松岡正剛の「38の型」が注目される理由
情報が溢れる現代において、「どう考えるか」の構造そのものを鍛える需要が高まっています。松岡正剛が主宰する編集工学研究所が運営するイシス編集学校では、「思考(情報編集)には型がある」という立場から、38の編集稽古(お題) を通じて情報処理の型を体系的に学ぶ仕組みが設計されています。
この「38型」は単なる発想トリックの羅列ではなく、「情報を収集→関係づける→構造化する→表現へ落とす」 という四つの用法(プロセス)に整理された体系です。そしてこの体系は、ChatGPTをはじめとする大規模言語モデルとの相性が非常に高い可能性があります。型が明確なほど、プロンプト設計も明確になるからです。
本記事では、38型の概要と四つの用法区分、各用法に対応するChatGPT最適化プロンプトの設計原則、そして評価(ベンチマーク)設計の考え方までを整理します。
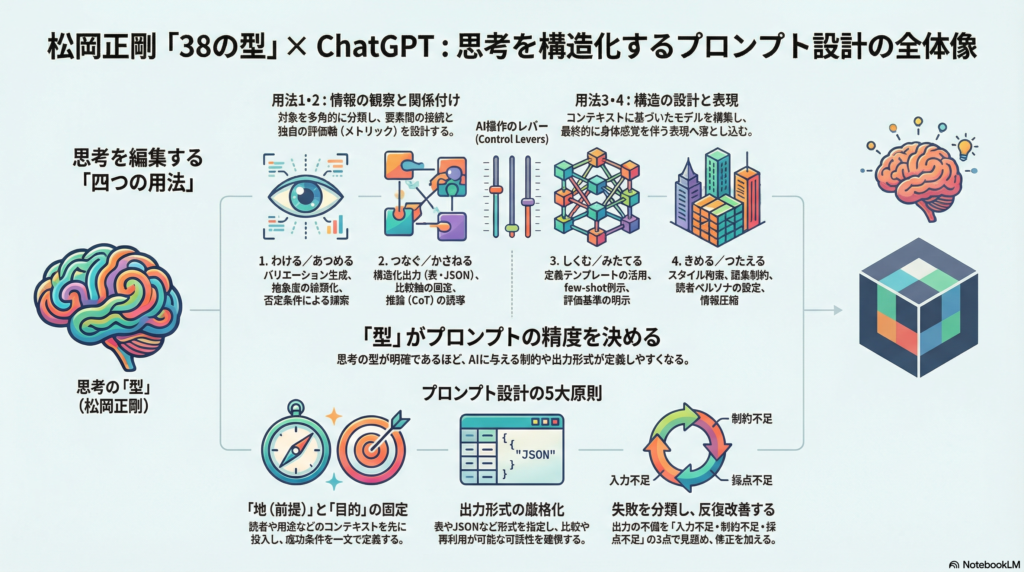
38型の基本構造:四つの用法とは
用法1「わける/あつめる」:観察と分類の訓練
用法1(001〜010番)は、物事を多角的に観察し、分類軸を立てるための型群です。主な操作は「注意のカーソルを動かす」「地と図を切り替える」「否定条件で探索空間を広げる」の三つです。
代表的な型として次のものがあります。
- 001「コップは何に使える?」:対象を情報として捉え直し、抽象度を段階的に変えながら多層に言い換える稽古。具体物→用途→カテゴリ→機能→メタ概念と五段階で展開することで、発想の射程が広がります。
- 004「地と図の運動会」:同じ情報(図)でも、背景(地)を変えると意味が変わることを体験的に学ぶ型。コンテキストを変数として扱う思考力を養います。
- 007「ラベリング・トラベリング」:自由な分類軸を立て、2分類・3分類で整理する型。「なぜそう分けるのか」という軸の設計力が問われます。
ChatGPTへの応用では、「バリエーション生成」「粒度(抽象度)の段階化」「否定条件による探索空間の拡大」が主な操作レバーとなります。
用法2「つなぐ/かさねる」:関係と測度をつくる
用法2(011〜019番)は、バラバラな要素を接続し、関係線と測度(メトリック)を生み出す型群です。「三位一体・三間連結」「一種合成」「二軸四方」「スコアリング」「層の重ね合わせ」などが含まれます。
- 011「ジャンケン三段跳び」:三間連結(A→B→Cの3段変化)と三位一体(対等な3点)の二つの「3の構造」を取り出す型。整理・説明・計画の場面で活用できます。
- 014「喜怒哀楽を老若男女」:二軸四方(直交座標系)でメトリックを設計する型。二つの軸を定義し、4象限に意味を与えることで、評価設計や意思決定に使えるフレームができます。
- 015「マンガのスコア」:「何を測るか」「単位名を何にするか」という測度の発明そのものを稽古する型。数値化の枠組みを設計する力を養います。
- 018「層なんです」:二つの事象のスケール(目盛り)を重ね合わせ、新しいスケールを生み出す型。異分野の概念を接続する際に有効です。
ChatGPTへの応用では、「構造化出力(表・JSON)」「比較軸の固定」「探索→選抜の自己チェック」が重要な操作レバーです。推論が必要なタスクなので、Chain-of-Thought(CoT)的な誘導が有効な場面が多いと考えられます。
用法3「しくむ/みたてる」:定義・モデル・構造を設計する
用法3(020〜029番)は、定義を二層化したり、変化のプロファイルをつくったり、見立てでモデルを構築したりする型群です。もっとも「設計」の色合いが強い用法です。
- 020「コンパイルとエディット」:辞書的な定義(コンパイル定義)と個人的な解釈(エディット定義)を並置する型。「共有可能な根拠」とセットで定義を二層化することで、コミュニケーションの誤解を減らす効果が期待できます。
- 021「秘密基地でBPT」:BPT=ベース(現状)・プロフィール(変化の筋)・ターゲット(到達像)の三点で変化を物語化する型。学習計画やキャリア設計に応用しやすい構造です。
- 019「社長のプロトタイプ」:プロトタイプ(略図的原型)・ステレオタイプ(固定観念)・アーキタイプ(元型)の三層で概念の重層性を捉える型。ブランドや概念設計の場面で活用できます。
ChatGPTへの応用では、「定義テンプレートの活用」「few-shot例示」「評価規準の明示」「誤読防止のための確認質問」が有効です。
用法4「きめる/つたえる」:表現の最終調整と伝達
用法4(030〜038番)は、アイデアや構造を最終的な言葉・表現に落とし込む型群です。「連想シソーラス」「ニューワード」「ネーミング」「文体変換」「オノマトペ」「八段錦(要約)」などが含まれます。
- 030「連想シソーラス」:連想語を「近・中・遠」の距離で層化しながら広げ、描写や新語へ展開する型。連想を深さと広さで制御することがポイントです。
- 031「ようやくニューワード」:キーワード群から新しいホットワードを生み出す手順化された型。生成した新語には定義と用例が必須とされています。
- 034「オノマトペでハイキング」:体験をオノマトペで記録し、言葉を身体感覚に接続する型。「対象→感覚→擬音の対応表」を作ることで、臨場感のある表現が生まれます。
- 038「編集カラオケ八段錦」:素材(文章や歌詞)を8段階に分け、自己組織化の流れとして38型を総復習する型。学習の統合と振り返りに使われます。
ChatGPTへの応用では、「スタイル拘束」「語彙制約」「読者ペルソナの設定」「短文化(情報圧縮)」が主な操作レバーです。
ChatGPT最適化プロンプトの共通設計原則
38型をChatGPTで最大限に活用するためには、型ごとの最適プロンプトを個別設計するだけでなく、用法ごとの共通設計(Prompt Family) を設けることが推奨されます。これにより、プロンプト資産が肥大化しにくく、評価も統一しやすくなります。
全型共通の設計原則は次の五点です。
① 目的を一文で固定する
「何が出れば成功か」を先に書きます。たとえば「分類軸が説明可能であること」「反例がある」「差分が明確」のように、合格条件を事前に決めておくと、モデルが迷いにくくなります。
② 必要なコンテキストを先に投入する
対象・読者・用途・制約を先に示します。38型の用語でいえば「地(前提)」を先に固定することに対応します。地が曖昧なままプロンプトを投げると、出力の意味(図)も定まりにくくなります。
③ 出力形式を固定する
見出し・表・JSON形式など、出力の形式を明示します。比較・評価・再利用のための可読性が高まります。API運用であれば構造化出力(Structured Outputs)による厳格化も可能です。
④ 反復を前提に評価指標を同時に指定する
プロンプトは一発で完成させようとせず、観測→修正を前提に設計します。失敗を「型の失敗」ではなく「制約設計の失敗」として記録し、次の一点だけを変えて再評価するループが推奨されます。
失敗パターンは主に三種類に分類できます。
- 入力不足:コンテキストや前提が足りない
- 制約不足:禁止・優先順位・量の指定が甘い
- 採点不足:何をもって合格とするかが不明
⑤ 推論系タスクには探索→選抜の二段階を明示する
用法2〜3のような論理・構造タスクでは、Chain-of-Thought的な「探索フェーズ」と「選抜フェーズ」を分けて指示することで、出力の一貫性と再現性が向上する可能性があります。自己一貫性の観点からも、探索候補を広げてから制約で絞る設計が有効です。
型別プロンプト設計の具体例
用法1(001)「コップは何に使える?」のプロンプト例
対象「コップ」を"情報"として扱い、言い換えを30個出してください。
条件:
- 抽象度レベルを5段階(具体物→用途→カテゴリ→機能→メタ概念)に分け、各段階6個ずつ
- 重複・類義語だけの水増しは禁止(同じ発想は1回)
- 各案に「なぜその言い換えになるか」を15字以内で添える
出力形式:段階ごとの表評価指標:多様性(カテゴリ数)、重複率、企画への転用可能性 典型的な失敗:類語辞典化 → 対策:抽象度配分と「理由15字」を必須化
用法2(014)「喜怒哀楽を老若男女」のプロンプト例
以下の手順で二軸四方(座標)を設計してください。
1. 軸1・軸2をそれぞれ定義(観測可能な手がかりを含む)
2. 四象限に名前をつけ、各象限の具体例を2つずつ
3. 各象限の「測り方(定量または定性の基準)」を明示
出力形式:軸定義→4象限表→測定基準評価指標:測定可能性、一貫性、軸定義の説明力 典型的な失敗:軸が恣意的 → 対策:定義強制と測定基準の明示
用法3(020)「コンパイルとエディット」のプロンプト例
語「自由」について、以下の二層定義を作成してください。
- コンパイル定義:辞書的・共有可能な定義(根拠を明示)
- エディット定義:個人的な経験に基づく解釈
- 共有可能な根拠:エディット定義が独りよがりにならないための補足
出力形式:二層定義表+根拠欄評価指標:誤読率の低下、納得度 典型的な失敗:エディットが独りよがり → 対策:「共有可能な根拠」欄を必須化
用法4(038)「編集カラオケ八段錦」のプロンプト例
以下の素材(文章)を8段階に分割し、各段階を「編集の動き」で命名してください。
- 各段階に「この段階で使われた型(001〜037のどれか)」を紐づける
- 最後に「8段階を通じて学んだことの統合コメント」を200字で
出力形式:段階番号・命名・対応型・一言要約の表+統合コメント評価指標:統合度、学習転移の明示性 典型的な失敗:分割が恣意的 → 対策:段名の命名規則を先に固定する
ベンチマーク設計:評価の枠組みをどう作るか
38型をChatGPTに適用した際の性能検証は、型×タスク×評価指標×プロンプトバリアントの掛け合わせ で設計するのが基本です。
定量指標
- 正確性:ルーブリック合格率、正答率
- 一貫性:同一入力に対する出力の差分(再現性テスト)
- 創造性:重複率の逆数、比喩の多様性スコア
- 簡潔性:情報保持率に対する文字数の比
- 応答時間:API計測によるレイテンシ(p50/p95)
定性評価
- 読み手が行動できるか(実用性)
- 誤解しにくいか(地と図の明示度)
- 「らしさ」が抽出できているか(006・008・019型向け)
評価の反復では、同一タスクでベースラインプロンプトと最適化プロンプトを比較 し、改善量をログとして残すことが推奨されます。失敗を三分類(入力不足・制約不足・採点不足)に分け、修正を一点ずつ加えることで、プロンプト改善の原因を特定しやすくなります。
まとめ:38型とChatGPTの接点が開く可能性
松岡正剛の「38の型」は、思考編集の動作を四つの用法(わける/つなぐ/しくむ/きめる)に整理した体系です。この体系は、ChatGPTをはじめとする大規模言語モデルへの応用において、次のような可能性を持ちます。
- 「型」があることで、プロンプトに与えるべき制約・出力形式・評価基準が明確になる
- 用法区分(1〜4)に対応する「LLM操作レバー」(バリエーション生成・構造化出力・定義テンプレ・スタイル拘束)を体系的に設計できる
- 評価(ベンチマーク)も型ごとに設計しやすく、反復改善のループを回しやすい
一方で、38型の型名・用法区分は公開情報として確認できるものの、各型の出題文そのものは非公開であるため、定義には「公開資料に基づく確度A/B」と「推定に基づく確度C」が混在しています。実際に運用する際は、各型の解釈を先にプロンプトで明示し、「解釈を選択してから実行する」設計が再現性の確保につながります。
38型という思考の構造を、AIとの対話設計へ接続することで、人間の編集力とAIの出力精度を同時に高めるループ が生まれる可能性があります。
コメント