対話AIにおける相互補完的理解の重要性
現代の対話システムでは、AIが単に質問に答えるだけでなく、人間と協調して効果的にコミュニケーションする能力が求められています。この実現の鍵となるのが「相互補完的理解」です。相互補完的理解とは、人間とAIがお互いの意図・知識・能力を共有し合い、不足を補完し合うことで円滑な対話や共同作業を可能にする理解状態を指します。
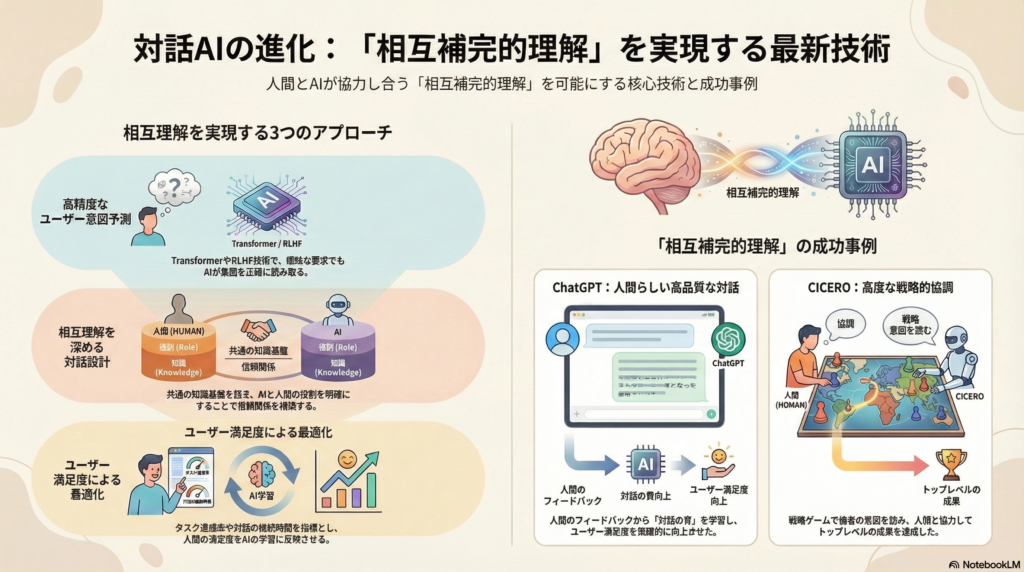
本記事では、この相互補完的理解を最適化するための最新技術と研究動向を、AIによる意図予測手法、対話設計の工夫、評価指標、そして実際の応用事例という4つの観点から詳しく解説します。
AIによるユーザー意図・行動予測の最新手法
Transformerベースモデルによる高精度な意図検出
対話システムにおけるユーザー意図の理解は、効果的なコミュニケーションの基盤です。近年、大規模言語モデル(LLM)に代表されるTransformerベースのアーキテクチャが、この課題に革新をもたらしています。
タスク指向対話では、ユーザー発話から「インテント(意図)」を検出し、必要な情報である「スロット」を抽出することが基本的な処理となります。Wang氏らの2023年の研究では、Transformerエンコーダに双方向LSTMと条件付き確率場(CRF)を組み合わせたモデルを提案し、従来手法を上回る精度でユーザーの意図検出とスロット充填を実現しました。
このような技術進化により、AIはユーザーの入力テキストから意図や目的を高精度に推定できるようになっています。Transformerの強力な文脈理解能力に他の構造を統合することで、曖昧な表現や複雑な要求にも対応可能な対話システムが実現しつつあります。
RLHF:人間のフィードバックを活用した最適化
Reinforcement Learning from Human Feedback(RLHF)は、言語モデルの出力を人間の好みに合わせて最適化する革新的な手法です。ChatGPTをはじめとする最新の対話AIで広く採用されているこの技術は、相互補完的理解の実現に大きく貢献しています。
RLHFでは、人間の評価を報酬信号として学習プロセスに組み込むことで、モデルがユーザーの意図や期待に沿った振る舞いを学習します。OpenAIのInstructGPT研究では、RLHFを通じてユーザーの指示への忠実度や有用性が大幅に向上し、人間評価では従来のGPT-3よりも71%の割合で好ましい応答を生成できたと報告されています。
興味深いことに、パラメータ規模が大幅に小さいInstructGPT(13億パラメータ)が、はるかに大規模なGPT-3(1750億パラメータ)を上回る評価を得ました。この結果は、モデルの巨大さよりも人間との相互作用から学習した「対話の質」がユーザー体験を左右することを示しています。
RLHFによって、AIはユーザーの望む回答を予測・優先する能力を身につけ、危険な出力を回避しつつ要求に沿った応答が可能になります。人間の満足度を報酬として組み込むこの手法は、AIが暗黙的にユーザーの意図を推測・最適化する強力なアプローチとなっています。
認知アーキテクチャによる高度な予測と計画
ブラックボックス的なLLM単体ではなく、人間の認知過程を模したアーキテクチャを取り入れる研究も注目されています。Sumers氏らが2024年に提案したCoALA(Cognitive Architectures for Language Agents)は、LLMに長期記憶モジュールや推論・検索といった機能を統合し、内外の情報を使って計画・意思決定できるエージェント枠組みを示しました。
このような認知アーキテクチャでは、対話履歴や世界知識を記憶し活用することでユーザーの状態や次の行動を予測しやすくなります。また、大規模モデルに他者の心的状態を推論する能力(Theory of Mind)を付与する研究も進展しています。
Hwang氏らが2025年に開発したToMエージェントは、対話中に相手の心的状態推論を挿入することで、モデルが対話相手の信念・意図を推測しながら応答できるようにしました。この研究では、対話の目的達成率や協調性が向上することが実証されています。
これらの成果は、AIがユーザーの内面的な意図・感情まで見越して対話戦略を調整できる可能性を示しています。Transformerの性能に人間からのフィードバックや認知的推論能力を組み合わせることで、AIがユーザーの次の発話や望む行動を予測し、先回りして支援する高度な対話が実現しつつあります。
相互理解を深める対話設計の工夫
コモングラウンド(共通基盤)の構築
円滑な対話には、互いに共有する知識や前提、すなわちコモングラウンドを持つことが不可欠です。人間同士の対話理論では、自分と相手の共有知識・目標・意図を確認しながら会話を積み重ねる「グラウンディング」が重要とされています。
しかし、従来のチャットボットではこの共通基盤の構築が軽視されがちでした。最新の研究では、対話システムがユーザーとの間で何が共有されているかを追跡・管理する手法が模索されています。
Anikina氏らが2025年に発表したサーベイでは、コモングラウンドを「モダリティ(言語・視覚など)」「タイプ(静的知識か対話で生成された動的情報か)」「スコープ(個人的経験から常識まで)」といった次元で整理し、各次元で共通基盤をモデル化する研究をまとめています。
共通の対話履歴の共有もその一環であり、システムが対話履歴を記憶して参照するだけでなく、必要に応じてユーザーに再確認したり要約して提示するインターフェースも検討されています。長い対話履歴を的確に文脈として扱い矛盾を避けることが、ユーザーから信頼される対話システムの前提となっています。
共通基盤を築く設計によって、ユーザーとAIが「同じページにいる」という安心感や信頼が生まれ、対話の効率と質が向上します。
メンタルモデルの相互構築
人間とAIがお互いを理解し補完し合うためには、相互のメンタルモデルの構築が重要です。メンタルモデルとは、相手の状態・知識・意図に関する頭の中のモデルを指します。
AI側では前述のTheory of Mind能力の付与などによりユーザーの内面状態を推測する一方、ユーザー側にもAIの能力・限界を理解してもらう工夫が不可欠です。説明可能AI(XAI)の手法を対話に組み込み、AIが自身の判断根拠や次の行動意図をユーザーに適度に開示することでユーザーの安心感を高める試みも報告されています。
認知科学やヒューマンコンピュータインタラクションの知見では、効果的なチームではメンバー間でタスクの目的や各自の役割に関する共有メンタルモデルが形成されており、これが誤解の減少や協働のスムーズさに直結します。
対話システム設計においても、AIがユーザーの意図を推論するだけでなく、ユーザーがAIの動作意図を理解できる双方向の透明性が求められています。
イニシアチブと役割の明確な分担
対話における主導権(イニシアチブ)の取り方や役割分担の明確化も、相互理解を深める重要な設計要素です。人間とAIの協調対話では、一方が一方的にリードするよりも、状況に応じて主導権を動的に交替(ミックスド・イニシアチブ)することが望ましいとされています。
Lin氏らが2024年に実施した研究では、人間とAIが協働で意思決定を行う「意思決定指向対話」を定義し、旅行日程計画や交渉シナリオでの対話実験を行いました。この研究では、AIアシスタントとユーザーの能力の違いに着目しています。
AIは膨大な情報処理や最適計算が得意であり、一方でユーザーは個人的な嗜好や暗黙知を持っています。両者が情報と判断を出し合って協働することで、最良の意思決定が可能になります。実際、AIは候補を計算して提案し、人間はそれを評価・選択するという役割分担が有効であると示されています。
このような設計では、AIが自律的に提案や質問(プロアクティブ対話)を行う一方、人間が最終決定権を持つ形で対話が進行します。役割分担が明確になることで、ユーザーはAIをパートナーとして信頼しやすくなり、AIもユーザーの判断を尊重しつつ必要な支援を提供できるようになります。
ユーザー満足度を指標とした最適化アプローチ
ユーザー満足度評価の重要性
人間とAIの相互理解の度合いを評価・最適化する上で、ユーザーの満足度は欠かせない指標です。対話システムの研究・開発では近年、ユーザー満足度を定量・定性の両面から計測し、モデル改善にフィードバックする枠組みが広がっています。
満足度の高さは、ユーザーのニーズや意図が正しく理解され応答に反映されていることの表れであり、相互理解の達成度合いを示すものと考えられます。Microsoft研究者らは、ChatGPTやBing Chatのような汎用対話システムからカスタマーサービス向けチャットボットまで、多様なシステムにおけるユーザー満足・不満足のパターンを分析しています。
彼らが提案したSPURと名付けられた評価手法では、ユーザー発話中の肯定・否定的反応や訂正の有無などから満足度スコアを推定し、精度と解釈性を両立しています。これは、満足度を単なる数値でなく対話中の具体的な行動・発話パターンとして把握し、どの部分で相互理解が損なわれたかを診断するアプローチです。
主観評価と客観指標の組み合わせ
ユーザー満足度は本来主観的なものですが、研究では主観評価と客観的指標の組み合わせが試みられています。主観評価としては、対話後にユーザーにアンケートで満足度を数段階評価してもらう方法が一般的です。
一方、客観指標としては、タスク達成率(要求された情報を正しく提供できたか)、対話継続時間やターン数(ユーザーがどれだけ会話を続けたか)、誤解・訂正の頻度(ユーザーが訂正した回数など)といったデータが用いられます。
タスク指向システムでは最終的にユーザーの目的が成功したかをエラー回避率あるいはタスク成功率として定義し、これをユーザー満足度と相関づけて評価します。チャットボットの分野では、対話がどれだけ自然かつストレスなく続いたかも信頼性の指標となります。
最新の研究では、これら客観指標をリアルタイムにモニタリングし、モデルが自動的にユーザーの満足度低下を検知して戦略を調整する試みもあります。例えば応答候補ごとに「ユーザーが満足しそうか」を予測し、最も満足度が高まるであろう応答を選ぶプロアクティブな対話マネージャが提案されています。
多面的な満足度指標を学習の報酬関数や評価関数に組み込むことで、モデルを人間とのより良い相互理解に向けて最適化するアプローチが広まっています。
RLHFにおける満足度の暗黙的最適化
前述したRLHFは、人間のフィードバックを直接モデル訓練に取り入れるもので、ある意味ユーザー満足度を暗黙の指標として最適化しているとも言えます。人間ラベラーが「どちらの応答が好ましいか」を比較評価して訓練した報酬モデルは、ユーザーが感じる質の良さをスコア化したものとみなせます。
RLHFにより学習されたモデルは、従来モデルに比べユーザーの意図への適合性や回答の一貫性が大きく向上します。一方で研究者は、RLHFの報酬モデルがブラックボックス的で「なぜその会話が高スコアなのか」を説明できない問題も指摘しています。
そこで、内省可能な満足度推定(会話中の具体的満足・不満要因を分析する手法)を組み合わせ、モデル改善の解釈性と効率を高めようという動きもあります。人間の満足度を軸とした評価・最適化は、相互理解を深める対話システムの開発において中心的な役割を果たしています。
実システムにおける応用事例
ChatGPT:RLHFによる相互理解の実現
ChatGPTは大規模言語モデルにRLHFを適用した代表例であり、ユーザーの意図汲み取りと応答品質の高さで対話システムの性能水準を引き上げました。InstructGPT研究では、RLHFによりモデルがユーザーの指示に従順かつ有用になるだけでなく、ユーザー満足度が飛躍的に向上したことが示されています。
この結果は、モデルの巨大さよりも人間との相互作用から学習した「対話の質」がユーザー体験を左右することを示唆しています。ChatGPTはユーザーの曖昧な質問意図にも追加質問で確認したり、過去の対話文脈を保持して整合性のある応答を返すなど、相互補完的理解に基づく対話マナーを備えています。
その背景には、膨大な対話データから学んだ暗黙的な常識的対話スキルに加え、RLHFで強化された人間らしいフィードバック対応能力があります。結果として、ChatGPTは多様なユーザーと円滑にコミュニケーションでき、実システムにおけるユーザー満足度指標でも高スコアを記録しています。
CICERO:戦略的協調対話の実現
Meta社が2022年に発表したCICEROは、人間同士で行う戦略ゲーム「外交(Diplomacy)」で人間レベルの交渉・協調プレイを実現したAIエージェントです。Diplomacyは7人のプレイヤーが同盟や裏切りを駆使して領土を争う高度なゲームで、単に盤面戦略を立てるだけでなく他者の動機・視点を理解し、言葉で説得し協力関係を築く必要があります。
CICEROは言語モデルと計画アルゴリズムを統合し、対話から推測した各プレイヤーの信念・意図に基づいて最適な戦略を立案し発話するというアプローチを取りました。具体的には、過去の会話内容やボード状況から「各人が次にどう動くか」を予測し、その上で「互いに利益となる協調案」を考え出し、自然言語で提案・交渉するよう設計されています。
実験では、CICEROはインターネット上の匿名Diplomacy大会で40ゲーム中平均スコアが人間の2倍以上となり、上位10%の人間プレイヤーに匹敵する成果を収めています。
興味深いことに、CICERO開発チームは自己対戦のみで訓練したエージェントは人間と協調できなかったと報告しています。自己プレイ最適化では人間には理解不能なやり取りや非協力的戦略が生まれてしまい、人間の常識・期待に反する振る舞いになっていました。
そこで人間の対話データを用いた学習やルール調整により、人間のコミュニケーションの文脈に即した発話を行うようにチューニングしました。このケーススタディは、高度に戦略的な協調対話においてもAIが人間の意図を読み取り、自身の提案を文脈に適合させ、人間と信頼関係を築きながら目標を達成できることを示しました。
その他の実用システムにおける展開
ユーザー満足度を指標に最適化された対話システムの例として、Amazonが開催したAlexa Prizeチャレンジのソーシャルボットも挙げられます。これらのシステムは長時間ユーザーと会話を続けられること(エンゲージメントの長さ)やユーザーからの星評価が高いことを目標に設計・強化学習されました。
ある受賞システムでは、ユーザーの発話から興味を推定して話題を自発的に提案・転換する対話戦略を用い、ユーザーが退屈したり行き詰まったりしないよう工夫しています。また、タスク指向の実システムでは顧客満足度調査と対話ログ分析からボトルネックとなる誤解ポイントを特定し、システム改善に活かすPDCAサイクルも確立されつつあります。
研究段階ではありますが、対話におけるユーザーの表情や音声トーンなどのマルチモーダルな満足度シグナルを検知してAIの応答感情や丁寧さを動的に変える試みも報告されています。
まとめ:相互補完的理解の未来
人間とAIの相互補完的理解の最適化は、単なる技術的課題を超えて、これからの社会におけるAIとの協調のあり方を決定づける重要なテーマです。本記事で紹介した最新の研究動向から、以下の重要なポイントが浮かび上がります。
第一に、TransformerやRLHFといった技術進化により、AIはユーザーの意図を高精度に予測し、人間の期待に沿った応答を生成できるようになっています。第二に、コモングラウンドの構築やメンタルモデルの相互形成といった対話設計の工夫により、人間とAIの信頼関係が深まりつつあります。第三に、ユーザー満足度を多面的に評価し最適化する枠組みが確立され、実用システムでも成果を上げています。
ChatGPTやCICEROといった実例は、これらの技術が統合されることで、AIが単なる応答機械ではなく、人間と協調して目標を達成するパートナーとなりうることを示しています。今後は、より長期的な文脈理解、複雑なマルチモーダル対話、そして倫理的配慮を含む総合的な相互理解の実現が期待されます。
対話AIの進化は始まったばかりです。人間とAIが真に補完し合える関係を築くため、技術開発と人間理解の両面からのアプローチが今後も求められていくでしょう。
コメント