の多次元解析により個別化医療の因果知見が蓄積される可能性があります。教育分野では学習者のマルチモーダルデータからリアルタイムに因果的フィードバックを返すインテリジェントTutoringシステムの登場も考えられます。
社会科学では、経済指標・SNSテキスト・衛星画像などを組み合わせて地球規模の課題(気候変動や災害要因分析)に因果推論を応用する試みも期待されます。ただし実装にあたってはプライバシーや倫理の課題、専門家との協働による検証も不可欠です。
まとめ
マルチモーダル因果推論は、複数種類のデータを統合して原因と結果の関係を探る最先端技術であり、AIの文脈理解と説明能力を飛躍的に高めるポテンシャルを持っています。グラフィカルモデル、潜在因子モデル、因果探索アルゴリズムといった技術的アプローチが発展し、医療診断、教育、HCI、ロボティクス、社会科学など幅広い分野での応用が進んでいます。
一方で、モダリティ間の非整合性、因果同定の限界、認知的妥当性といった課題も存在します。今後は大規模マルチモーダルモデルとの融合、識別性向上の理論的発展、ベンチマーク整備、そして実社会での慎重な実装が期待されます。
モダリティ統合の巧拙や因果的思考と統計学習の架橋という難題を解決できれば、マルチモーダル因果推論は複雑な現象の因果を解き明かす新たなツールとして、学術から産業まで幅広く活用されていくでしょう。
コメント