なぜ今、自己生成データの継続学習が問題になるのか
大規模言語モデルや生成AIの普及により、AIシステムが自ら生成したデータを次世代の学習に再利用するサイクルが実務環境でも当たり前になりつつある。これは一見、ラベルコストを削減しながら学習データを増やせる魅力的なアプローチに見える。しかし、自己生成データ(Self-Generated Data:SGD)を継続学習(Continual Learning)に組み込む際には、「モデル崩壊(Model Collapse)」「確認バイアス(Confirmation Bias)」「データフィードバックループ(Data Feedback Loop)」という三つの複合的な失敗モードが潜んでいる。
本記事では、これらの失敗モードの理論的背景を整理したうえで、実務で機能する品質保証(QA)メカニズムと評価プロトコルを体系的に解説する。スーパー決定論(Superdeterminism)が示す「独立性仮定の脆さ」という哲学的視点も交えながら、AIシステムの長期的信頼性をどう設計するかを考えていく。
自己生成データとは何か:SGDの5つの類型
「自己生成データ」と一口に言っても、その実態はいくつかの類型に分かれる。実務的には以下の5種を総称として扱うのが有効だ。
まず「自己収集」は、モデルの推薦や応答がユーザ行動を変えることで得られるログデータを指す。次に「合成データ」は、シミュレータやルールベースの生成器が作り出すもの。「生成モデル産物」はLLMや拡散モデル、GANなどが出力したコンテンツそのものである。「擬似ラベル(Pseudo-label)」は、モデルが未ラベルデータに自らラベルを付けたもの。そして「生成リプレイ(Generative Replay)」は、過去データを保持せずに生成で再現するアプローチだ。
これら全てに共通するのは、「データの生成過程にモデル自身が関与している」という点であり、これが後述する失敗モードの根本原因となる。
モデル崩壊の理論的背景:動的系として捉える
SGD継続学習は「最適化問題」ではなく「動的系」
従来の機械学習では、学習データの分布は固定されていて、モデルはその分布に対して最適化を行うという前提があった。しかしSGDを継続学習に取り込む場合、この前提が根本的に崩れる。
研究では、世代 i のデータセットから学習したモデルが次世代データ分布を作り出すプロセスを、以下の混合モデルとして定式化している。
pᵢ₊₁ = αᵢ p_{θᵢ₊₁} + βᵢ pᵢ + γᵢ p₀
(αᵢ + βᵢ + γᵢ = 1)ここでγᵢは「本物の原分布 p₀へのアクセス」を意味する。このγが小さくなる(あるいはゼロになる)と、確率的に希少な事象が有限サンプルのなかで消えていき、世代を超えて情報が失われていく。これが「モデル崩壊」の本質だ。
Early Collapse と Late Collapse
モデル崩壊には段階がある。初期段階(Early Collapse)では、分布の裾(tail)にある低確率事象が訓練サンプルに出現しにくくなり、モデルがその事象を再現しなくなる。これが繰り返されると、後期段階(Late Collapse)では元の分布と著しく異なる低分散な分布へ収束してしまう。
重要なのは、この崩壊が「理論上は理想的な条件でも不可避になり得る」点だ。有限サンプルによる統計誤差だけでも、離散化(有限精度)を通じて吸収状態へ収束する可能性がある。つまり、サンプル数を増やすだけでは根本解決にならない。
Replace と Accumulate:崩壊の条件を設計変数化する
合成データの使い方として、「本物を合成で置換する replace」と「本物を保持して合成を蓄積する accumulate」では、挙動が質的に異なることが複数の研究で確認されている。前者(replace)は世代的劣化へ向かいやすく、後者(accumulate)は崩壊しにくい傾向がある。
ただし、accumulateもデータの肥大化や計算予算の固定という制約のなかでは別の問題を引き起こす可能性がある。実務では「固定計算予算のもとでaccumulateが安定するか」という中間シナリオの分析が重要になる。
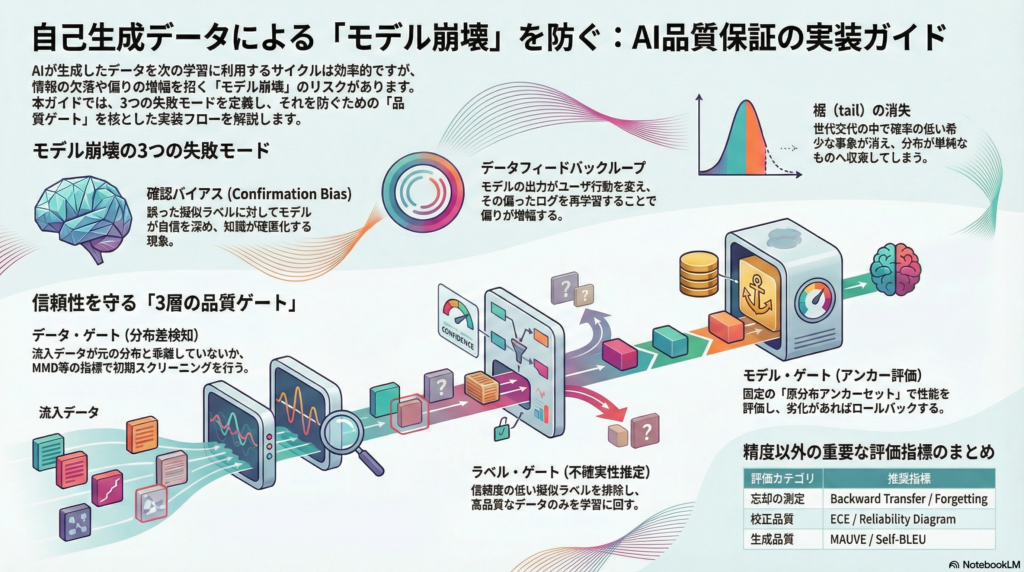
三つの主要な失敗モード
失敗モード①:確認バイアス(Pseudo-label Confirmation Bias)
擬似ラベルによる自己訓練では、誤ったラベルがついていてもモデルの確信度(confidence)が上昇し続けることがある。これにより「変化に抵抗する硬直化したモデル」が生まれ、新しい知識の習得が妨げられる。
対策として有効なのは、mixupなどの正則化手法の組み合わせ、自己訓練のスケジューリングや再初期化、そして確信度閾値をカリキュラム的に引き上げるアプローチだ。
失敗モード②:データフィードバックループによる偏り増幅
運用中のモデルがデータ生成過程そのものを変えてしまうことで、偏りが増幅していくループが形成される。例えば、推薦システムがユーザの行動を変え、その行動ログが次のモデル学習に使われると、特定の偏向が継続的に強化されていく。
理論的には、学習アルゴリズムの安定性と「faithfulness(出力が入力分布をどれだけ忠実に反映するか)」によって増幅の上界が与えられる可能性があるが、実務的にはこのループを設計段階でコントロールすることが求められる。
失敗モード③:分布シフトと壊滅的忘却の同時進行
継続学習において過去タスクの性能が急速に低下する「壊滅的忘却(Catastrophic Forgetting)」は古典的な課題だ。正則化手法(EWC、SI)、機能正則化(LwF、DER)、リプレイ(経験再生)などが対策として提案されてきた。
しかしSGDが組み込まれると、忘却対策に必要な情報自体が生成物由来で劣化し得るため、「忘却対策が崩壊対策を兼ねない」という状況が生じる。これら二つの問題を別々に扱う設計が必要になる。
品質保証(QA)メカニズムの多層設計
「品質ゲート」という考え方
品質保証を単なる監視ではなく「機構(メカニズム)」として機能させるためには、学習ループに「ゲート(通行規制)」を組み込むことが重要だ。実務的には少なくとも以下の3段階にゲートを設置する必要がある。
データ・ゲート: 分布差検知(MMD、C2ST、DetectShiftなど)を使って、明らかに別の分布に属するデータを検知・隔離する。ラベルなしで実施できる場合もあり、初期スクリーニングとして有効だ。
ラベル・ゲート: 校正済み確率と不確実性推定(温度スケーリング、アンサンブル、MC Dropoutなど)を用いて擬似ラベルの採否を決める。未知クラスの混入(オープンセット問題)を疑う姿勢も重要だ。
モデル・ゲート: 固定の「原分布アンカー評価セット(tail監査セット)」を用意し、時系列評価(事前順次評価:Prequential Evaluation)で性能・校正・バイアス指標の劣化を早期検知してロールバックできる体制を整える。
推奨ワークフロー
検証パイプラインの概念的な流れは以下のようになる。
[データ流入] → [分布差スクリーニング] → [ラベル生成] → [ラベルQA(校正+不確実性)]
→ [継続学習トレーニング] → [固定アンカー評価] → [デプロイ]
→ [運用監視(ドリフト検知)] → [次サイクルへ]重要なのは、各評価段階が「次サイクルへの入力を制御するアクション(採用/排除/ロールバック)」に直結している点だ。評価が報告で終わっていては、品質保証として機能しない。
評価指標の選び方:精度だけでは見落とす崩壊の兆候
SGD継続学習において精度指標のみに依存することは危険だ。裾の消失、校正崩壊、偏り増幅、シフト下での劣化は、全体精度が維持されている段階では見えにくい。以下の指標カテゴリを組み合わせることが推奨される。
継続学習の忘却を測るには「Backward Transfer / Forgetting」、校正品質には「NLL・ECE・Reliability Diagram」、不確実性とOOD検知には「アンサンブル分散・MC Dropout分散」、入力分布の差には「MMD・C2ST・DetectShift」、生成品質(テキスト)には「MAUVE・Self-BLEU」を活用する。ドリフト検知の性能自体も「検知遅延・誤報率・見逃し率」で評価する必要がある。
実験プロトコル:世代ループでの崩壊再現
崩壊の再現と防止策の効果比較には、次のような実験設計が有効だ。各世代でモデル生成データ・前世代データ・原分布データの混合比(α、β、γ)を操作変数として変える「世代ループ実験」を行う。また、希少事象を意図的に含む「tail監査セット」を固定しておき、Early Collapseを世代の早い段階で検出できるようにする。
さらに、フィードバック実験として新規データの一部をモデル注釈と人手注釈に分け、偏り増幅の速度がその比率やモデルの安定性にどう依存するかを照合することも有益だ。
スーパー決定論が教えるAI実験の独立性仮定の脆さ
スーパー決定論(Superdeterminism)は量子力学の基礎論における立場であり、「測定設定と隠れ変数の統計的独立性(Measurement Independence)が破れる」ことで局所実在論を維持しようとするものだ。この概念は一見、機械学習とは無縁に見えるが、実験設計の哲学として重要な示唆を持つ。
機械学習実験の多くは、訓練・検証・テスト分割やA/Bテストの割り付けが「外生的(独立)」であることを暗黙に仮定している。しかし実務では、データ収集装置・推薦システム・欠測機構が入力分布を変形し、隠れた要因と相関し得る。これはまさに「測定設定(どのデータを観測するか)が観測対象と相関する」状況であり、独立性仮定が揺らぐ場面だ。
ベル実験において宇宙光子を使って設定生成の過去光円錐を押し戻す「コズミック・ベルテスト」の試みは、「仮定をどこまで押し戻せるか」という工学の姿勢を示している。SGD継続学習への示唆は明確だ。「設定(データ収集・ラベル付け・学習更新のトリガ)が隠れ因子と相関しても破綻しないQA設計」を目指すこと、つまり原分布アンカーの確保・分布差検知・ロールバック可能な評価は、哲学的な意味でも現実的な防御になる。
まとめ:単一の「強い手法」に賭けない多層QAスタック
自己生成データを継続学習に活用する際に重要なのは、モデル崩壊・確認バイアス・フィードバックループという三つの失敗モードを「動的系」として理解することだ。static な最適化問題として捉えてしまうと、適切な防止策の設計ができない。
実務的な結論は、「(A) データ生成・選別の段階で誤りの流入を抑える、(B) 学習アルゴリズム側で忘却と誤学習を抑える、(C) 評価・監視でドリフトと崩壊の兆候を早期検知してロールバックできる」という多層の品質保証スタックを構築することだ。accumulateベースの設計、tail監査セットの固定、prequential評価の導入、そして人手介在(HITL)の戦略的配置が、長期的なシステムの信頼性を支える柱になる。
コメント