協調的因果推論が求められる背景
因果推論は、観測データから「何が何を引き起こすか」を明らかにし、介入効果を予測する強力な手法です。しかし近年、大規模言語モデル(LLM)を因果推論に活用する試みが進む一方で、その能力の限界も明らかになってきました。LLMは一見もっともらしい因果説明を生成できても、介入や反実仮想といった形式的な因果推論を確実に実行する能力は限定的であることが指摘されています。
この限界を前提に、人間の専門性、LLMの言語処理能力、形式的な因果推論エンジンを統合した協調システムの設計が重要になります。本記事では、こうした協調システムの設計原理を、入力仕様、アーキテクチャ、評価方法、そして人間とLLMの共進化という観点から詳しく解説します。
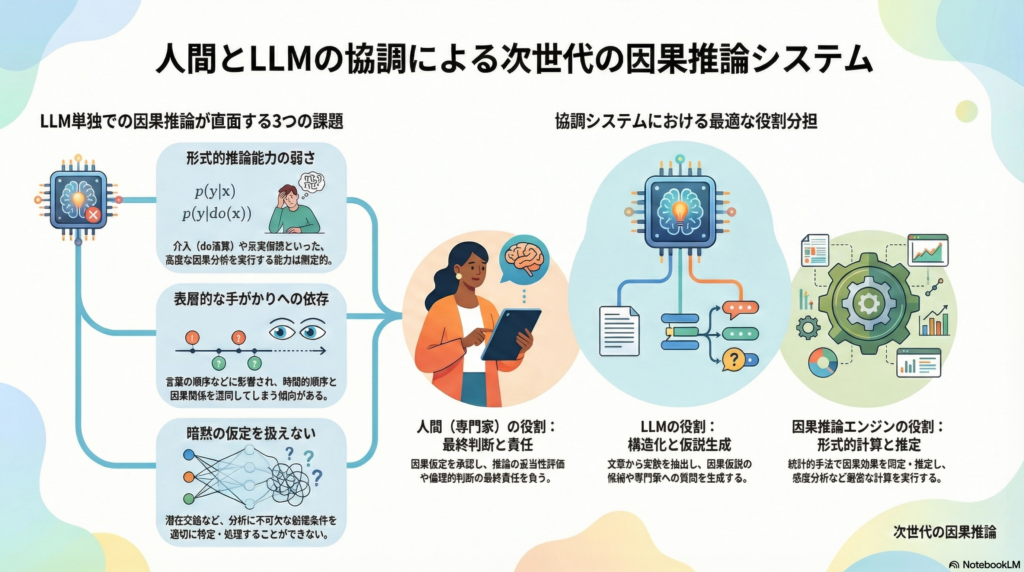
LLMの因果推論能力の限界と協調の必要性
LLMが直面する課題
LLMは自然言語の文脈から因果関係を推測することには長けていますが、以下のような課題があります。
- 形式的推論の弱さ:介入(do演算)や反実仮想といった因果ラダーの上位層を形式的に扱う能力は限定的です
- 表層的手がかりへの依存:因果と時間的順序(before/after)を混同したり、言語の順序に過度に影響されたりする傾向があります
- 仮定の明示化の困難:潜在交絡や選択バイアスといった因果推論に不可欠な仮定を適切に扱えない場合があります
協調システムにおける役割分担
こうした限界を踏まえ、協調システムでは以下のように役割を分担します。
LLMの役割
- 文章から変数を抽出し構造化する
- 因果仮説の候補を列挙する
- 専門家への質問を生成する
- 議論を要約し、DAG(有向非巡回グラフ)の草案を提案する
人間専門家の役割
- 因果仮定(矢印の有無、潜在交絡、測定誤差)の最終承認
- 推論の妥当性に対する責任を負う
- 倫理的判断や目的関数の決定
因果推論エンジンの役割
- backdoor調整、操作変数法、do-calculusなどによる因果効果の同定
- 統計的推定と感度分析の実行
- 反証可能性の提示
このような分業により、LLMの強みを活かしつつ、形式的推論と人間の判断を適切に統合できる可能性があります。
協調因果推論システムの入力仕様
協調システムを実装可能にするためには、「何を入力とし、どの推論が可能になるか」を明確に定義する必要があります。
因果クエリの構造化
因果推論の問いは、以下の要素を機械可読な形式(例:JSON)で明示します。
- 介入(Treatment):何を変えるのか、それは操作可能か
- 結果(Outcome):何を最適化したいのか
- 推定対象(Estimand):平均処置効果(ATE)、処置群の平均処置効果(ATT)、条件付き平均処置効果(CATE)など
- 対象母集団:推論の対象となる集団の定義
- 時間軸:介入のタイミング、ラグ、追跡期間
LLMは自然言語で問いを受け取り、これらの要素を構造化スキーマに変換する役割を担います。
変数定義のセマンティクス
因果推論が破綻する主な原因の一つは、変数の意味が曖昧であることです。以下の情報を明示化します。
- 操作的定義と測定方法
- 単位と欠測のメカニズム
- 同義語、略語、ログタグの対応関係
LLMはログや文章から変数候補を抽出し、人間が承認する形での協調が有効です。
因果構造の事前知識
専門家の知識を以下の形式で入力に組み込みます。
- 必須の矢印:必ず存在する因果関係
- 禁止エッジ:あり得ない関係
- 潜在交絡の可能性:観測できない共通原因の存在
- 測定誤差や代理変数:真の概念が直接測定できていない場合
- 選択バイアス:データに含まれるサンプルの偏り
こうした制約を探索アルゴリズムに組み込むことで、不確実な箇所だけを専門家に質問する効率的な協調が可能になります。
データの性質と仮定
データの種類と性質を明示することで、どの因果推論手法が適用可能かが決まります。
- 観測データのみか、介入データがあるか
- 時系列、集計、階層構造などのデータ形式
- 分布変動や非定常性の有無
因果発見アルゴリズムは、忠実性(faithfulness)や選択バイアスなしといった仮定に依存するため、これらを入力として明示し、満たせない場合の推論の限界を出力に反映させることが重要です。
リスク許容度と説明責任
協調因果推論は「正解」だけでなく「責任」を扱います。
- 許容する誤りの種類(偽陽性の矢印 vs 偽陰性の見逃し)
- 監査ログと再現可能性の要件
- 医療や政策など高リスク領域における安全性基準
これらを設計要件として入力に含めることで、推論の責任分界が明確になります。
協調的因果推論アーキテクチャの全体像
協調システムは、複数のレイヤで構成される階層的なアーキテクチャとして設計できます。
レイヤ1:対話と合意形成
LLMを中心に、以下のプロセスを実行します。
- 目的と問いの整形(ATEか反実仮想か)
- 変数定義の確定と用語のズレの吸収
- 仮定の文章化と監査可能性の確保
このレイヤでは、推論の前提を明文化し、後の検証に備えます。
レイヤ2:因果グラフの生成と精錬
LLM、探索アルゴリズム、人間専門家が協調してグラフを構築します。
- LLMが候補DAGを提案
- データ駆動の探索アルゴリズムが構造候補を出力
- 人間が禁止・必須制約で候補を絞り込む
- 不確実なエッジのみを質問して埋める
この方式は、人間と相互作用しながら不確実性を扱う因果発見の枠組みや、LLMを事前知識の注入に使い最適化で精緻化する手法と整合的です。
レイヤ3:因果効果の同定と推定
形式的推論と統計的推定を実行します。LLMは説明と手順の提案に留めます。
- backdoor調整集合の探索
- 操作変数(IV)候補の検討
- do-calculusを含む同定手順
- 推定器の選択(回帰、逆確率重み付け、二重頑健推定など)
- 感度分析(未観測交絡、選択バイアス)
DoWhyなどのライブラリは、グラフに基づく同定から推定、反証まで一貫して扱えるため、協調システムの因果エンジン層として有用です。
レイヤ4:協調の最適化
協調の本質は、専門家コストを最小化しつつ推論の頑健性を最大化することです。
- 推定対象(ATE等)への影響が大きいエッジや潜在交絡を特定
- それらについてのみ専門家に質問
- グラフ更新により、同定可能性や推定誤差がどう変わるかを可視化
このような不確実性駆動のアクティブな協調により、効率的な推論が可能になります。
協調プロトコル:因果推論会話の手続き化
協調システムを実装するには、人間とLLMの相互作用を明確な手順として定義する必要があります。以下に「Causal Co-Reasoning Loop」として提案します。
- 問いの固定:介入、結果、推定対象、母集団、時間軸をスキーマ化
- 変数辞書の確定:曖昧語を排除し、代理変数・測定誤差をラベル付け
- 初期グラフ生成:LLMと既存知識からDAG案を生成、根拠テキストと自信度を付与
- 制約注入:専門家が禁止・必須・潜在交絡・時間制約を設定
- データ整合チェック:条件付き独立性、分布変化、欠測、外れ値を検証
- 不確実性駆動の質問生成:推定量への影響が大きい箇所や不確実な関係について質問
- 同定:backdoor、IV、do-calculusなどをライブラリで実行
- 推定と反証:複数の推定器、プラシーボテスト、サブセット分析、ブートストラップ
- 説明生成:仮定とデータから言えることを分離して提示し、責任分界を明確化
- 監査ログ化:グラフの版管理、質問と回答、推定の再現性を記録
このプロトコルにより、協調プロセスが透明化され、再現可能になります。
協調システムの哲学的・認知的論点
協調因果推論システムは、単なる技術的問題ではなく、哲学や認知科学の深い問題を提起します。
LLMの位置づけ:主体か足場か
LLMは形式推論の弱さが指摘される一方、推論の前段階で強力です。ここで問われるのは、LLMを「推論主体」として扱うのか、それとも人間の認知を支援する「足場(scaffolding)」として位置付けるのかです。
協調設計では後者の視点、すなわち分散認知の枠組みでLLMを捉えることで、より安全で有効な統合が可能になる可能性があります。
因果的正当化の所在
協調システムにおいて、推論の正当性はどこに宿るのでしょうか。
- データに基づくのか
- グラフ仮定に基づくのか
- 専門家の判断に基づくのか
- LLMの提案に基づくのか
協調システムでは、この「正当化の鎖」を明示し、推論の根拠(仮定、データ、規範)を分解して提示する必要があります。これは説明責任と直結する重要な論点です。
共進化による能力向上
協調が進むにつれ、専門家は以下を学習していきます。
- どの仮定が同定に効くか
- どの質問が重要か
- どのバイアスが致命的か
一方、LLM側も過去の判断ログ、領域語彙、典型的な交絡パターンを取り込み、より良い問い返しができるようになります。このような相互学習のプロトコルが、協調因果推論の中核的貢献となる可能性があります。
協調システムの評価設計
協調因果推論システムの成功を測るには、多面的な評価軸が必要です。
因果グラフの品質
- 構造ハミング距離(SHD)
- 辺の精度と再現率(方向も含む)
- PAGや祖先グラフの場合は同値類での評価
潜在交絡や不確実性を扱う場合、単一の正解DAGではなく、分布や同値類で評価する視点が重要です。
推定品質
- 推定誤差(ATE等の真値との乖離)
- 信頼区間のカバレッジ(校正度)
- 未観測交絡に対する感度分析の提示品質
協調効率
- 専門家に要求した判断回数
- 1判断あたりの情報利得(不確実性減少量)
- 所要時間と認知負荷
推定対象に影響の大きい編集だけを提示することで専門家負担を減らす評価軸は、実装例において有効性が示されています。
説明可能性と監査可能性
- 仮定の一覧が機械可読で残されているか
- 結論が仮定にどう依存するかを示せるか(感度グラフ)
- 推論過程が再現可能か
これらの評価軸により、協調システムの実用性と信頼性を多角的に検証できます。
最小実装の構成要素
協調因果推論システムを実装する際の最小構成(MVP)を示します。
UI層
- DAGエディタ(矢印の追加・禁止・潜在交絡のマーク)
- 質問提示と専門家応答のインターフェース
LLM層
- ログや文章から候補変数を生成
- 不確実なエッジについて専門家への質問文を生成
- 推論過程の説明文を生成
因果推論層
- DoWhyなどのライブラリで同定・推定・反証を実行
- 感度分析と不確実性の定量化
協調最適化層
- 推定量への影響が大きい候補編集を選択
- 不確実な関係だけを動的に要求
ログ管理層
- グラフの版管理
- LLM提案、専門家判断、推定結果の記録
この構成は、既存研究の潮流とも整合的であり、実装可能な出発点となります。
まとめ
本記事では、人間の専門性とLLMの言語処理能力、形式的推論エンジンを統合した協調的因果推論システムの設計原理を解説しました。LLMの因果推論能力の限界を前提に、役割分担を明確化し、入力仕様からアーキテクチャ、評価方法までを体系的に整理しました。
協調システムの核心は、専門家コストを最小化しつつ推論の頑健性を最大化することにあります。不確実性駆動の質問生成や、推定対象への影響を考慮した優先順位付けにより、効率的な協調が実現できる可能性があります。
さらに、LLMを推論主体ではなく認知的足場として位置付けること、正当化の鎖を明示すること、人間とLLMの共進化を促すプロトコルを設計することなど、哲学的・認知科学的な論点も重要です。これらは、AIと人間の協調における責任分界や説明責任を考える上で欠かせない視点となります。
コメント