自己修正機構とは何か――再帰的フィードバックが生む設計課題
現代の制御システムや機械学習の多くは、観測された誤差をもとにパラメータや制御入力を逐次更新する「自己修正機構」を内包している。PIDコントローラの積分項、適応フィルタのLMS更新則、強化学習のQ値更新、ニューラルネットワークの確率的勾配降下法――いずれも根本的には同じ構造を持つ。誤差信号を閉ループに取り込み、自らを修正し続ける動的システムだ。
この機構が正しく機能すれば、未知の環境変化やパラメータ変動に対してロバストに追従できる。しかし設計を誤ると、「修正のはずが増幅」という正帰還に転じ、状態が発散する。自己修正機構の安定性と収束性は、制御工学・機械学習・AIシステム設計を横断する核心的な問題である。
本記事では、理論的な安定条件(リヤプノフ法・ISS・小ゲイン定理・確率近似)を整理したうえで、適応制御・強化学習・深層学習における実装上の落とし穴と設計指針を解説する。
理論の基盤――拡大状態で安定性を捉える枠組み
物理状態と学習状態を合わせた「拡大状態」
自己修正機構の分析で最初に重要なのは、物理状態 x と学習・推定パラメータ θ を分けて考えるのではなく、拡大状態 z=(x,θ) として一体的に扱うことだ。制御ループと学習ループの相互依存関係を明示的にモデル化することで、安定性・収束性の議論を通常の動的システム理論に落とし込める。
離散時間なら zk+1=F(zk,rk)、連続時間なら z˙(t)=F(z(t),r(t)) の形で表現し、r は外乱・ノイズ・参照入力・遅延による誤差などの外生信号をまとめる。この枠組みにより、「制御が安定しているが学習が発散する」「学習は収束しているが制御ループが不安定」といった片面的な失敗を見落とさない設計が可能になる。
安定性の定義――内部安定と外部安定の両立
安定性には大きく「内部安定」と「外部安定」の二軸がある。
内部安定は状態が有界・収束することを意味し、基本的には平衡点 z∗ 近傍でのリヤプノフ的な安定性定義に対応する。漸近安定では ∣z(t)−z∗∣→0(t→∞)が求められ、指数安定ではこの収束が指数的に速いことが保証される。
外部安定はBIBO安定(有界入力に対し有界出力)やL2ゲイン有限性として定式化され、センサノイズや外乱が入力として入ってきたとき、それが出力側で無限に増幅されないことを保証する。連続時間LTI系ではインパルス応答 h(t) の絶対可積分性がBIBO安定の同値条件である。
自己修正機構を扱う際、この両面を同時に保証することが実務上の核心となる。内部的に収束していても外乱が入力ゲインを通じて増幅されれば、実システムでは発散に近い挙動を示す場合があるからだ。
安定化のための三大理論的ツール
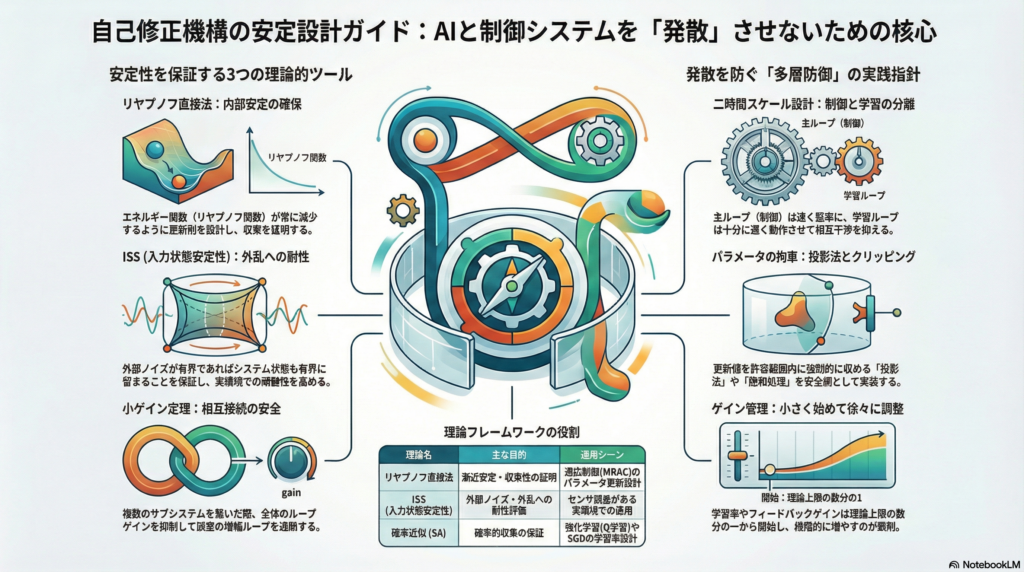
リヤプノフ直接法と不変原理
非線形系の安定性判定で最も汎用的なのがリヤプノフ直接法だ。正定関数 V(x) が存在し、その時間微分 V˙(x) が負定であれば漸近安定が保証される。
ただし V˙≤0(半負定)の場合、点収束ではなく不変集合への収束になる可能性がある。ここで威力を発揮するのがラサールの不変原理だ。V˙=0 を満たす集合の最大不変集合へ軌道が収束することを示すことで、厳密な負定性が得られない場合でも収束先を特定できる。
自己修正機構では、パラメータ更新則とリヤプノフ関数を同時設計する手法がMRAC(モデル規範型適応制御)などで広く用いられる。誤差に基づく更新を「V を減少させる方向」に設計することで、パラメータが有界に留まり、追従誤差が収束することを証明する枠組みだ。
ISS(入力状態安定性)と外乱への耐性
現実の自己修正機構は常に何らかの外乱・ノイズにさらされる。この状況を扱う強力な枠組みがISS(Input-to-State Stability)だ。
x˙=F(x,w) がISSであるとは、β∈KL、κ∈K が存在して ∣x(t)∣≤β(∣x0∣,t)+κ(∥w∥∞)
が成立することを意味する。直感的には「外乱がゼロに近づけば状態も平衡に近づく」「外乱が有界なら状態も有界」という性質だ。
ISSは専用のISSリヤプノフ関数の存在と同値であることが証明されており、設計と解析の両面で使いやすい。具体的には V˙≤−α(∣x∣)+γ(∣w∣) という形の条件がISSリヤプノフ条件に相当し、比較原理でISS評価式を導出できる。
小ゲイン条件――相互接続が発散しない条件
複数のサブシステムが相互に接続された自己修正機構では、各サブシステムが個別に安定であっても、接続することで互いの誤差を増幅し合い全体が発散するリスクがある。
この問題に対処するのが小ゲイン定理だ。各サブシステムがISS/IOS型のゲイン評価を持つとき、ゲインの合成が「縮小写像」になる条件(非線形ゲイン関数の合成が恒等写像を下回る)が相互接続全体のISSを保証する。古典的なLTI版では「ループゲイン<1」という形に帰着し、非線形・時変・遅延を含む系への拡張が現在も研究されている。
適応制御・学習系における安定性の落とし穴
LMSの安定域と学習率設計
適応フィルタのLMS(最小二乗平均)アルゴリズムは、タップ係数 w(n) を w(n+1)=w(n)+μu(n)e(n)
で更新する。ステップサイズ μ が安定性と収束速度のトレードオフを支配し、安定のためには入力自己相関行列の最大固有値 λmax に対して 0<μ<λmax2
という条件が必要だ。λmax が未知の実運用では trace(R)(自己相関行列のトレース)を代替として用いる経験則が広く使われる。
μ が大きすぎると、誤差に比例した更新が誤差を増幅する正帰還に転じ、係数が発散する。一方で μ が小さすぎると収束が遅く、非定常環境への追従性が落ちる。この二律背反は自己修正機構に普遍的に現れる問題だ。
適応制御のバースト現象と頑健化
適応制御の理論的成果として知られているのは、プラントが正確にモデル化されていれば収束が保証されるという点だ。しかし実際には、未モデル化ダイナミクスや測定ノイズが存在するとき、バースト的な不安定現象が起こり得ることが報告されている。
頑健化の手法として代表的なのが、投影法(パラメータを許容集合に射影する)、σ修正(更新則に正則化項を加える)、平均化法(高周波成分の影響を平滑化する)などだ。特に投影法は実装が容易で、パラメータ漂流(drifting)を防ぐ直接的な手段として広く採用される。
強化学習における収束と発散の境界
表形式Q-learningについては、状態・行動が十分に探索される条件と学習率条件の下で確率1収束が証明されている。具体的にはQk+1(sk,ak)=Qk(sk,ak)+αk(rk+γa′maxQk(sk+1,a′)−Qk(sk,ak))
という更新則が、確率近似の枠組みの下で最適Q値に収束する。
しかし、オフポリシー学習と関数近似を組み合わせたTD学習では、理論的な収束保証がない状況が存在し、発散する反例が知られている。「自己修正している=収束する」という直感は強化学習では必ずしも成立しない点に注意が必要だ。この問題に対処するため、勾配TDなど安定性を考慮したアルゴリズム設計や、二時間スケール解析を用いたアクタークリティックの安定解析が研究されている。
確率近似の収束定理――学習率スケジュールの理論的根拠
確率的な観測誤差を含む更新則は確率近似(SA)の枠組みで扱われる。古典的な結果では、ステップ列 {an} が n=1∑∞an=∞,n=1∑∞an2<∞
を満たすとき(典型例:an∼1/n)、適切な仮定の下で収束が保証される。
収束証明の鍵は、期待値が減少するリヤプノフ関数の列が「ほぼ超マルチンゲール」になることを示し、超マルチンゲール収束定理でほぼ確実収束を結論する点だ。これはSGD・Q-learning・適応フィルタ全般に共通する収束議論の骨格であり、「なぜ学習率を徐々に下げるべきか」の理論的根拠でもある。
一定の学習率では定常誤差(ミスアジャストメント)が残り、完全収束しない代わりに非定常環境への追従性が維持される。減衰学習率では完全収束するが、非定常環境への適応力が失われる。この設計トレードオフは応用ごとに判断が必要だ。
多層防御の設計指針――発散を防ぐ実践的アプローチ
主ループとサブループの分離設計
自己修正機構の実装で失敗しにくいアーキテクチャは、制御ループ(主ループ)と学習ループ(サブループ)を明確に分離し、それぞれに異なる安定化戦略を適用することだ。
主ループはロバスト制御や極配置など確立した手法で堅く安定化する。学習ループは主ループに対して十分遅い時間スケールで動作させ、かつ更新量を投影・クリッピング・正則化で制限する。この二時間スケール設計により、学習中に主ループが不安定化するリスクを構造的に低減できる。
ゲインは「小さく始めて徐々に増やす」
パラメータ選定の実践的経験則として、更新ゲイン(学習率・適応ゲイン・フィードバックゲイン)はまず理論的上限の数分の一から始め、段階的に増やしていくアプローチが有効だ。1ステップで状態やパラメータが大きく飛ぶ設計は、理論的に安定でも数値計算上の問題や未モデル化要素との干渉で発散につながりやすい。
飽和・クリッピング・アンチワインドアップはハード的な有界性を保証し、ISSの観点では外乱に対する影響を抑える役割も果たす。これらを「安全網」として設計段階から組み込むことが推奨される。
安全マージンとガバナンスの観点
継続学習や自己修正を含むAI・自律システムでは、技術的な安定条件に加え、「どの状況で学習を停止するか」「逸脱を検知したとき安全側へ退避するか」を仕様化し、運用監視と連動させることが重要だ。ISO/IEC 42001(AIマネジメントシステム)やISO/IEC 23894(AIリスク管理)、IEC 61508(機能安全)などの規格は、組織的にこのリスクを扱う枠組みを提供している。技術的な収束証明だけでなく、実運用での監視・介入ループを設計に含めることが、実システムの信頼性につながる。
まとめ――自己修正機構を「発散させない」設計の核心
自己修正機構の安定性と収束性は、拡大状態(物理状態×学習状態)を一体として扱い、内部安定と外部安定の両面を確保することが出発点だ。理論的には、リヤプノフ直接法・ISS・小ゲイン条件・確率近似の四つの枠組みが補完的に機能し、線形・非線形・確率的・相互接続型の各設計状況に対応する。
実装上の核心は「ゲインを小さく保つ多層防御」であり、投影・正則化・学習率減衰・飽和処理の組み合わせが発散を防ぐ実践的な第一歩となる。適応制御のバースト現象や強化学習の関数近似での発散反例が示すように、「修正している=安定」という直感は成立しない場合がある点に常に注意が必要だ。
コメント