NEATとは何か:進化的ニューラルネットワーク探索の基礎
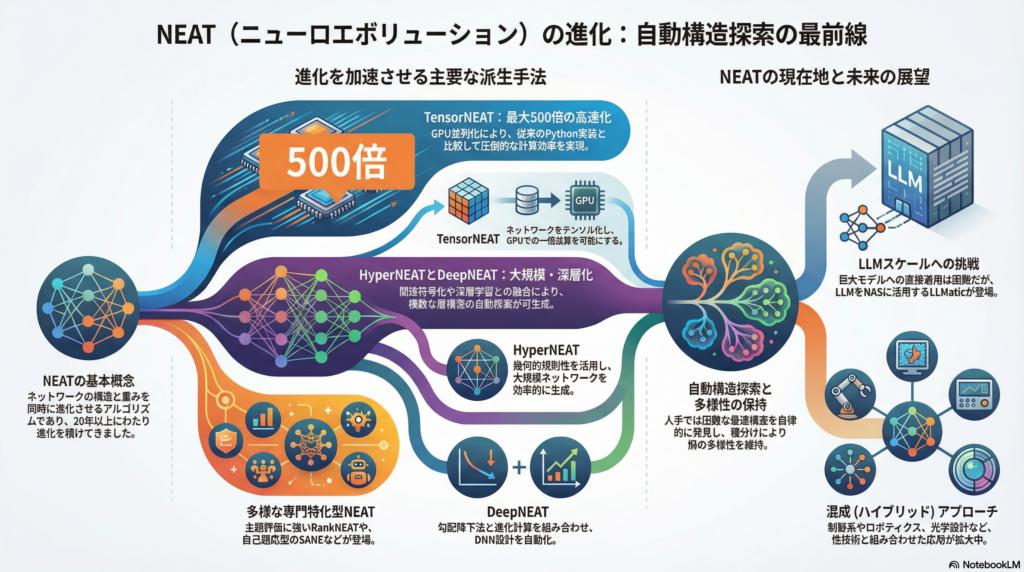
ニューラルネットワークの設計において、最適な構造を見つけることは研究者にとって長年の課題である。NEAT(NeuroEvolution of Augmenting Topologies)は2002年にStanleyとMiikkulainenによって提案された手法で、ネットワークのトポロジー(構造)と重みを同時に進化的アルゴリズムで探索する点に特徴がある。従来の固定構造を前提とした学習とは異なり、NEATは問題の複雑さに応じてネットワークを徐々に複雑化させながら性能を改善していく。
この基本原理を基盤として、過去20年間で様々な拡張手法が登場している。本記事では、NEATの派生技術である HyperNEAT、DeepNEAT、RankNEAT、SANE、TensorNEATなどの特徴を整理し、さらに大規模言語モデル(LLM)時代における応用可能性についても考察する。
主要な派生手法とその特徴
HyperNEAT:大規模ネットワークへの対応
2009年に提案されたHyperNEATは、CPPN(Compositional Pattern Producing Networks)による間接符号化を導入することで、大規模なネットワーク構造を効率的に生成できるようにした手法である。幾何的な規則性や対称性を活用することで、広域なネットワークを少ないパラメータで表現できる点が強みとなる。幾何的タスクや大規模環境での有効性が確認されており、ロボット制御などの分野で応用されている。
DeepNEATとCoDeepNEAT:深層学習との融合
2019年にMiikkulainenらによって提案されたDeepNEATとCoDeepNEATは、深層ニューラルネットワークの時代に対応した拡張手法である。DeepNEATは勾配降下法を併用しながら複雑な層構造を探索する仕組みを持ち、CoDeepNEATはトポロジーとモジュール(サブネットワーク)を同時に進化させることで、より柔軟な構造探索を実現している。これらはDNN設計の自動化に大きく寄与する技術として注目されている。
RankNEAT:主観評価データへの特化
2022年にPinitasらが発表したRankNEATは、主観的な評価データを扱うランキング学習に特化した手法である。感性工学や推薦システムなど、順位付けが重要となるタスクにおいて、NEATでネットワーク構造を進化させることで従来のRankNetなどを上回る性能を示した。人間の主観を扱うデータ領域での有効性が実証されている点で興味深い。
SANE:自己適応型の構造探索
2023年にShuaiらが提案したSANE(Self-Adaptive Neuroevolution)は、構造探索を自己調整する進化アルゴリズムである。型自由の検索空間を定義し、進化中に突然変異率や探索度合いを動的に制御する仕組みを持つ。NEAT由来の種分け(speciation)により多様性を保持しながら、CNN、GAN、LSTMなど多種多様なDNNアーキテクチャで小規模構造を自動生成できる。
TensorNEAT:並列化による高速化の実現
NEATの大きな課題であった計算効率の問題に対し、2024年にZepedaらが提案したTensorNEATは画期的な解決策を示した。ネットワーク個体を均一なテンソルに変換し、個体群を一括演算する手法により、GPU上での並列実行を可能にしている。従来のNEAT-Python実装と比較して最大500倍の高速化を実現しており、Braxなどの物理シミュレーション環境で評価されている。
近年の研究動向と応用領域の拡大
混成フレームワークへの組み込み
NEATは制御系や設計問題の自動最適化に応用が広がっている。例えば光学メタサーフェス設計では、NEATによりニューラルモデルの構造を進化させ、深層学習パイプラインに組み込む手法が報告されている。このように、NEAT単体ではなく他の技術と組み合わせる混成アプローチが増加している。
人工生命・ロボティクス分野での活用
人工生命学会(ALIFE)やロボティクス関連学会では、NEATを用いた仮想生物の形態・行動の共進化研究が継続的に報告されている。鈴木礼氏らは2023年のALIFEおよびAROBで「NEATを用いた人工生物の形態・行動進化」に関する研究を発表しており、NEATの探索多様性を活かしたエージェントのモジュール設計などに応用している。進化的アプローチの柔軟性が、創発的な振る舞いを生み出す研究に適していることが示されている。
新たな応用事例の登場
RankNEATやSANEに見られるように、NEAT系アルゴリズムの応用領域は拡大を続けている。主観評価データのランキング学習や、異なるタイプのDNN構造の自動構築など、従来の画像認識や制御タスクにとどまらない応用が進んでいる。
大規模言語モデル(LLM)への応用可能性
直接適用の困難性
GPTなど数十億から数百億のパラメータを持つLLMに対して、NEATのような進化アルゴリズムで構造最適化や学習を行うことは、現状では事実上不可能とされている。AI専門家の指摘によれば、NEATなど勾配を用いない進化手法は大規模パラメータと膨大な訓練データの両面で非常に非効率であり、訓練時間が指数的に増大してしまう。そのため、現実的なLLM学習には引き続き勾配降下法が用いられており、NEAT系手法はスケール上の限界に直面している。
LLM技術とNASの融合
一方で、LLMの能力をニューラルアーキテクチャ探索(NAS)に活用する研究は始まっている。LLMaticと呼ばれる手法では、LLMのコード生成能力を使ってニューラルネットワークの構成を変異させ、Quality-Diversity(QD)手法と組み合わせることで多様性を重視した探索を実現している。これはLLM自身を直接進化的学習に使うのではなく、LLMの知識を活用した新しいNAS手法として注目される。
現状では、NEAT系手法がLLM内部構造の最適化に直接用いられた例は知られていないが、LLM技術を活用したアーキテクチャ探索の研究は登場している。ただしNEAT自身はLLMスケールには向かないため、LLM構造最適化で進化手法を検討する場合、大規模対応の新手法やハイブリッドアプローチが必要となる。
NEAT系手法の利点と課題
主な利点
NEAT系手法の最大の利点は自動構造探索にある。人手では設計困難な最適トポロジーを自律的に発見でき、タスクに応じてネットワークの複雑度を動的に調整できる。また、種分けやエリート選択などにより多様なモデル群を同時並行で探索でき、局所最適からの脱出に寄与する。勾配非依存であるため、非微分可能な評価関数や強化学習、進化ゲームなど多彩な問題に適用可能な点も強みである。
主な課題
一方で計算コストの高さは大きな課題となっている。個体群ベースの探索は学習ステップが非常に多く、特に大規模ネットワークでは訓練時間が膨大になりがちである。現行実装の多くは個々のネットワークをオブジェクト指向プログラミングで管理するため、大規模ではメモリと演算オーバーヘッドが増大する。
スケーラビリティも課題である。既存のNEATライブラリは主にCPU実装で、全体の進化過程を逐次的に行うため大規模並列化が困難だった。TensorNEATはGPU並列化を実現したが、まだ発展途上の段階にある。
さらに、NEAT-PythonやPyTorchNEATなどのライブラリは存在するものの、ResNetやTransformerのような先端DNNに即した柔軟な実装は少ない。神経進化分野の実装整備が進めば普及が加速する可能性がある。
代表的な研究機関とプロジェクト
主要な研究グループ
NEAT系手法の研究は世界各地で進められている。英国のシェフィールド大学EMI-GroupはTensorNEATを開発し、GPU化による高速化を実現した。マルタ大学のYannakakis研究室はRankNEATなど神経進化研究で知られ、中国の哈爾浜工業大学(Harbin Institute of Technology)はSANEを開発している。米国テキサス大学ダラス校のMiikkulainen研究室はDeepNEATとCoDeepNEATの開発元として、深層学習との融合を推進している。
主要ライブラリ
TensorNEATはGitHub上でEMI-Group/tensorneatとして公開されており、GECCO 2024での発表論文と共に利用可能である。NEAT-Pythonは2023年にMcIntyreによって整備された汎用NEAT実装で、多くの研究で基盤として用いられている。PyTorchNEATはGajewskyが2023年に公開したPyTorch実装で、GPU推論が可能だが学習部は逐次処理となっている。その他、MultiNEATやMonopolyNEATなど旧ライブラリも存在する。
NEAT系アルゴリズムは依然としてニューラルアーキテクチャ探索の有力手法の一つであり、特にアルゴリズムの高速化(並列化・GPU化)や多様なタスクへの適用拡大が最近のトレンドである。進化的アプローチの新たな方向性として、自己適応やLLM連携など、様々な可能性が模索されている。
まとめ:進化的アプローチの未来
NEATとその派生手法は、ニューラルネットワークの構造を自動的に探索する強力なアプローチとして20年以上にわたり発展を続けている。HyperNEATによる大規模対応、DeepNEATによる深層学習との融合、TensorNEATによる並列化など、時代のニーズに応じた進化を遂げてきた。
現在のLLM時代においては、直接的な適用は困難であるものの、LLMの能力を活用した新しいアーキテクチャ探索手法が登場するなど、進化的アプローチと最新AI技術の融合も始まっている。計算効率やスケーラビリティの課題は残るものの、勾配法では対応困難な問題領域において、NEAT系手法の価値は今後も維持される可能性が高い。
次に掘り下げるべきは、ハイブリッドアプローチの可能性や、量子コンピューティングなど新しい計算基盤との組み合わせであろう。進化的アルゴリズムの柔軟性と自動化の利点を活かしながら、現代的な大規模問題にどう適用していくかが、今後の研究テーマとなる。
コメント