はじめに:質的データ分析の課題とNLPの可能性
エスノグラフィー研究において、フィールドワークで得られる観察メモは貴重なデータ源です。しかし、自由記述形式のテキストデータは量が膨大になりやすく、人手による分析には多大な時間と労力がかかります。近年、自然言語処理(NLP)技術の飛躍的な進化により、こうした質的データの自動分析が現実的になってきました。
本記事では、観察メモの自動意味抽出と構造化に活用できるNLP技術の最新動向を、具体的な手法、ツール、実践事例とともに解説します。
観察メモ自動処理を支える最新NLP技術
大規模言語モデル(LLM)がもたらす変革
観察メモの自動解析において、最も大きなインパクトをもたらしたのが大規模言語モデルの登場です。BERTに代表されるTransformerベースのモデルは、文脈に応じた単語の意味表現を可能にし、従来の手法では捉えきれなかった高次の概念間の類似性を検出できます。
例えば、「syringe(注射器)」と「injection(注射)」のように、表面的には異なる単語でも意味的に関連する表現を自動的に結びつけることができます。これにより、観察メモ中の散在した情報を統合的に理解することが可能になりました。
生成系LLMの活用
ChatGPTやGPT-4などの生成系LLMは、さらに柔軟な分析を可能にします。自然言語でのクエリを通じて、非エンジニアでもテキストデータを調査できる環境が整いつつあります。
適切なプロンプト設計を行えば、事前学習済みモデルに追加の学習なしで、ゼロショットでの分類や要約が可能です。近年の研究では、GPT-4を用いたゼロショット・Few-shot分類の有効性が報告されており、少量の例示だけで高精度な結果が得られることが示されています。
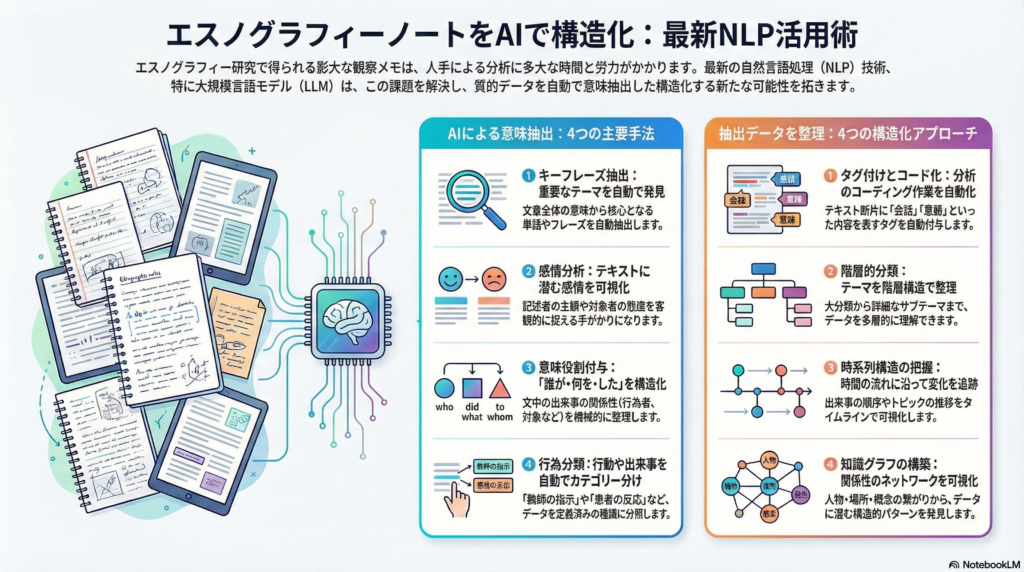
意味抽出に適した4つの主要手法
1. キーフレーズ抽出
観察メモから主題や特徴的な用語を把握するには、キーフレーズ抽出が効果的です。KeyBERTのようなツールは、BERTモデルの埋め込みベクトルを利用し、文書全体の意味に最も類似する単語やフレーズを自動抽出します。
他にも、RAKE、TextRank、YAKEといったアルゴリズムが知られており、目的に応じて使い分けることができます。これらの手法により、大量の観察メモから重要なテーマを素早く把握することが可能になります。
2. 感情分析
テキストから筆者や記述対象者の感情極性を判定する感情分析は、観察メモに含まれる感情的反応や雰囲気を捉えるのに有用です。対象者の体験に対する態度や、研究者自身の主観的反応を客観視する手がかりとして活用できます。
顧客フィードバック分析では感情トーンを評価して製品に対する感情的傾向を明らかにする事例があり、同様のアプローチがエスノグラフィー研究でも応用可能です。
3. 意味役割付与(Semantic Role Labeling)
文中の「誰が・何を・した」という関係を抽出する意味役割付与は、観察メモ中の出来事の構造を機械的に整理するのに役立ちます。
例えば、「太郎が花子に本を渡した」という文から、「太郎=行為者(Agent)」「本=テーマ(Theme)」「花子=受け手(Recipient)」といった意味的役割を自動的に割り当てることができます。BERTを用いた最新のSRLモデルでは、文脈を加味した高精度な役割認識が可能になっています。
4. 行為分類
観察メモに記述されている行動や出来事の種類を自動分類する手法です。教育現場の観察記録であれば「教師の指示」「生徒の発言」「クラスの笑い」、医療現場のフィールドノートであれば「ケア行為」「患者の反応」「環境要因」といったカテゴリに分類することで、データを構造化できます。
教師あり学習でテキスト分類モデルを訓練する方法や、ラベル説明文を与えてゼロショット分類を行う方法(生成系モデルへのプロンプト利用)が適用可能です。
観察メモを構造化する4つのアプローチ
タグ付けとコード化
質的分析のコーディング作業を自動化する形で、テキスト断片に対し内容を表すタグやコードを自動付与します。「会話」「葛藤」「身体動作」「環境描写」といったタグを各メモに付けることで、データの整理が進みます。
近年のLLMを利用した自動コード付与では、あらかじめ定義したコードブックに従って各テキストを該当カテゴリに割り振ることも可能です。ゼロショット分類や少数の例示を使ったFew-shot学習により、人手による事前ラベル付きデータが少なくても対応できる柔軟性があります。
階層的分類
カテゴリー体系に基づきテキストを階層構造で分類する方法です。まず「社会的相互作用」「道具の使い方」「環境要因」などの大分類に仕分けし、次に「社会的相互作用」の下位に「対話」「非言語コミュニケーション」などの詳細カテゴリを設ける形です。
BERTopicにはトピック階層の可視化機能があり、観察メモを包括的なテーマから詳細なサブテーマまで整理できます。分析者は関心に応じて異なる粒度でデータを閲覧でき、多層的な理解が可能になります。
時系列構造の把握
エスノグラフィーでは時間の流れとともに事象が展開するため、観察メモをタイムラインに沿って構造化するアプローチも重要です。各メモのタイムスタンプや日付情報を基に時系列分析を行い、出来事の順序・変化を捉えます。
テキスト中の時間表現を抽出・正規化する技術(Temporal Information Extraction)も発展しており、フィールドワーク中の出来事を日ごとやセッション順に並べ、NLPで抽出したトピックや感情の推移を可視化することができます。変化やプロセスに着目する質的研究において、この手法は洞察を深めるのに有用です。
知識グラフの構築
観察メモ内のエンティティ(人物・物・場所・概念)とそれらの関係を知識グラフとして表現するアプローチです。固有表現抽出(NER)でテキストから人物名や地名、組織名などを自動抽出し、併せて関係抽出により「誰が・誰と・何をした」といった関係情報を検出します。
例えば「研究者AがコミュニティXでインタビューを実施」という記述から、「研究者A –(実施)→ インタビュー –(場所)→ コミュニティX」のようなグラフデータを構築できます。知識グラフ化により、観察メモ中の登場人物間のネットワークや出来事と場所の関連性が可視化され、質的データに潜む構造的パターンの発見に寄与します。
エスノグラフィーデータ特有の課題への対応策
ノイズや非整形テキストへの対処
フィールドノーツは箇条書きや断片的な文章、略語だらけのメモなど、非構造的・非文法的な記述を含むことが多くあります。この課題に対しては、前処理でスペルミス修正や簡易な構文補完を行いテキスト品質を高めることが有効です。
また、句読点や改行といった書式情報も有益な場合があるため、そうしたメタ情報を保持した特殊トークナイゼーションを用いることも検討されます。さらに、口語やチャット文体でプレトレーニングされたモデルを選ぶことで、非定型テキストからの解析精度向上を図ることができます。
文脈依存性とグラウンディング
観察メモは研究者の視点から切り取られた部分的な記述であり、背景知識や文脈がないと機械的には解釈が難しい情報も含まれます。LLMは大量の一般知識を持ち合わせていますが、現場固有のコンテクストまでは把握できません。
そのため、自動分析の結果を用いる際には、人間研究者がフィールドの文脈を踏まえて解釈補助を行う「グラウンディング(文脈付与)」が必要です。実際の研究事例では、オンラインデータから抽出されたトピックの中に現場とは無関係な話題が混入したケースもあり、研究チームが現場知識をもとに取捨選択を行っています。
主観性・バイアスの管理
エスノグラフィーのフィールドノートには、観察者である研究者の主観や解釈が少なからず入り込みます。NLPの導入は、この研究者バイアスを自覚的にコントロールする一助となります。
人手のコーディング結果と機械による自動テーマ抽出結果を付き合わせて比較検討することで、研究者自身が見落としていたパターンに気付くことがあります。また、感情分析によってフィールドノート中の記述態度を定量化し、著者の偏りを点検することも可能です。
ただし、「NLPはあくまで補助であり解釈主体は人間」という位置づけが重要です。モデルの出力を鵜呑みにせず、なぜそのような結果が出たのかを現場知識と照らし合わせて考察する姿勢が求められます。
少量データ問題への対策
質的研究ではサンプル数が数十程度と少なく、NLPの学習に十分な量が確保できないケースも多々あります。こうした場合、転移学習済みモデルを活用したり、ゼロショット・Few-shot学習で対応することになります。
近年の研究では、GPT-4に数例のコーディング例を与えると人間のコードと高い一致率を示すことが報告されています。大規模事前学習モデルの活用や、場合によっては追加でインタビュー記録やソーシャルメディア投稿など外部データを組み合わせて分析する(データ拡張)ことも検討されます。
実践で使われているツールとライブラリ
spaCy
Python製の高速NLPライブラリで、トークン化・品詞タグ付け・依存構文解析・固有表現抽出など幅広い基本機能を備えています。カスタムモデルの訓練やルールベース抽出との組み合わせも容易で、質的データ分析でまずspaCyでテキストを解析し重要語やエンティティを抽出してから分析者がコード化する、といった使い方がされています。
BERTopic
BERT埋め込みとトピックモデルを組み合わせて文書集合内の話題を自動抽出できるライブラリです。観察メモの集まりに適用すれば、フィールドノート群から潜在的なトピックを可視化したり、時系列で話題の推移を分析することが可能です。
インタラクティブな可視化機能も持ち、トピック間の距離マップや階層クラスタ図を生成してくれるため、質的研究者が結果を解釈しやすい利点があります。
大規模言語モデル(GPT系)
OpenAIのGPT-3/4や、オープンソースのLlama 2など、汎用言語モデルを直接テキスト分析に利用するケースが増えています。プログラミング不要で対話的に分析できるChatGPTは、観察メモを入力して要約やキーワード抽出をさせたり、指定した視点で分類させることが容易に試せます。
研究ではGPT-4を使った自動コード付与が検証されており、Embeddingモデルと組み合わせて人間のコーディングと高い一致率を達成しています。ただし、結果の妥当性確認のため、人手による検証工程が推奨されています。
その他の専門ツール
キーワード抽出専用のKeyBERTや、テキストマイニング全般をGUIで行えるMonkeyLearn、感情分析特化のLexalyticsなども利用されています。また、伝統的な質的データ分析ソフト(CAQDAS)もAI機能を取り入れ始めており、NVivoには機械学習を用いた自動コード化機能が搭載されています。
実践事例:各分野での活用状況
企業におけるHCI/UXリサーチ
製薬企業向けのエスノグラフィー研究では、フィールドインタビューだけで見出せなかった患者体験上の論点を補完するため、オンラインフォーラム(特定疾患に関するReddit投稿数百件)を収集してBERTopicでトピック抽出を行った事例があります。
その結果、インタビューでは軽視されていた注射部位の皮膚炎問題がトピックとして浮上し、定性的調査チームに新たな示唆を与えました。抽出されたトピックが本当に現場に有用かを質的研究者が評価し、有益なものは洞察に採用する、というプロセスが取られています。
公衆衛生における計算エスノグラフィー
公衆衛生分野では、エスノグラフィー的な生活体験の知見と、大規模データ分析によるスケーラビリティの両立を図る研究として「計算エスノグラフィー」の概念が提唱されています。
大規模言語モデルを用いたLLM支援インタビューやLLMベース分析によって、従来のエスノグラフィー手法を補完し、社会的決定要因(Social Determinants of Health)の発見に寄与しうると論じられています。小規模詳細研究と大規模傾向分析の橋渡しになる可能性が注目されています。
医療分野の質的研究
診療現場のインタビュー記録に対するテーマ分析を人手とChatGPT(GPT-4)でそれぞれ実施し結果を比較した研究では、ChatGPTが高速に主要テーマを抽出でき、特に明確な概念については人手の分析と高い一致を示しました。
一方で、解釈の揺れやすい曖昧なテーマでは人間同士でも一致率が低く、GPTでも同様に安定しないことが分かりました。初期のコーディングやデータ整理をAIで支援し、その後の解釈は専門家が行うという役割分担が有望と考えられています。
教育・学習科学分野
GPT-4を使って教育現場の質的データを自動コーディングし、人間のコーディングと比較する実験が行われました。対象は「代数チュータリングの対話ログ」「ゲームベース学習環境での生徒観察記録」「プログラミング演習におけるバグ修正行動メモ」の3種類です。
定義が明確で具体的なコード(「正答/誤答」など)についてはGPTと人間の一致率が高く、一方で抽象的で解釈が分かれるコード(「主体的学習姿勢」など)は一致率が低い傾向が見られました。これは、比較的客観的な事象のラベル付けはかなり自動化できる可能性を示しています。
まとめ:人間とAIの協働による質的データ分析の未来
エスノグラフィーの観察メモをNLP技術で自動分析する手法は、質的研究の効率化と客観性向上に大きな可能性を秘めています。BERTopic、GPT-4などの最新技術を活用することで、大量のテキストデータから重要なパターンやテーマを自動抽出し、人手では困難だった洞察を得ることが可能になりつつあります。
ただし、NLPはあくまで補助ツールであり、解釈の主体は人間であることを忘れてはなりません。現場固有の文脈理解、主観性の管理、曖昧な概念の解釈といった領域では、研究者の専門知識が不可欠です。
今後、さらに高度な言語モデルや専用ツールが発展すれば、エスノグラフィーデータの扱いはより変容し、迅速かつ多面的に意味抽出・構造化ができるようになるでしょう。その際にも、人間とAIの協働による慎重な分析姿勢が、洞察の質を担保する鍵となります。
コメント