AIが「創造的に見える」振る舞いとは何か
大規模言語モデル(LLM)や画像生成AIが普及するなか、「AIは創造性を持つのか」という問いが研究者とビジネスの双方で切実さを増している。AIが小説のプロットを提案し、前例のない画像を合成し、囲碁で人間の定石を超える手を打つ——これらの振る舞いは「創造的」と呼べるのだろうか。
創造性研究における標準的な定義では、創造性とは「新規性(originality/novelty)」と「有効性(effectiveness/appropriateness)」の二要件を同時に満たすことを指す。さらに「驚き」や「価値」を含む多面的理解も広く支持されており、計算創造性の分野では「新規・驚き・価値」の三要素で整理されることが多い。
本記事では、機械学習モデルが示す創造的振る舞いを心理学・認知科学の測定指標で整理し、「創発」として説明できるかどうかを検討する。さらに人間の創造性との比較で浮かぶ定量的な差異、評価の難しさ、そして著作権や文化多様性に関わる倫理的論点までを俯瞰する。
創造性と創発の定義を整理する
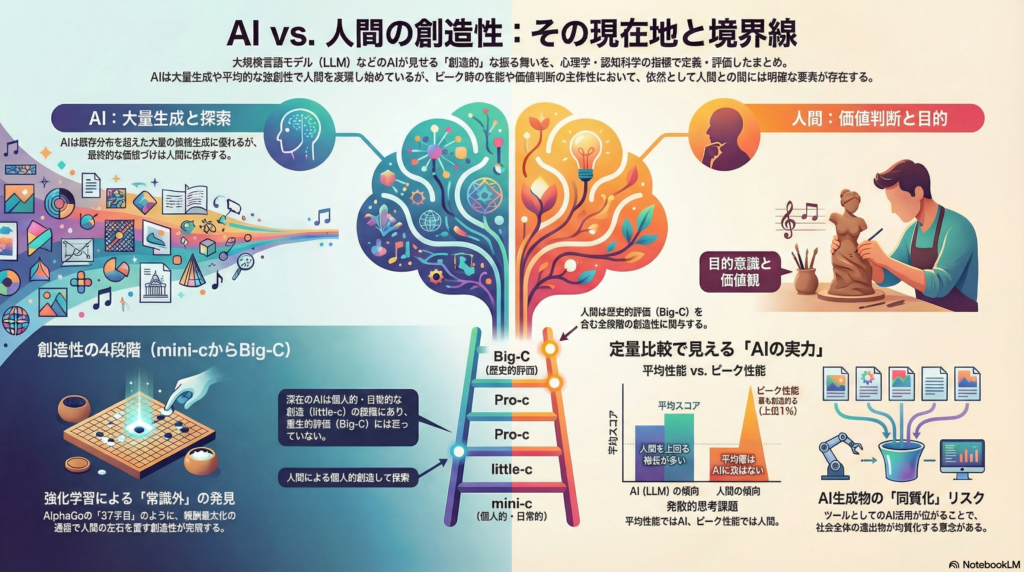
創造性の「標準定義」と4つのレベル
創造性は一枚岩の概念ではない。発達・専門性・社会的承認の水準によって、mini-c(個人的な気づき)、little-c(日常的な創造)、Pro-c(専門家の創造)、Big-C(歴史的評価を受ける創造)に区分される枠組みが提案されている。
この枠組みに照らすと、現時点の機械学習モデルはmini-cやlittle-c相当の生成物を示し得る。しかし、長期的な目的意識や社会制度との相互作用を含むPro-c・Big-Cを同じ基準で論じるには、追加の仮説が必要になる。
「創発」とは何か——LLM文脈での論争
創発は、要素還元では予見できない新しい秩序が相互作用のなかで現れる現象を指す。物理学者P. W. Andersonの「More is different」の議論に代表される古典的な概念だ。
LLMの文脈では、小規模モデルでは見られない能力が大規模モデルで突然現れる「創発的能力」の報告が注目を集めた。一方で、評価指標の離散化や統計処理の選び方によって”急激な立ち上がり”が人為的に生じうるという批判も示されており、創発の主張には慎重な検証が求められている。
モデル別に見る創造的振る舞いの特徴
機械学習における創造的振る舞いは、「生成(候補を大量に作る)」「探索(既知分布の外側を探る)」「評価・選択(価値判断)」「転移・合成(別領域の要素を持ち込む)」というプロセスに分解して比較すると理解しやすい。
LLM・拡散モデル・GAN/VAE:大量生成の強み
生成モデルは「候補を高速・大量に作る」能力に突出している。LLMは発散的思考課題で高い流暢性と平均独創性が報告されるが、価値判断や文脈適合の一貫性は外部の人間やルールに依存する構造となっている。拡散モデルは画像のバリエーション生成を自動化し、制作工程における試行錯誤を大幅に短縮した。
強化学習:「人間の常識外」が評価される場面
強化学習の典型例としてAlphaGoのMove 37が挙げられる。報酬最大化の過程で「人間の定石から外れたが有効な手」が出現し、囲碁コミュニティから創造的と受容された象徴的な事例だ。ただし、この「創造性」は勝利という目的関数の副産物であり、その価値づけは人間側の解釈に依存している。
進化計算・品質多様性(QD):多様性を明示的に追う
novelty searchやMAP-Elites、POETのような品質多様性アルゴリズムは、目的関数の最大化だけでなく「新規性」「多様性」を明示的に追求する。探索が局所解に陥る「欺瞞問題(deception)」を回避し、意外な解を得る設計思想そのものが創造性研究と親和性が高い。Picbreederのような人間参加型進化では、形式化が困難な美的領域での「人間を含む探索」として創造性が発現する。
人間の創造性とAIの定量比較で見えるもの
心理学的指標:流暢性・柔軟性・独創性・精巧性・価値
人間の創造性測定では、発散的思考(DT)指標が広く使われてきた。代表的なタスクとしてAUT(Alternative Uses Task:日常物の用途を多数挙げる)、DAT(Divergent Association Task:無関連な10語を挙げる)、TTCT(Torrance Tests of Creative Thinking)がある。
これらは「流暢性(アイデア数)」「柔軟性(カテゴリ多様性)」「独創性(希少性・意味距離)」「精巧性(詳細化の度合い)」で評価される。加えて、産物の「価値」を専門家合意で捉えるCAT(Consensual Assessment Technique)がプロダクト評価の古典的手法として用いられている。
比較研究が示す4つのパターン
LLMと人間の創造性比較研究は結論が分かれるが、繰り返し現れる重要なパターンがある。
第一に、平均的な性能ではAIがDT課題で人間を上回る報告が出ている。GPT-4がAUTやDATで高いスコアを記録した研究はその代表例だ。
第二に、ピーク性能では最も創造的な人間が依然としてAIを上回るという結果が示されている。AIは「上位尾部」をほとんど再現できない可能性がある。
第三に、同じLLMが同じ指示に対しても出力品質が大きく変動するため、平均値だけの比較は誤解を招き得る。再現性と分散の問題は見過ごせない。
第四に、人間側の条件設計(制限時間、指示の詳細さ、フィードバックの有無)が成績を大きく左右するため、「公平な比較条件」そのものの定義が争点になっている。
評価手法の課題:自動指標・ヒューマン評価・逆向き評価
自動評価のスケーラビリティと限界
画像生成ではFIDやInception Scoreが普及したが、これらの指標は「何を良さとみなすか」を暗黙に内包している。CLIPScoreのような参照なし指標は人間の評価との相関を改善しうるが、細粒度の誤りを捕捉しにくいという限界も報告されている。自動評価はスケールしやすい反面、指標の最適化が進むと指標だけが向上する「ゲーム化」のリスクがある。
ヒューマン評価の不可欠性とコスト
CATに代表される専門家評価は、「専門家が創造的だと合意したものを創造的とみなす」という立場をとり、創造性の社会的側面を取り込みやすい。一方で、領域横断・文化横断の比較では評価者集団の設計がボトルネックとなり、コストと一貫性の課題が伴う。
LLM-as-a-Judgeのバイアス問題
近年注目されるLLMによる自動評価(LLM-as-a-Judge)は、位置バイアスなどの系統的な不公平が報告されている。監査と補正の仕組みなしに信頼することは危険であり、「自動×ヒューマン×逆向き(敵対的検証)」に加えて分布の尾部まで見る多層評価プロトコルの標準化が推奨される。
倫理・社会的含意:著作権・雇用・文化多様性・環境
著作権と著作者性の国際的整理
米国Copyright OfficeはAI生成要素のみで構成される部分に人間著作者性を認めない方針を明確化しており、日本の文化庁もAIと著作権に関する論点整理を公開している。欧州ではAI法(EU AI Act)が汎用AIに透明性義務を課す枠組みとして参照されている。学習データの取り扱いと生成物の権利関係は、各国で制度設計が進行中だ。
創造支援ツールによる「同質化」リスク
創造支援ツールはアイデアの数を増やす一方で、利用者群の産出が均質化する「同質化(homogenization)」のリスクが指摘されている。多様性の喪失を定量的に把握する指標の開発が、単なる生産性向上とは異なる視点として重要になる。
環境負荷と公平性
大規模モデルの訓練には膨大な電力と炭素排出が伴い、研究資源の格差も拡大させる。創造性の自動化を社会全体で正当化するためには、環境・公平性の観点を含む説明責任が不可欠だろう。
まとめ:AIの創造性をどう捉え、次に何を問うべきか
機械学習モデルは「候補の大量生成」と「既知分布を超える探索」において、人間の創造プロセスの一部を代替・増幅できる。しかし、価値判断の社会的埋め込み、長期目的と主体性、ピーク創造性の再現、そして評価指標の妥当性と監査可能性において、人間の創造性と同型ではない。
「創造性の創発」を主張するには、スケール変化に伴う非線形性の観察だけでは不十分であり、指標感度分析と分布全体の評価で”見かけの創発”を排除する実証設計が欠かせない。AIの創造性を正しく理解し活用するためには、技術・評価・制度の三層での議論を同時に進める必要がある。
コメント