はじめに:なぜ人間とAIのバイアスは「掛け算」で問題化するのか
私たちは日常的にAIと協働する時代に生きています。採用判断、医療診断、金融審査、コンテンツ推薦など、あらゆる意思決定の場面でAIが人間を支援しています。しかし、ここで見過ごされがちな問題があります。それは、人間が持つ認知バイアスとAIが持つバイアスが、単独で存在するのではなく、相互作用によって新たな「複合バイアス」を生み出しているという事実です。
人間の確証バイアスやアンカリング効果といった認知の癖は、AIシステムへのデータ入力やフィードバックを通じてAI側に伝播します。一方、AIが出力する偏った推薦や評価は、人間の判断を更新し、場合によってはその偏りを内面化させます。この双方向の影響が閉ループを形成することで、小さな偏りが時間とともに増幅していく可能性が、最新の実証研究で明らかになってきました。
本記事では、人間の認知バイアスとAIバイアスの相互作用メカニズムを、概念整備から数理モデル、実証的エビデンスまで体系的に解説します。
バイアスの概念整備:人間とAIを同じ土俵で捉える
人間の認知バイアスとは
人間の認知バイアスとは、合理性や統計的妥当性、公平性といった規範から系統的に逸脱する判断の傾向を指します。確証バイアス(自分の信念を支持する情報を優先的に探す)、アンカリング(最初に提示された数値に引きずられる)、利用可能性ヒューリスティック(思い出しやすい事例を過大評価する)、ステレオタイプ、過信など、多様な形態が知られています。
これらは人間の認知処理の効率化の副産物として生じますが、意思決定の質を低下させ、不公平な結果をもたらすリスクを持ちます。
AIバイアスの多層的な起源
AIバイアスは「出力の偏り」として現れますが、その起源は単一ではありません。古典的な整理では、AIバイアスを以下の3類型に分類できます。
- Preexisting bias(既存の偏り): 社会に元から存在する差別や偏見がデータに反映される
- Technical bias(技術的偏り): アルゴリズムの設計、サンプリング、目的関数の設定などに起因する偏り
- Emergent bias(創発的偏り): 利用文脈や時間経過の中で新たに立ち上がる偏り
機械学習の文脈では、データ生成、前処理、モデル学習、評価、運用というパイプライン全体に、下流の害(harm)の源が分布していると捉えることが重要です。
統一的な視点:意思決定系の系統誤差として
人間は「推論の癖」として偏り、AIは「データ・目的関数・提示形式・利用状況」の複合として偏ります。両者を接続するには、「人間+AI+環境」が構成する意思決定系全体が生み出す系統誤差として統一的に見る視点が有効です。この視点により、相互作用のメカニズムを因果的に分析できるようになります。
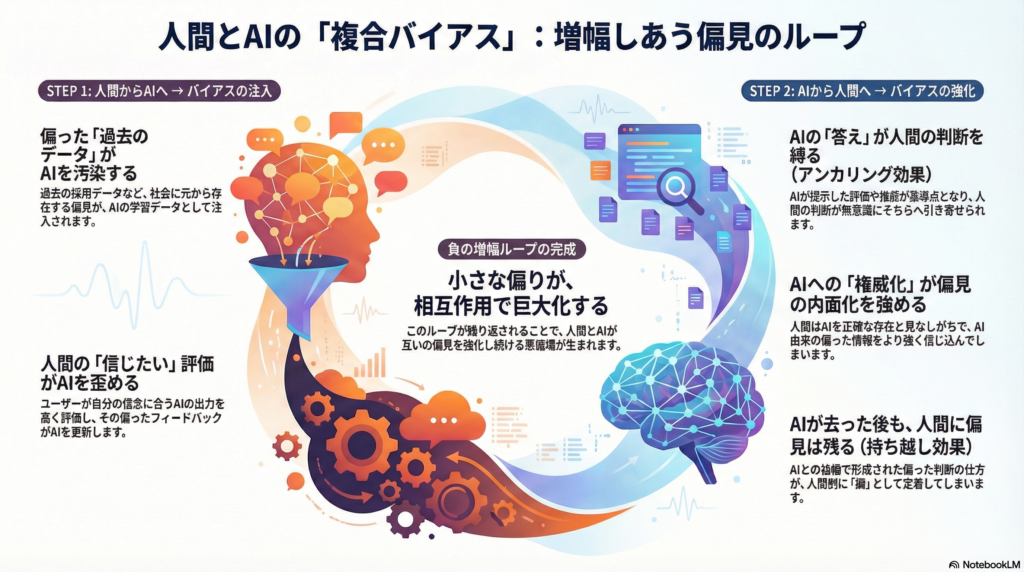
Human-AI Feedback Loop:相互作用の基本構造
閉ループの基本形
人間の認知バイアスとAIバイアスの相互作用の核心は、**Human-AI Feedback Loop(人間-AIフィードバックループ)**にあります。この構造は次のように表現できます。
人間の偏り → (データ化/プロンプト化/評価・フィードバック) → AIの偏り → (提示/推薦/生成物の曝露) → 人間の判断更新 → (行動・選好の変化が次のデータに) → ループ
実証的エビデンス:増幅の実在性
この閉ループが実際に偏りの増幅を引き起こすことを示した代表的研究が、Glickman & Sharot(2025)によるNature Human Behaviour誌の論文です。彼らは一連の実験を通じて、以下を明らかにしました。
- 人間のデータに含まれる小さな偏りをAIが学習で増幅する
- AIの偏った出力に曝露された人間が、その方向へ判断を更新する
- この相互作用が反復されることで、人間側の偏りがさらに増大する
特に注目すべきは、画像生成AIのStable Diffusionを用いた実験です。このモデルが高所得・高地位職を「白人男性」に過剰代表する傾向を持つとき、その生成画像に曝露された人間は、その方向へ知覚や社会的判断を変化させることが示されました。
AIラベル効果:権威化が学習を強める
さらに重要な発見は、「AIだと認識して相互作用すること」自体が、偏りの内面化を強めるという点です。人間はAIを優越的・正確な存在と見なす傾向があり、この認知がAI出力からの学習率を高めます。同じ偏った情報でも、それが人間由来だと思う場合よりAI由来だと思う場合の方が、判断への影響が大きくなる可能性があります。
持ち越し効果:AIが消えても偏りは残る
Vicente et al.(2023)の研究は、AIと協働した後にAIがいなくなっても、人間がAIの偏りを再生産し続ける「inherited bias(継承された偏り)」の存在を実験的に示しました。これは、相互作用を通じて形成された判断方略や知覚パターンが、人間側に内面化されることを意味します。
偏りの注入ポイント:系への入力経路を分解する
複合バイアスがどこから生じるかを理解するには、偏りが系に注入される具体的なポイントを特定する必要があります。ここでは、人間→AI、AI→人間、そして相互作用設計の3つの視点から整理します。
人間からAIへの入力ポイント
1. 歴史データ(意思決定ログ)
人間の制度、慣行、差別、測定の歪みがデータ化されることで、社会に既存する偏りがAIへ移植されます。たとえば、過去の採用データに男性優遇の傾向があれば、そのパターンをAIが学習します。
2. ラベル付け(評価・採点・診断)
真の値ではなく代理指標(proxy)で学習させると、偏りが固定・増幅されやすくなります。たとえば、「優秀さ」を測るために「昇進速度」を使えば、既存の組織文化の偏りがそのまま学習されます。
3. プロンプト選好(何をどう問うか)
ユーザーが何を質問し、どの出力を採用・共有するか自体が、次のデータ分布を変えます。特定の文脈でのみAIを使う、特定タイプの推薦だけを受け入れる、といった選択バイアスがループに入り込みます。
4. フィードバック(良い/悪い、採用/棄却)
人間が「信じたい出力」を高評価する構造があると、AI更新が偏り方向へドリフトします。後述する確証バイアスと結合すると、この効果は特に強くなります。
AIから人間への入力ポイント
1. アンカリング効果
AIの推奨値や評価値が基準点(アンカー)として働き、人間の調整が不十分になります。Carter(2025)の研究では、組織の人事評価においてAI推奨がアンカーとして機能し、評価者の判断がそこへ引き寄せられることが実験的に示されました。
2. 確証ゲート(Confirmation-gated reliance)
人間は、自分の初期判断と一致するAI推薦をより信頼・受容する傾向があります。Bashkirova(2024)の研究は、精神医療のトリアージ想定で、AI推奨が初期診断と整合的なときに受容と信頼が増加することを報告しています。これは確証バイアスがAI推奨の受容を「ゲート制御」していることを意味します。
3. オートメーション・バイアス(過剰依存)
AIの誤推奨への「誤同意率」として測定可能な形で、タスク難度、自己効力感、システムへの信頼などが影響します。医療の臨床意思決定支援システム(CDSS)の研究では、AIリテラシーや説明の複雑性など、複合的な要因がオートメーション・バイアスの強さを左右することが明らかになっています。
4. 表象バイアス(何が「普通」として見えるか)
画像生成AIの例のように、ある属性の人物像が過剰に出力されることで、人間の「それらしさ判断」が更新されます。これは知覚レベルでの偏りの転移です。
5. 説明による伝播率の変化
大規模言語モデル(LLM)がステレオタイプ方向に詳細な説明を付けると、偏りの増幅が起きやすくなる一方、反ステレオタイプ方向の影響は広まりにくい、といった「説得の非対称性」が示唆されています。説明はただの情報ではなく、説得装置として働くのです。
相互作用設計が注入する要因
- AIラベルの有無: AIだと分かることが権威化と学習の強化につながる
- 不確実性表示: 確信的な文体や単一回答はアンカリングと過信を強める
- 検証コスト: 確認作業が重いと過剰依存が生じやすい
- 説明の様式: 説明は理解だけでなく説得として働き、偏り伝播を変える
6つの中核メカニズム:相互作用を機械論として定式化する
複合バイアスがどのように生成・増幅されるかを理解するには、相互作用の背後にあるメカニズムを分解する必要があります。ここでは、実証研究に基づいて特定された6つの中核プロセスを提示します。これらは相互に結合し、複雑な動態を生み出します。
M1: 学習増幅(Human bias → AI bias amplification)
人間由来データの小さな偏りをAIが学習プロセスで増幅する可能性があります。これはデータの偏りがモデルのパラメータに固定化され、場合によっては元のデータ以上に極端な出力を生む現象です。
M2: 曝露学習(AI bias → Human belief update)
反復的な相互作用を通じて、人間の知覚、感情、社会的判断が徐々に偏る現象です。これは「AIから学習してしまう」プロセスであり、意識的な意図とは独立に進行する可能性があります。
M3: メタ認知ゲート(AIをどう位置づけるかが学習率を変える)
AIを優越的・正確だと認識するほど、AI出力を強く内面化します。これは「AIラベル効果」として知られ、同じ情報でも出所認知が学習の深さを変えることを示します。
M4: 選択的受容(Confirmation-gated reliance)
AIが「自分の見立てと一致」したときだけ過剰に受容される現象です。確証バイアスがフィルタとして働くため、AI推奨の影響は対称的ではなく、既存の信念を強化する方向に偏ります。これは人間→AI側のフィードバックも歪めるため、閉ループ増幅が加速しやすくなります。
M5: アンカリング(数値・評価・要約が基準点になる)
AI推奨が認知的アンカーとして機能し、判断がそこへ引き寄せられます。特に数値評価や要約といった形式で提示されると、この効果は強まります。
M6: 内面化と持ち越し(AIが消えても偏りが残る)
相互作用を通じて形成された判断方略が、AIなし条件でも再生産される現象です。これは短期的な依存を超えて、認知構造そのものが変化していることを示唆します。
数理モデルとしての定式化:因果構造と動態
最小因果グラフ(DAG)
複合バイアスの生成を因果的に理解するため、以下の変数を定義します。
- Hₜ: 時刻tにおける人間の事前信念・バイアス
- Aₜ: 時刻tにおけるAIの出力バイアス
- I: インタフェースや制度的設定
- Dₜ: 時刻tにおける人間の行動ログ(次の学習データ)
因果関係は次のように表現できます。
- Aₜ → Hₜ₊₁: AIの出力が人間の信念を更新(曝露・アンカー・確証フィルタ)
- Hₜ → Dₜ: 人間の偏りが行動ログに反映(プロンプト・採用・評価)
- Dₜ → Aₜ₊₁: ログがAIの再学習に使われる
- I: 各矢印の強さを調整(学習率・信頼・検証コスト)
ダイナミクスの最小モデル
人間の偏り状態の更新:
Hₜ₊₁ = Hₜ + α f(Aₜ, Hₜ, I)
ここでαは「AIから学習してしまう強さ」を表し、権威化、反復回数、検証コストによって増加します。
AIの偏り状態の更新:
Aₜ₊₁ = Aₜ + β g(Dₜ, Aₜ)
ここでβは「人間ログでAIがどれだけ更新されるか」を表します。
データ生成:
Dₜ = h(Hₜ, Aₜ, I)
確証バイアスが強いほど「一致出力だけ採用」され、Dₜが片寄ります。
増幅条件の直観
直観的には、増幅条件は次のように表現できます。
「人間がAIから学ぶ強さ(α)」×「AIが人間データから偏りを増やす強さ(β)」が一定閾値を超えると、正のフィードバックが発火します。
Glickman & Sharotの実験結果は、この正のフィードバックが知覚、情動、社会的判断において実際に起こり得ることを、複数の実験系列で実証したものと解釈できます。
複合バイアスの制御に向けて:増幅と反転の条件
増幅は必然ではない
重要な点は、人間-AI相互作用が常に偏りを増幅するわけではないことです。正確で公平なAIは判断精度を改善し得ますし、反ステレオタイプ方向の推薦が偏りを減らす可能性も示唆されています。
ただし、影響の伝播には非対称性があります。偏りを強化する方向の影響は広まりやすく、偏りを弱める方向の影響は伝播しにくい傾向が観察されています。この非対称性の理解は、介入設計において重要です。
介入ポイント
複合バイアスを制御するための介入ポイントとしては、以下が考えられます。
- データ段階: 代理指標の見直し、サンプリングバイアスの補正
- モデル段階: 公平性制約の導入、不確実性の適切な表現
- インタフェース段階: AIラベルの透明性、不確実性の可視化、検証支援
- フィードバック段階: 確証バイアスを緩和する仕組み、多様な評価の収集
- メタ認知段階: AIリテラシー教育、批判的思考の促進
まとめ:複合バイアス研究の展望
人間の認知バイアスとAIバイアスは独立した問題ではなく、相互作用を通じて「複合バイアス」を形成します。この複合バイアスは、データ化、曝露による学習、メタ認知的な権威化、確証バイアスによる選択的受容、アンカリング効果、そして内面化と持ち越しという6つの中核メカニズムの結合によって生じます。
これらのメカニズムが閉ループを形成するとき、小さな偏りが時間とともに増幅する可能性があります。一方で、適切な条件下では偏りを減少させる方向にも働き得ます。この双方向性の理解が、効果的な介入設計の鍵となります。
今後の研究では、これらのメカニズムをより精緻に同定し、増幅と反転の条件を定量的に明らかにしていくことが求められます。また、推薦システム、医療診断、採用支援、教育支援など、具体的なドメインにおける実証研究の蓄積も重要です。
人間とAIの協働は不可避の流れです。その協働が公平で建設的なものとなるために、複合バイアスのメカニズム解明は喫緊の研究課題といえるでしょう。
コメント