導入:AI協働創作は「出力」だけでなく「学習・流通」まで法務設計が必要
生成AIは、作品を生む瞬間(アウトプット)だけでなく、学習データの集め方(インプット)や、公開・納品・配信(流通)まで含む全体で法的リスクが連鎖しやすい領域です。しかも、著作権だけで完結せず、責任(不法行為・契約)や産業財産権(特許・商標・意匠)、人格的利益(肖像・声、プライバシー)まで絡みます。
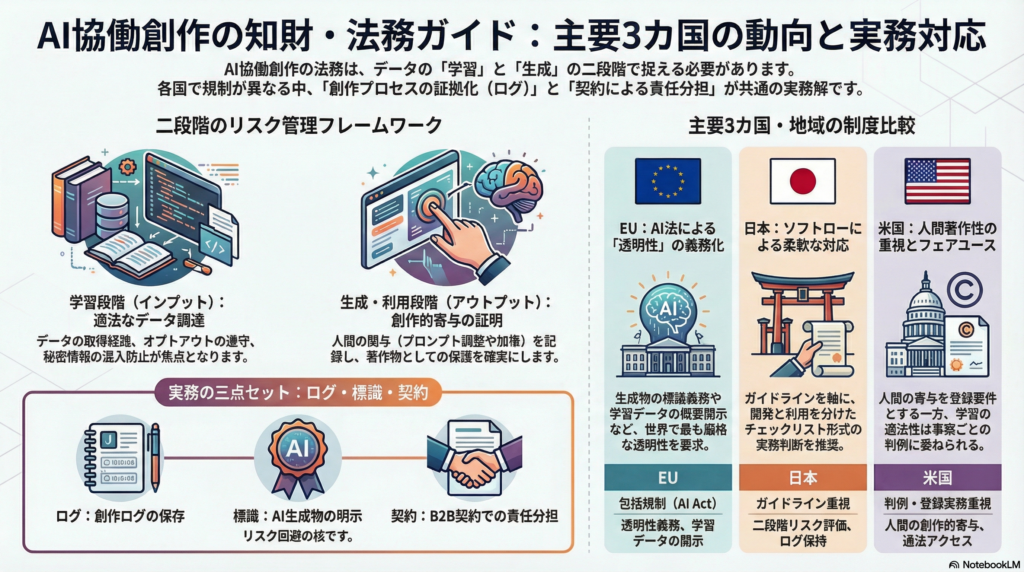
本記事では、実務で有効な「二段階(学習/生成・利用)」の見取り図を前提に、日本・EU・米国・英国・中国の制度動向を比較し、制作現場と事業者が取り得る対策を整理します。
AI協働創作の論点は「学習」と「生成・利用」に分けて考える
学習(インプット)で争点化しやすいポイント
学習段階では、学習データの取得経路が適法か、権利留保(オプトアウト)の扱いはどうするか、秘密情報や個人情報が混入していないかが中心論点になります。ここでの不備は、後段の取引で「表明保証・補償」や監査要求として跳ね返る可能性があります。
生成・利用(アウトプット)で争点化しやすいポイント
生成段階では、生成物が著作物として保護されるか(人間の創作的表現があるか)、既存作品への依拠性や二次的著作物性、公開時の表示・透明性、誤情報や名誉毀損などの責任が焦点になります。ここは契約と運用での「役割分担」が現実解になりやすい領域です。
国際比較:日本・EU・米国・英国・中国の制度が示す“実務の分岐点”
日本:ソフトロー中心で「二段階のリスク評価」とチェックリストが軸
日本では、法的拘束力のある単一ルールで一気に規制するというより、ガイドラインやチェックリスト等のソフトローで実務の判断枠組みを提示し、開発・学習段階/生成・利用段階で整理するアプローチが前面に出ています。
この設計は、現場が「やるべきこと(ログ、素材確認、契約条項)」に落とし込みやすい一方、国際取引では他地域の義務(とくに透明性)への適合が課題になり得ます。
EU:AI Actで透明性義務とGPAI提供者の著作権対応を制度接続
EUは包括規制の形で、生成物の標識(機械可読を含む)など透明性義務を明文化し、基盤モデル(GPAI)提供者に著作権法遵守方針や学習データ概要の開示を求める方向を法令として確定しています。
実務的には、著作者性そのものをEU法で定義するというより、「透明性インフラ(標識・情報提供)」を先行させ、権利処理の完全監査が難しい現実に合わせて“説明可能性”を底上げする狙いが読み取れます。
米国:人間著作者性を軸に、学習適法性は判例が揺れながら積み上がる
米国は、著作権登録実務で「人間の創作的寄与」を軸に運用を整え、AI生成部分の開示やディスクレーム(権利主張の除外)を求める方向が明確です。
一方、学習データの適法性はフェアユースの射程が事案により分岐しやすく、学習利用が適法と評価され得る判断と、適法でないと評価され得る判断が併存しています。特に、調達経路が適法か(海賊版や不正取得の混入がないか)は、結果に大きく影響し得る重要論点です。
英国:コンピュータ生成物規定を維持しつつ、TDM例外や制度再設計を協議
英国は、いわゆる「コンピュータ生成物(人間著作者がいない状況)」に関する明文規定を持つ点で例外的です。同時に、学習(TDM)例外の制度設計を再検討する公開コンサルを行うなど、制度の再設計を継続的に議論しています。
さらに、AI関連ソフトウェア発明の特許適格性に関する最高裁判断が、審査・訴訟の枠組みに影響し得る点も、知財戦略に直結します。
中国:行政規制で学習・標識を強く要請し、裁判例では人間寄与を重視する方向も
中国は生成AIサービス規制や深度合成規制で、学習データの適法取得、個人情報の同意(または適法根拠)、生成物への標識などを行政規制として強く要請する傾向があります。
裁判例では、プロンプト等の人間の創作的関与を前提にAI生成画像の著作権保護を認める判断も現れており、「人間寄与の証拠」が実務上の要点になり得ます。
著作権の最大論点:AI生成部分と人間寄与をどう区分し、どう証明するか
「帰属」より先に必要になるのは“寄与の見える化”
AI協働創作では、創作制御(control)の度合いが連続的で、分業もしやすく、モデル側の寄与が不可視になりがちです。その結果、著作者性や共同著作の判断が不安定になり得ます。
そこで現場で効くのが、抽象的な議論よりも「寄与の証拠設計」です。つまり、どこで誰が創作的判断をしたかを後から説明できる状態を、ログや版管理で作っておくことが重要になります。
実務で使える「創作的決定点(creative decision points)」の整理
区分は、次のような“決定点”ごとに証拠を残す設計が現実的です。
- 生成前の設計:参照素材選定、構図・世界観、制約条件
→ 企画書、ムードボード、素材ライセンス - プロンプト/パラメータ操作:反復調整、ネガティブ指定、モデル選択
→ プロンプト履歴、設定ログ、(可能なら)再現性情報 - 選択・配列:候補からの選定、シリーズ構成、編集方針
→ 採用基準、選定理由、バージョン管理 - 後編集(人手加工):加筆、再構成、レタッチ等
→ 編集データ、差分、作業ログ - 公開・利用の意思決定:表示、配布、商品化
→ 公開履歴、利用条件、承認フロー
プロンプトは「指示」として強く機能する一方で、表現の細部を必ずしも決定しない/同一指示でも結果が揺れる、といった性質があります。だからこそ、プロンプト単体ではなく「反復調整+選択+後編集」まで含めた一連のプロセスを証拠として束ねる設計が、説明可能性を高めます。
学習データの適法性:権利処理を“作品単位”で追いきれない現実にどう備えるか
EU型の示唆:権利留保(オプトアウト)の機械可読化と遵守方針
インターネット規模の学習では、作品単位の許諾を完全に揃えるのが難しい場面があり得ます。EUはこの現実に合わせ、権利留保の識別・遵守を制度上つなぎ、学習データの概要開示を求めることで、完全監査ではなく「透明性とコントロール」を確保しようとしています。
日本で同型の発想を取り入れるなら、まずは契約・ガイドラインで「権利留保の表現」「来歴(provenance)」「調達経路の監査」を標準化し、段階的に制度化する道筋が考えられます。
米国型の示唆:フェアユース以前に“適法アクセス”が前提になり得る
学習行為がどう評価されるかとは別に、データの調達・保管態様が強いリスク要因になり得ます。実務では、データ調達の証跡、提供元の権限、混入物(海賊版・秘密情報・個人情報)の排除が、後工程の取引条件や紛争対応を左右する可能性があります。
責任配分と透明性:結局は「契約で固定し、保険で移転する」設計が効く
役割分担が必要な当事者は想像以上に多い
AI協働創作の関係主体は、創作者/利用者、モデル提供者、サービス提供者、学習データ権利者、被写体・声の本人、発注者・出版社、規制当局、保険者まで広がり得ます。責任が曖昧だと、導入や発注が萎縮し、プラットフォーム規約が一方的になりやすい点が実務リスクになります。
B2B契約の「最小必須セット」
実務でまず整えるべきは、次の条項群です(全部を一度に完璧化するより、適用範囲を絞って確実に運用できる形が現実的です)。
- 入力(Input):入力データの権利、秘密情報・個人情報、再学習利用の可否、保持期間、第三者提供
- 出力(Output):権利帰属(可能範囲)、利用許諾、AI生成部分の定義、再配布可否
- 保証・補償:侵害、違法調達データ、表示義務違反の責任分界、補償範囲、責任上限
- 透明性:生成物の標識、ログ提供、監査対応(域外対応も含む)
- 運用ルール:レビュー体制、禁止用途、エスカレーション、削除対応
保険(E&O/メディア賠償/サイバー等)との整合
契約で責任分担を定めても、残余リスクはゼロになりません。知財侵害、入力データ漏えい、生成物の誤情報・名誉毀損、規制違反などを、保険でどこまでカバーできるかは、導入の意思決定に影響し得ます。特にグローバル提供では、透明性義務が強い地域の要請に合わせた運用が“最低基準”として波及する可能性があります。
産業財産権(特許・商標・意匠):AIは発明者になれない前提で、ログと戦略が差になる
特許では多くの国で「AIは発明者になれない」結論が共通しやすく、実務上は自然人の創作的寄与をどう特定し、共同発明の紛争をどう減らすかが重要になります。
商標・意匠では、生成AIが探索を加速する一方、既存デザイン・標章への近接リスクを増やし得るため、クリアランス(先行調査)と、生成過程・採用理由の記録が、説明責任と紛争予防の観点で意味を持ちます。
まとめ:制度は分岐しても、実務の共通解は「ログ・標識・契約」の三点セット
- AI協働創作は、**学習(インプット)と生成・利用(アウトプット)**に分けて設計すると、論点が整理しやすい。
- EUは透明性義務とGPAI提供者の著作権対応を制度接続し、国際取引の実質標準になり得る。
- 米国は人間著作者性を軸に運用が進む一方、学習適法性は事案で揺れやすく、適法アクセスと調達経路が実務の要所になり得る。
- 英国・中国は制度設計や行政規制の色が異なり、地域差が残るほど、現場は証拠設計(ログ)と透明性(標識)、そして契約での役割分担が効いてくる。
次の一手は、国内のソフトローを核にしつつ、権利留保や標識を“機械可読化”していく段階的移行です。制度の正解が一つに収束しない局面ほど、運用で説明できる形を先に作ることが、コストとリスクの両方を下げる可能性があります。
コメント