ChatGPTやClaude、Geminiといった対話型AIの進化は目覚ましく、人間のような自然な会話が可能になってきました。しかし、これらのAIは本当に「意味」を理解しているのでしょうか?それとも単に膨大なデータから統計的にもっともらしい言葉を並べているだけなのでしょうか?
この問いは、AI研究における根本的な課題「記号接地問題」として知られています。本記事では、大規模言語モデルの意味理解をめぐる最新の研究動向と、人間とAIが真に共有可能なシンボル体系を構築するための取り組みを探ります。
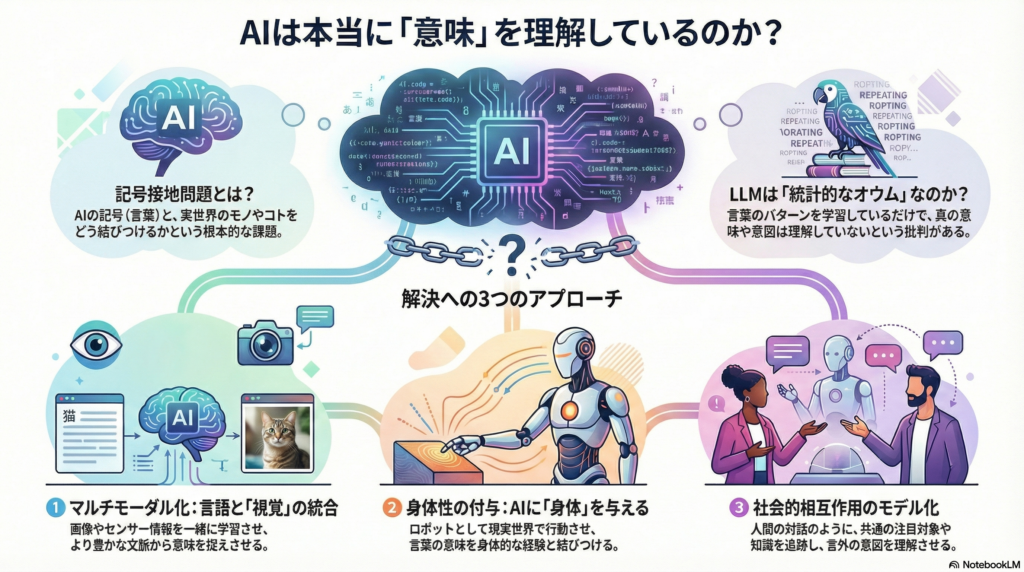
AIは「意味」を理解しているのか?記号接地問題とは
大規模言語モデルの意味理解をめぐる議論
大規模言語モデルは自然言語処理において驚異的な性能を示していますが、その意味理解が人間とどの程度一致しているかは重要な研究課題です。Bender & KollerやShanahanといった研究者は、言語モデルは文字列の統計的予測にすぎず、意味を真に理解せず意図を持たないと指摘してきました。
一方で、最近の研究では異なる視点も提示されています。Pavlickは、LLMがシンボル構造やグラウンディングを欠くという通説に対し、実証的知見が反論していることを示しました。彼女はLLMの言語理解能力をモデルの内部表現に注目して分析し、LLMを人間の言語モデル研究の道具として活用できる可能性を提案しています。
さらに興味深いのは、Doveによる身体性認知論との接続です。LLMがテキストのみで学習されることでセンサー・モータ経験に基づく意味理解が欠如するという批判に対し、Doveは人間の意味記憶にも言語固有の学習が大きく寄与していることを指摘します。つまり、人間の意味理解は身体的経験と共に言語を通じた学習にも依存しており、大規模言語モデルは人間の言語経験が世界理解を拡張する可能性の証明と考えられるのです。
シンボル構造とグラウンディングの重要性
記号接地問題の核心は、言語記号と実世界の対象をどのように結びつけるかという点にあります。Pavlickは、LLMの学習形式が形式的な言語規則(形式的能力)を捉える一方で、実世界での機能的言語運用(機能的能力)には弱点があると指摘しています。
この視点から、記号や意味に対する批判的前提に実証研究で挑む試みが進んでいます。例えば、Iidaらは対話型LLMに信念欲求意図モデルを統合し、発話の言外の意味を読み取らせる実験を行いました。この研究では、LLMと他者モデルの協調的連携が対話理解を改善する可能性が示されています。
マルチモーダルLLMが切り拓く新たな可能性
視覚・言語・行動を統合するPaLM-EとNICO
人間は言語だけでなく、視覚情報や身体運動を通して意味を伝達します。この事実に着目し、近年では画像や映像などの視覚情報を取り込むマルチモーダルLLMの研究が活発化しています。
GoogleのPaLM-Eは、540億パラメータのPaLMに加え、ロボットセンサーやカメラ画像を統合したモデルです。画像と言語が同一の入力空間で処理されることで、PaLM-E-562Bは視覚・言語タスクで最先端性能を達成しながら、言語のみの性能もほぼ維持しています。これは、LLMが視覚情報と統合して一般化能力を獲得できることを示す重要な成果です。
同様に、Hamburg大学が開発したNICOロボットシステムでは、LLMを対話制御のコアとし、音声認識・画像認識・ジェスチャー検出・視線制御などのモジュールと連携させています。自然言語と動作(視線・指差し)を統一的に扱うことで、人間の曖昧な問いへの反応精度を大幅に向上させることに成功しました。
DeepMindのGatoも、ロボット動作・画像キャプション・ゲーム対戦など600以上のタスクを単一モデルで学習し、マルチモーダルな能力獲得の可能性を示しています。
指標的ジェスチャー理解の課題
しかし、マルチモーダルLLMにも限界があります。西田らの最新研究(2025)では、GPT-4oを含むMLLMにジェスチャー説明文を生成させたところ、指を指して対象を示すような指標的ジェスチャーでは一貫して理解精度が低いことが報告されました。
分析の結果、MLLMはテキストと事前学習に基づく一般知識でジェスチャーを解釈する傾向があり、特に外界への参照を視覚的に認識することが必要なケースにおいて、ジェスチャーの適切な解釈を生成できないケースが見られました。これは、現行のMLLMが実環境の動的相互作用を十分に扱えていない可能性を示唆しています。
意図性と共意識:哲学から実装へ
中国語の部屋と意図的立場
生成AIにおける「意味理解」や「意図性」は、哲学・認知科学の古典的問題とも深く関わっています。哲学者ジョン・サールは「中国語の部屋」という思考実験で、コンピュータが中国語の質問に完璧な中国語で答えられても、それは単なる記号操作にすぎず、真の理解は存在しないと論じました。
これに対し、デネットは「意図的立場」を提唱し、AIの複雑な行動が人間同様に予測可能ならば、機能的に意図性を認めることが実用的だとしました。この立場では、振る舞いが目標志向的であれば意図を帰属してもよいと考えます。
実際、前述のIidaらの研究では、対話型LLMに信念欲求意図モデルを組み込むことで、人間の暗黙的意図を反映した応答生成が可能になることが示されています。これは、AIに「意図性」をどのように実装するかという哲学的問いに対する実証的なアプローチと言えるでしょう。
身体性認知(4E認知)とロボット実装
最新の4E認知論(身体性・環境埋め込み型・拡張・作用志向的認知)では、心的状態は身体的・環境的相互作用から生じるとされます。この観点から、言語モデルに「身体性」を付与することが意味理解の解決策になると考えられています。
Mon-Williamsらの研究では、GPT-4に物体操作のフィードバックを組み込んだロボットシステム「ELLMER」を提案し、カップコーヒー作成などの複雑動作を遂行できることを示しました。彼らは、ヒトの知能は身体性を含む認知プロセス全体に依存するとし、AIでも身体的な知覚と結合することでより人間に近い認知が可能になると述べています。
このように、生成AIにおける意図理解や意味生成は、知覚・行動を伴う身体性と結び付けて論じる研究が進んでいます。LLMにロボット体を与える研究は、単なる技術的実装を超えて、認知科学における根本的な問いに挑戦するものなのです。
共同注意と共通基盤のモデル化
プラグマティック・フレームと記号接地
対話の理解向上には、言語記号と外界・身体行動の対応づけや、対話者間で注目対象を共有する「共同注意」が重要です。Coradeschiらは、乳児と親の相互作用における繰り返しパターン(プラグマティック・フレーム)が新語学習を助けるとし、共同注意が意味獲得に必須であると論じています。
親は子に対して単なるシンボルと対象の紐付け以上に、ジェスチャーや視線で対話状況全体を示しながら意味を伝えます。この過程が言語学習を促進するのです。ロボット研究でも、共同注意を獲得するために視線誘導や同期的行動を利用する試みが行われています。
共通基盤追跡(CGT)の実装
さらに発展的なアプローチとして、Khebourらは人間同士のグループ対話から共通基盤追跡タスクを定義し、発話・ジェスチャー・行動といったマルチモーダル情報から共有される信念空間を自動検出する手法を開発しました。
彼らは、発話やジェスチャー、協調行動を論理的事実・証拠・問題(事実バンク・証拠バンク・質問バンク)としてモデル化し、対話の進行に応じてアップデートすることで、対話参加者間の共通知識を捉える枠組みを提示しています。
このアプローチは、単に言葉の意味を理解するだけでなく、対話参加者間で「何が共有されているか」を追跡することで、より深い対話理解を実現しようとするものです。
人間とAIの真の対話理解に向けて
これまで見てきたように、人間とAIが共有可能なシンボル体系の構築には、多様なアプローチが試みられています。実験研究では、ロボットにLLMを搭載して実世界で対話・行動させる試みが進んでおり、大規模データセットを用いたシミュレーションでは、LLMがジェスチャーや画像をどの程度理解するかが評価されています。
理論面では、認知科学や哲学の知見を取り入れた概念的考察が進んでおり、意味と意図をどのようにモデル化すべきかが議論されています。今後は、LLMの言語表象を身体的・視覚的データと結びつけ、共同注意や理論心モデルを統合するような実装が重要となるでしょう。
記号接地問題の完全な解決には至っていませんが、マルチモーダル統合、身体性の付与、共同注意のモデル化といった多角的なアプローチが進展しています。これにより、人間とAIが真に共有可能な記号体系を構築し、自然で深い対話理解が可能になることが期待されます。
AIが単なる言葉の羅列を超えて、人間と同じ世界を「理解」する日は来るのでしょうか?その答えは、言語、視覚、身体、そして意図が統合された新しいAIシステムの実現にかかっているのかもしれません。
コメント