なぜ今、協調的因果推論システムが必要なのか
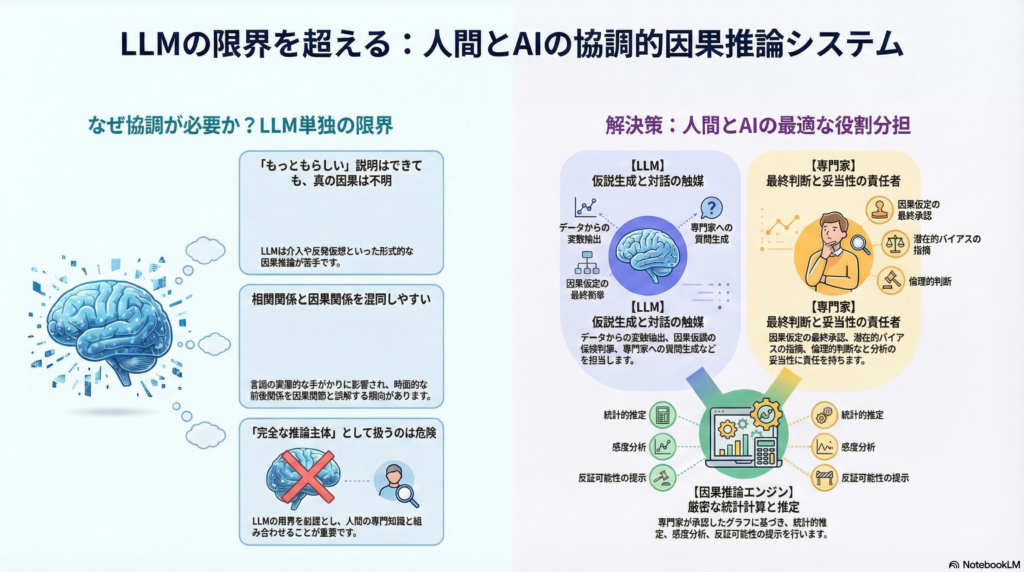
大規模言語モデル(LLM)の進化により、因果関係の分析に自然言語処理を活用する試みが増えています。しかし最近の研究では、LLMが「もっともらしい因果説明」は生成できても、介入や反実仮想といった形式的な因果推論には限界があることが明らかになっています。因果関係と時間的前後関係の混同や、言語の表層的な手がかりに引きずられる傾向も指摘されています。
こうした状況において、LLMを「完全な推論主体」として扱うのではなく、人間の専門知識と組み合わせた協調システムとして設計することが重要になります。本記事では、人間とLLMの役割分担を明確にした因果推論システムの設計原理と実装方法を解説します。
協調システムにおける役割分担の原則
効果的な協調因果推論システムでは、各主体の強みを活かした役割分担が不可欠です。
LLMの役割は、文章から変数を抽出し、因果仮説の候補を列挙し、専門家への質問を生成することです。また、議論の要約やDAG(有向非巡回グラフ)の草案提案、分析手順の整理も担当します。ただし、断定的な因果判断は避けるべきです。
専門家の役割は、因果仮定の最終承認です。どの変数間に矢印を引くか、潜在的な交絡要因は何か、測定方法は妥当か、介入は実行可能かといった判断を行い、分析の妥当性に責任を持ちます。また、倫理的考慮や目的関数の決定も専門家の重要な役割です。
因果推論エンジンは、グラフに基づく同定(backdoor基準、操作変数法、do-calculusなど)と統計的推定、感度分析、反証可能性の提示を担当します。DoWhyのようなライブラリは、この役割に適しています。
協調因果推論システムへの入力仕様
システムが適切に機能するためには、入力情報を構造化して定義する必要があります。
因果クエリの明確化
分析の目的を明確にするため、以下の要素を機械可読な形式(JSONなど)で指定します。
介入変数として、何を変えるのか(操作可能性や実験的介入か政策的介入かを含む)を定義します。結果変数として、何を最適化したいのかを明示します。推定対象は、平均処置効果(ATE)、処置群における平均処置効果(ATT)、条件付き平均処置効果(CATE)、媒介効果、反実仮想など、具体的な推定量を指定します。対象母集団を明確にすることで外的妥当性を確保し、介入タイミングやラグ、追跡期間といった時間軸の情報も含めます。
LLMは自然言語でクエリを受け取り、これらの要素を構造化スキーマに変換する役割を果たします。
変数の定義と意味の統一
因果推論が失敗する主な原因の一つは、変数の意味が曖昧なことです。各変数について、操作的定義、測定方法、単位、欠測のメカニズムを明確にします。また、同義語や略語、ログのタグ名などを対応付け、用語の不一致を解消します。
ログデータから変数を抽出する際にLLMを活用し、最終的な定義は人間が承認するという設計が実践されています。
因果構造に関する事前知識
専門家の知識を最大限活用するため、以下の制約を明示的に入力します。
必須の矢印として、「AからBへの因果関係は必ず存在する」といった確実な関係を指定します。禁止エッジとして、「AからBへの因果関係はあり得ない」という制約を設定します。潜在交絡の可能性、つまり観測されていない共通原因が存在する可能性を示します。測定誤差や代理変数の問題、選択バイアスの可能性も明記します。
これらの制約を活用することで、探索アルゴリズムは不確実な部分だけを専門家に質問する形になり、専門家の負担を軽減できます。
データの特性
データの種類によって適用可能な分析手法が変わります。観測データのみか介入データがあるか、時系列データか集計データか、階層構造を持つマルチレベルデータか、分布の変動や非定常性があるかといった情報を明示します。
因果発見アルゴリズムは、忠実性(faithfulness)や選択バイアスの不在、十分なサンプルサイズといった仮定に依存します。これらの仮定が満たされない場合、どの推論が弱くなるかを出力に反映させる必要があります。
出力の品質要件とリスク許容度
協調因果推論では、正解だけでなく責任の所在も重要です。許容する誤りの種類(偽陽性の矢印と偽陰性のどちらがより問題か)、説明責任の要件(監査ログや再現可能性)、医療や政策など高リスク領域における安全性の考慮を入力段階で明確にします。
システムアーキテクチャの設計
協調的因果推論システムは、以下の4つのレイヤーで構成されます。
レイヤ1:対話と合意形成
LLMを中心として、分析の目的や問いを整形します。ATEを求めるのか、反実仮想を考えるのかといった推定対象を明確にし、変数定義を確定して用語のズレを吸収します。また、すべての仮定を文章として明文化し、後で監査可能な形で記録します。
レイヤ2:因果グラフの生成と更新
このレイヤーでは、LLM、探索アルゴリズム、人間の専門家が協調して因果グラフを構築します。
まずLLMが候補となるDAGを提案します。次に、データ駆動の探索アルゴリズムが、スケルトン(エッジの有無)や向きの候補を出力します。人間の専門家は、禁止エッジや必須エッジの制約を用いて候補を絞り込みます。最後に、不確実なエッジについてのみ専門家に質問し、グラフを完成させます。
この設計は、人間と相互作用しながら因果発見を洗練させる枠組みや、LLMを事前知識の注入に使い最適化で精緻化する手法、LLMを背景知識提供者として古典的な因果発見アルゴリズムに統合する手法と整合性があります。
観測データそのものをLLMのプロンプトに含めて推論させる試みもありますが、性能向上は限定的との指摘もあるため、協調設計では「提案」に留めるのが安全です。
レイヤ3:同定と推定
このレイヤーは形式的推論と統計的推定の層であり、LLMは説明と手順の提案までを担当します。
backdoor基準による調整集合の探索、操作変数の候補選定、frontdoor基準の適用、do-calculusを含む同定手順の実行を行います。推定器の選択では、回帰分析、逆確率重み付け(IPW)、二重頑健推定(DR)、g-formula、Targeted Maximum Likelihood Estimation(TMLE)などから適切な手法を選びます。未観測交絡や選択バイアスに対する感度分析も実施します。
DoWhyは「グラフで仮定を置く→同定→推定→反証(refutation)」を一貫して扱う設計であり、協調システムの因果エンジン層として適しています。
レイヤ4:協調の最適化
協調の本質は、専門家のコストを最小化しつつ推論の頑健性を最大化することです。
具体的には、推定対象(ATEなど)に対して感度が大きいエッジや潜在交絡を特定し、その部分だけを専門家に質問します。グラフを更新した結果、同定可能性や推定誤差、不確実性がどう変化したかを可視化します。
このアプローチは、ATEに最大の影響を与えるグラフ編集を提案し、ユーザーが妥当性を判断して更新する「因果グラフ精錬」の実装例と方向性が一致します。
協調推論の実行プロトコル
論文や実装に落とし込みやすいよう、協調的因果推論の手順を明確に定義します。
ステップ1では、処置変数、結果変数、推定対象、対象母集団、時間軸をスキーマ化して問いを固定します。
ステップ2では、曖昧な用語を排除し、代理変数や測定誤差をラベル付けして変数辞書を確定します。
ステップ3では、LLMと既存知識を用いて初期グラフを生成します。DAG案とともに根拠となるテキストと自信度も記録します。
ステップ4では、専門家が禁止エッジ、必須エッジ、潜在交絡の可能性、時間制約を注入します。
ステップ5では、条件付き独立性、分布の変化、欠測パターン、外れ値などをチェックし、データとグラフの整合性を確認します。
ステップ6では、不確実性駆動の質問生成を行います。推定量への影響が大きい箇所を優先し、不確実と判定された関係だけを質問します。
ステップ7では、backdoor基準、操作変数法、do-calculusなどを用いて因果効果の同定を行います。
ステップ8では、複数の推定器を用いて推定を行い、プラセボテスト、サブセット分析、ブートストラップなどによる反証テストを実施します。
ステップ9では、「何が仮定か」と「何がデータから言えるか」を分離して説明を生成し、責任の分界を明確にします。
ステップ10では、グラフの版管理、質問と回答の記録、推定の再現性を確保するための監査ログを作成します。
哲学的・認知科学的論点
協調的因果推論システムは、技術的実装を超えた哲学的・認知科学的問いを提起します。
LLMの位置づけ
LLMは「因果推論の主体」なのか、それとも「認知的足場」なのかという問いがあります。LLMは形式的推論の弱さが指摘される一方、概念整理や仮説生成、説明といった推論の前段階では強力です。主体性(agency)をLLMに置くのではなく、分散認知における足場として位置付ける設計原理が有効である可能性があります。
因果的正当化の所在
協調システムにおいて、因果的正当化はどこに宿るのでしょうか。データなのか、グラフの仮定なのか、専門家の判断なのか、LLMの提案なのか。
協調システムでは「正当化の鎖」を明示し、推論の根拠を仮定、データ、規範の観点から分解して提示する必要があります。これは説明責任と直結する重要な設計要素です。
共進化の設計
協調が進むにつれ、専門家はどの仮定が同定に影響するか、どの質問が重要か、どのバイアスが致命的かを学習していきます。一方でLLM側も、過去の判断ログ、領域固有の語彙、典型的な交絡パターンを取り込み、より適切な問い返しができるようになります。
この相互学習のプロセスを促進するプロトコルの設計が、協調因果推論の核心的な貢献となる可能性があります。
評価指標の設定
協調システムの成功を測るため、複数の観点から評価を行います。
因果グラフの品質
構造ハミング距離(SHD)により、真のグラフとの構造的差異を測定します。辺の精度と再現率を、向きも含めて評価します。潜在交絡や不確実性を扱う場合は、単一の正解DAGではなく分布や同値類で評価する発想が重要です。
推定の品質
ATEなどの推定誤差を計算します。信頼区間が適切に校正されているか(カバレッジ)を確認します。未観測交絡に対する感度分析の質も評価します。
協調の効率性
専門家に要求した判断の回数(質問数)、1判断あたりの情報利得(不確実性の減少量)、所要時間や認知負荷を測定します。
ATEに影響するグラフ編集だけを提示して専門家負担を減らすアプローチは、この評価軸に沿った実装例です。
説明可能性と監査可能性
すべての仮定が機械可読な形で記録されているか、結論が仮定にどう依存するかを依存グラフや感度分析で示せるかを確認します。
最小実装の構成要素
実際にシステムを構築する際の最小構成(MVP)を示します。
ユーザーインターフェースとして、DAGエディタを用意します。矢印の追加、禁止、潜在交絡のマークができる機能が必要です。
LLM層では、ログや文章から候補変数を生成する変数辞書生成機能と、不確実なエッジについて専門家に聞く質問文を生成する機能を実装します。
因果推論層では、DoWhyを用いて同定、推定、反証テストを実行します。
協調最適化では、推定量への影響が大きい候補編集を選択するか、不確実な関係だけを動的に要求する仕組みを構築します。
ログ機能として、グラフの版管理、LLMの提案、専門家の判断、推定結果を記録します。
この構成は、LLMで事前知識や背景情報を注入し、古典的な因果発見アルゴリズムや最適化手法で精緻化するという、既存研究の潮流とも整合します。
まとめ:協調的因果推論の可能性
LLMの因果推論能力には限界がありますが、その限界を前提として人間の専門知識と適切に組み合わせることで、実用的な因果推論システムを構築できる可能性があります。
重要なのは、LLMを完全な推論主体として扱うのではなく、概念整理や仮説生成といった認知的足場として位置付けることです。同時に、専門家が判断すべき箇所を最小化しつつ、推論の頑健性を最大化する協調プロトコルの設計が求められます。
DoWhyのような因果推論ライブラリと、不確実性駆動の質問生成を組み合わせることで、効率的な協調システムの実装が可能になります。また、すべての仮定と判断を監査可能な形で記録することで、説明責任を果たせる設計になります。
今後は、実際のドメインでの評価や、専門家の学習効果の測定、共進化のメカニズムの解明が課題となるでしょう。
コメント