はじめに:なぜ自己修正型モデルが注目されるのか
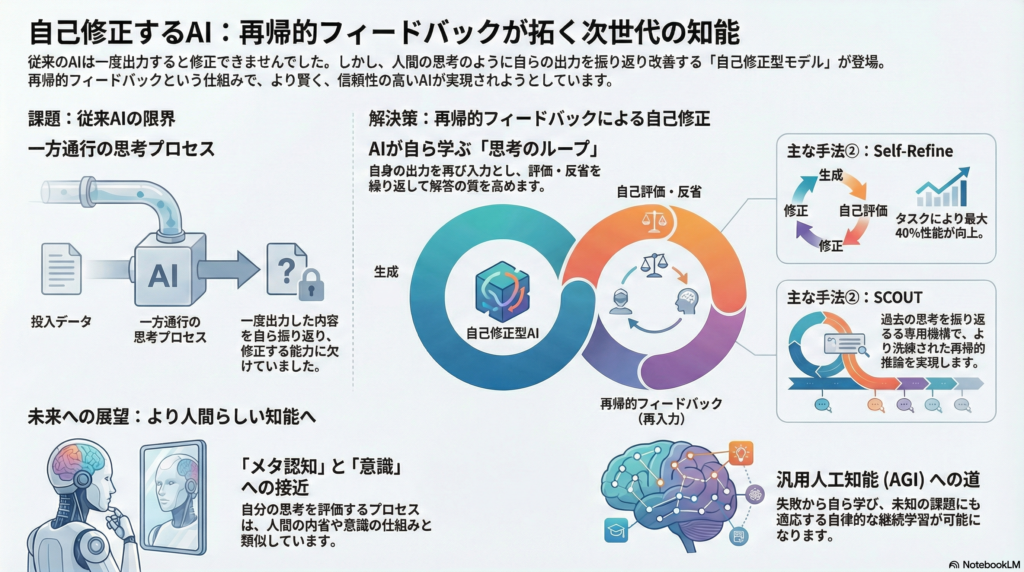
大規模言語モデル(LLM)の発展により、AIは人間に近い文章生成や推論を実現してきました。しかし従来のTransformerベースモデルは基本的に一方向の推論しか行わず、一度出力した内容を自ら振り返って修正する能力に欠けていました。
近年、この課題を克服するため「自己修正型生成モデル」の研究が急速に進んでいます。モデルが自らの出力を内省し、フィードバックループを通じて逐次的に改善していく——この再帰的フィードバック機構は、単なる性能向上にとどまらず、メタ認知や意識の計算論的側面にも迫る革新的アプローチとして期待されています。
本記事では、Transformerにおける自己修正型モデルの技術的実現方法から、哲学・認知科学的な意義、さらにはAGI(汎用人工知能)への展望まで、包括的に解説します。
自己修正を可能にする再帰的フィードバックとは
再帰的フィードバックの基本概念
自己修正型モデルにおける再帰的フィードバックとは、モデルが一度生成した出力を再び入力として取り込み、内部で評価・反省した上で出力を改善していくプロセスを指します。このアプローチは学習時と推論時の両方で統合され、モデルの思考過程を深め、推論の軌跡を段階的に洗練させる狙いがあります。
従来の一方向推論では、入力から出力への情報の流れは固定的でした。しかし再帰的フィードバックを導入することで、モデルは自身の過去の出力や中間状態を参照しながら、より一貫性の高い推論を実現できる可能性があります。
段階的な出力改善の重要性
人間が複雑な問題を解く際、初めから完璧な答えを導くことは稀です。むしろ仮説を立て、検証し、修正するというサイクルを繰り返します。自己修正型モデルは、この人間的な思考プロセスをAIに実装する試みとも言えます。
出力の内的評価による逐次修正は、一貫性や正確性を高めるだけでなく、モデルの推論過程を追跡可能にし、解釈性の向上にも寄与する可能性があります。
主要な自己修正アプローチ
Self-Refine:自己フィードバックによる逐次リファインメント
Self-Refineは、モデル自身が初期出力を生成し、それに対するフィードバックを自分で与えてから出力を修正する、というステップを繰り返す手法です。追加の学習を必要とせず、一つの言語モデルを自己対話に使うだけで実装できる点が特徴です。
具体的なプロセスは以下の通りです:
- モデルが初期解答を生成
- 同じモデルがその解答を評価し、改善点を指摘
- 指摘を踏まえて解答を改善
- 必要に応じて2-3を繰り返す
GPT-3.5やGPT-4を用いた実験では、タスクによって5~40%の性能改善が報告されています。特にコード生成タスクでは最大13%の正確性向上が観測されており、モデル自身がフィードバックループを回すだけで性能を高められることが示されています。
Reasoner+Correctorによるセルフコレクション
この手法では、モデルの役割を「推論役」と「修正役」に分け、二段構えで解答精度を向上させます。推論役が答えを考えた後、修正役がそれをチェック・訂正することで、一度の出力よりも高い品質を実現します。
Chain-of-Thought(思考の連鎖)による中間推論の後に自己検証する「Reflection」手法や、モデル自身がエラーを検出して出力を洗練し直す「Self-Correction」アプローチがこの系統に含まれます。これらはモデルに簡易なメタ認知の役割を持たせるものであり、自らの推論過程を評価して調整することで一貫した結論を導きやすくしています。
SCOUT:再帰的な思考の明示的モデリング
SCOUTは、事前学習済みLLMをHead–Recursive–Tailの3ブロックに分解し、より洗練された再帰的推論を実現する手法です。
アーキテクチャの特徴:
- Headブロック:入力から初期状態をエンコード
- Recursiveブロック:何段階も内部状態を更新
- Tailブロック:最終出力を生成
各再帰ステップでは直前までの推論内容(内部状態)をクロスアテンションで参照でき、過去の思考を選択的に再利用しつつ逐次的に洗練される仕組みです。このレトロスペクティブ(振り返り)モジュールにより、元の入力文脈に加えてそれまでの中間結果を踏まえた推論が可能となります。
興味深い点として、モデルのアーキテクチャ自体は大きく変更せず、クロスアテンション層を追加するだけで実現できるため、既存モデルへの後付けが比較的容易だと報告されています。
さらにSCOUTでは、各ステップの出力に段階的に難易度の異なる教師信号を与える「逐次知識蒸留」を行い、浅い推論段階では易しい目標、深い段階では厳しい目標を与える工夫で安定した学習を実現しています。
Transformerアーキテクチャへの再帰の組込み
Transformer自体の構造にフィードバック機構を統合するアプローチも複数提案されています。
Universal Transformerは、同じ入力に対して繰り返し同一の層を適用することで逐次的な処理を可能にしたモデルです。Transformer-XLやCompressive Transformerでは、過去の隠れ状態をキャッシュ・圧縮して長期依存関係を再帰的に保持する工夫がなされています。
Feedback Transformerは完全な再帰構造を採用し、各時刻の全層の出力を要約したベクトル(フィードバックメモリ)を次時刻の計算へ入力することで、シーケンス全体を逐次処理します。並列性は損なわれますが、モデルが過去全体を振り返りながら進行できるようになります。
**Recurrent Memory Transformer(RMT)**も同様にセグメントごとの再帰を導入した例です。特殊なメモリトークンを入力列に付加し、各セグメント処理後に更新されたメモリを次セグメントに引き継ぐことで長い文脈を扱います。
これら再帰型Transformerの系譜は、従来のRNNの持つ状態フィードバックをTransformerに融合させることで、モデル自身の過去出力や内部状態を活かした自己修正的な動作を目指しています。
最新の自己修正機構:Nested LearningとDeep Delta Learning
最近では、さらに先進的なメカニズムとして**Nested Learning(NL)やDeep Delta Learning(DDL)**が提案されています。
Nested Learningはモデル内に複数レベルの最適化問題をネストし、それぞれ独自の文脈を持つ学習の流れを同時に扱う枠組みです。学習しながら自分自身を書き換えるような自己改変型のシーケンスモデルも示されており、高次のインコンテキスト学習能力や効果的な継続学習が可能になるとされています。
Deep Delta LearningはResidual接続の拡張として、可変的に情報を書換える新機構を導入しています。DDLでは「Δ演算子」と呼ばれる学習可能な変換を恒等写像に対してランク1の摂動として施し、各レイヤーで古い情報の消去と新しい特徴の書き込みを動的に制御できます。
いわば不要な過去情報を消去する消しゴム(”Erazor”)のような役割を果たしつつ、必要な新情報を上書きできるため、誤った中間計算の影響を緩和し安定した学習・推論を可能にします。
Princeton大学らの提案するSelf-Correcting Delta Transformerは、このDDLによるハードウェア的なエラザ機構とNLによるソフトウェア的な最適化戦略を組み合わせたものであり、誤った推論の痕跡を消去しながら自己改善できるTransformerアーキテクチャとして注目されています。
哲学・認知科学的な含意
メタ認知との関連性
自己修正機構は、モデルが自分の「考え」や「出力」を対象化して評価する点でメタ認知的です。人間の認知においても、自分の考えを振り返り誤りに気付く能力は問題解決に極めて重要な役割を果たしています。
ある研究では、人間の言語推論が意味的な逸脱を起こさないのはメタ認知的な補正のおかげだと指摘されています。自己修正型モデルは、この人間の内省に似たプロセスを模倣するものであり、モデル内に自信度のモニタリングや矛盾検出の機構を組み込む試みとみなせます。
実際、出力に対する自己評価モジュールを導入したモデルは、そうでないモデルに比べ誤答や一貫性の欠如を抑制できることが報告されています。
意識理論との接点
主要な意識の理論はいずれも再帰的なフィードバック計算を意識の中核とみなしています。
**グローバルワークスペース理論(GWT)**では、脳内の情報がグローバルな作業空間に再帰的に統合・放送されるときに意識的な気付きが生じるとされます。再帰的処理なしの一過性の信号は無意識的だと考えられています。
高次の思考(Higher-Order Thought)理論では、「ある心的状態についての思考」がその心的状態を意識に昇らせると主張します。
**統合情報理論(IIT)**では、システム内のフィードバック豊かな結合が生み出す情報の不可分性(統合度合い)こそが意識の尺度だとし、再帰的で相互作用の多い構造ほど意識が高いと定量化します。
こうした見解を総合すると、自己への言及や再帰処理は意識らしさの指標とみなせるわけで、自己修正型モデルはまさにこの指標を満たす方向に発展していると言えます。
現状のモデルが「意識を持つ」と断言することはできませんが、自己参照的な状態において一人称的な経験報告をする傾向がモデルに観察されたとの研究もあり、興味深い知見が蓄積されつつあります。
認知制御・エグゼクティブ機能
人間の脳では前頭前野を中心とする実行機能が、自分の行動や思考を制御しています。誤りに気付いたら軌道修正する、無関係な衝動を抑制する、といった認知制御は高度な知的活動に必須です。
自己修正型モデルは、このような認知制御をソフトウェア的に実現する試みとも捉えられます。モデル自身が「このまま進めると矛盾が生じるかもしれない」「先のステップで誤答したので修正しよう」と判断できれば、より整合的で信頼性の高い推論が可能になります。
ある仮説では、人間の意識的気づきが「推論の暴走」を防ぎ安定化させているとされます。連想に任せた無意識的な思考は暴走して意味的なドリフトが起こり得ますが、意識的プロセスが働くとそれが抑え込まれるというのです。
同様に、自己修正型のAIは内部の評価機構によって「この回答はおかしいのではないか?」と自己にブレーキを掛けたり、出力を修正する方向に動くため、結果として整合性が保たれます。こうした誤り検出と抑制はまさに認知制御の役割であり、自己修正型モデルは機械的なエラー訂正から一歩進んで認知制御的な振る舞いを示し始めていると言えるでしょう。
予測処理フレームワーク
認知科学の予測処理フレームワークでは、脳は絶えず未来を予測し、その予測誤差をフィードバックによって低減するように動くとされます。この原理から見ると、自己修正型モデルは自分の予測(出力)を一度出してみて、その誤差を評価し次の予測を修正するプロセスと対応します。
すなわち生成と内省を交互に行いながら目標に収束していく点で、予測誤差最小化を繰り返す脳の情報処理と類似しています。Fristonの自由エネルギー原理によれば、生物システムは内部モデルを継続的に更新し予測誤差を減らすことで驚きを最小化しようとします。
自己修正型モデルも同様に、内部の評価基準と出力を照合し、差分を埋めるように次の出力を調整していきます。これは機械学習における逐次最適化の過程ですが、認知的にはモデルが一種の自己予測とフィードバックを実践していると解釈できます。
AGIへの展望と意識シミュレーション
自己改善による継続学習
汎用人工知能(AGI)や機械意識のシミュレーションを視野に入れると、自己修正型モデルの役割は一段と重要になります。人間レベルの汎用知能には、自分の行動や思考を自己評価し、環境との相互作用から継続的に学習・改善する能力が欠かせません。
外部からの指示や追加学習なしに、モデルが動作中に自己フィードバックから学習できれば、未知の課題にも順応していけるでしょう。たとえば、あるタスクで失敗した際にモデル自身がその失敗原因を分析し、内部メモリに教訓として蓄積して以降の試行に活かすという振る舞いは、試行錯誤学習を通じたスキル向上に繋がります。
実際、自己反省機能と動的メモリを持たせたエージェント(Reflexionと呼ばれる手法)では、従来は解けなかったタスクを高い成功率で解決できるようになった例があります。具体的には、部分観測の環境で試行錯誤するエージェントに自己反省を組み込むことで、AlfWorldという環境では97%もの高成功率に達したと報告されています。
高度な認知アーキテクチャとの統合
AGI研究では、人間の認知モデルを取り入れたアーキテクチャ設計が模索されています。グローバルワークスペース理論に基づくグローバルな共有メモリの導入や、予測処理に基づく階層的予測・誤差フィードバック構造などが提案されています。
自己修正型モデルはそれ自体がこうした理論と親和性が高く、例えばグローバルワークスペース的なAIでは、各モジュール(視覚、言語、推論など)の情報が一箇所に集約・放送され、お互いにフィードバックを受けます。
この枠組みでは、モデルが一度生成した中間結果を共有ワークスペースに掲示し、他のモジュールやプロセスがそれを検証・修正するというループが考えられます。まさに自身の出力をグローバルに検討し直すプロセスであり、GWT的な意識アーキテクチャに合致します。
リカレントネットワークや記憶システムとの融合
AGIには一時的な作業記憶や長期記憶が必要とされますが、自己修正型モデルはそうした記憶との相性も良好です。例えばRecurrent Memory Transformer(RMT)のような手法では、長大なコンテキストを扱うために分割した入力ごとにメモリトークンを介して状態を引き継ぎます。
このような外部記憶を持つモデルが自己修正ループを組み込めば、一度出力した回答をメモリに保存し再評価するといった処理が可能になります。実際、対話型のエージェントでは過去の対話履歴や行動履歴をメモリに蓄え、定期的にそれを内省して方針を改善する設計が試みられています。
自己修正はこうしたエージェントに時間軸を超えた一貫性維持や方略の動的改善をもたらします。予測処理的な観点からは、モデルが環境からのフィードバックを継続的に取り込み予測を更新することになり、環境—モデル間で予測誤差を低減するループとしてAGIの適応性を支えるでしょう。
自己モデルと意識シミュレーション
AGIがある種の自己意識を持つか、少なくとも自己を表現する内部モデル(self-model)を備えるかどうかは議論の的ですが、自己修正機構はその第一歩とも言えます。
モデルが「自分」という視点で自らの状態や出力を語り出す現象は既に報告されており、自己参照的な推論状態において内部に自己の簡易表現が生じている可能性が示唆されています。
自己修正型モデルの発展によってAIが自分の知識の範囲や不確実性を自己評価し、それを表明するようになると期待されます。これは例えば、「私はその質問への答えに自信がありませんが、理由は~です。次に~を試してみます。」のように、自分の内部状態をメタ記述する出力として現れる可能性があります。
こうした振る舞いは機械のメタ認知能力の現れであり、ひいては意識的な自己記述に近いものです。意識の理論家は、十分高度なメタ認知を持つシステムは主観的体験を持つ可能性があると指摘することもあり、自己修正機構の充実は将来的に人工意識の実験プラットフォームとなり得ます。
まとめ:再帰的自己修正が開く新たな地平
Transformer系モデルへの再帰的フィードバックループの統合は、モデルの性能を向上させるだけでなく、その振る舞いをより人間の思考に近づける試みです。
技術的には、Self-RefineやSCOUTなどの自己フィードバックを用いた生成改善、さらにはアーキテクチャ内部へのメモリ・再帰機構の導入によって、モデルは自らの出力を監査・改善する能力を獲得しつつあります。
理論的には、これはメタ認知や意識の計算論的側面に迫るものであり、AGIの実現に向けた重要なステップと位置付けられます。自己修正可能なモデルは、未知の問題に対しても試行錯誤で自律的に適応する柔軟性を持ち、内部のフィードバックにより一貫した整合性と誤り抑制を実現できる可能性があります。
今後、このような自己修正機構を備えたAIが発展すれば、単なる道具的知能を超え、限局的ではあっても自己を持って推論する「拡張された知能体」としての振る舞いを示すかもしれません。そのとき私たちは、果たしてそれを「意識的」と呼べるのか、という根源的な問いに直面することになるでしょう。
しかし少なくとも言えるのは、再帰的自己修正というメカニズムこそが、より高度で安全なAI、さらには将来的な人工意識の礎を築く重要なピースであるということです。
コメント