はじめに:脳とAIが共有する情報処理の原理
脳の視覚系と人工知能の強化学習エージェントは、一見まったく異なる存在に思えます。しかし、両者を詳しく見ていくと、情報を階層的に処理し、フィードバックによって予測を修正するという共通の計算原理が浮かび上がってきます。
本記事では、ヒトや霊長類の視覚野における情報フローと、Deep Q Network(DQN)やActor-Criticといった強化学習エージェントの処理構造を比較します。階層性、時間的統合、フィードバックの役割という3つの観点から、脳とAIの類似点と相違点を明らかにし、今後のAI設計への示唆を探ります。
視覚野の階層構造:V1から高次領野への情報の流れ
フィードフォワード経路による特徴抽出
ヒトの視覚野は階層的な構造を持ち、一次視覚野(V1)から高次視覚野(V2、V4、IT)へと情報が順次伝達されます。V1のニューロンは小さな受容野を持ち、エッジや線分といった単純な特徴に選択的に反応します。一方、V4やIT野では受容野が広がり、複雑な形状やオブジェクトに選択的なニューロンが現れます。
この階層構造では、下位領野から上位領野へ進むにつれて表現される特徴の抽象度が高まります。視覚情報は腹側経路(V1→V2→V4→IT、物体の「何」を認識)と背側経路(V1→MT/V5→後頭頂皮質、「どこ」「どのように」を処理)という2つの並行ルートに分岐し、それぞれ異なる役割を担います。
フィードバック経路の解剖学的特徴
視覚野では、高次領野から下位領野へのフィードバック経路も存在し、双方向の結合が形成されています。フィードフォワード結合は下位領野の深部から上位領野の第4層へ投射し、強い駆動性を持ちます。対照的に、フィードバック結合は上位領野の深部から下位領野の表層へ投射し、主に調節的な影響を与えます。
フィードフォワード結合は網膜対応が精密で、厳密に対応する視野部位間を結びます。一方、フィードバック結合は網膜対応が粗く、広域的な影響を及ぼします。また、時間的にも両者は異なる役割を果たします。フィードフォワード信号は刺激提示直後の早い時相で卓越し、刺激開始後数十ミリ秒で下位から上位へ情報が伝達されます。フィードバック信号はやや遅れて出現し、刺激持続中から消失後の後期応答で優位になります。
強化学習エージェントにおける階層的情報処理
Deep Q Networkの多層構造
強化学習エージェント、特にDeep RLモデルにも、観察から状態表現、価値予測へと至る階層的な情報フローが存在します。DQNでは、生の画像を畳み込みニューラルネットワーク(CNN)によって多層の特徴表現に変換し、最終的に各行動のQ値を出力します。
DQNの畳み込みネットワークは、視覚野における受容野の階層的拡大と類似しています。開発者らは「階層的にタイル状に配置した畳み込みフィルタが視覚野V1で発見された受容野の効果を模倣する」と述べており、生物学的な視覚処理からインスピレーションを得た設計となっています。
実際、DQNの中間層が学習する状態表現は、人間のプレイヤーがゲーム状況を認識する際の脳活動パターンと相関することが報告されています。これは、DQNの隠れ層が人間の脳と類似した状態空間表現を形成していることを示唆します。
Actor-Critic構造における情報の分岐
Actor-Critic型の強化学習エージェントでは、情報フローが政策決定と価値評価という2つの経路に分かれます。観察入力から始まり、ニューラルネットワークが潜在的な状態表現を抽出します。その後、Actorネットワークが行動を選択し、Criticネットワークがその状態の価値を推定します。
Actorは環境においてポリシーに従い行動を出力し、Criticはその行動の結果得られた報酬を用いて状態・行動の価値を評価します。この2つの流れは並行して学習され、ActorはCriticからのフィードバック(TD誤差)を受け取ってポリシーを更新し、Criticは実際の報酬と予測値との差に基づいて価値関数を更新します。
このActor-Critic構造は、生物学的にも大脳基底核の直接路(Actor)とドーパミン報酬誤差信号(Critic)の関係に対応すると考えられており、脳の強化学習機構を工学的に取り入れたものと捉えることができます。
階層構造と時間的統合:脳とエージェントの比較
階層性における共通点と相違点
脳の視覚系とDeep RLエージェントは、いずれも多段階の処理階層を持ち、下位レベルでは単純な特徴、高位レベルでは複雑な表現を担う点で類似しています。人工ニューラルネットワークと霊長類視覚野の対応を調べた研究でも、ネットワークの浅い層はV1/V2の活動と、深い層はITの活動と粗く対応することが示されています。
しかし、脳の階層は必ずしも一方向の直鎖ではありません。並行経路(腹側経路と背側経路)や同一レベルでの局所回路も多く存在し、視覚情報は並列する複数の流れで同時処理されます。階層間の再帰的なフィードバックも加わるため、脳内情報処理は厳密な順列構造というよりネットワーク的です。
対照的に、多くのDeep RLネットワークは一つの入力から一直線に出力へ至るフィードフォワード型の階層を採用しており、並行経路や双方向のやりとりは限定的です。ただし、最近ではマルチモーダルな並行ネットワークやTransformer型ネットワークなど、よりリッチな構造を持つエージェントも登場しています。
時間的統合のメカニズム
脳の視覚野では、刺激に対する応答は数十ミリ秒の短い時間窓でまずフィードフォワード的に生起し、その後数百ミリ秒にわたり再帰的回路によって洗練・統合されます。初見の画像を認識するにはおおよそ100ms程度のフィードフォワード処理で足りる一方、曖昧な図形の解釈や隠れた対象の知覚には200ms以上かけたフィードバック処理が精度向上に寄与します。
さらに、視覚を含む脳全体では強化学習的な長期スパンの統合も存在し、報酬予測や意思決定において数秒から数分の過去経験を統合する機構(ドーパミン報酬予測誤差や海馬のエピソード記憶)が働いています。
一方、強化学習エージェントでは環境との相互作用が離散的な時刻ステップで定義され、報酬はしばしば行動のかなり後に遅れて得られるため、時間に沿った情報の統合とクレジット割り当てが重要な課題となります。モデルフリー強化学習ではTD誤差という形で逐次的に予測を更新することで長期的な結果を統合します。
中脳ドーパミンニューロンの一過性発火パターンはTD誤差のように振る舞い、線条体でのドーパミン依存的な可塑性変化が強化学習の重み更新に相当することが示唆されています。Deep RLではニューラルネットの誤差逆伝播がこれに対応し、経験終了後に一括して重みが更新されます。
フィードバックの役割:予測、誤差補正、選択的注意
視覚野における予測コーディング
視覚野のフィードバック経路は、上位からの予測情報の伝達、ボトムアップ信号の誤差訂正、注意や文脈による選択的な情報増幅など、多岐にわたる役割を担います。
予測コーディング理論では、高次皮質が生成した予測モデルをフィードバック経路で下流に送り、実際の感覚入力との差分(予測誤差)を計算します。トップダウン予測がV1のニューロンに降りてきて、それに合致する部分は説明済みとして抑制され、合致しない部分のみが誤差としてV1からV2へ上がるという計算が行われています。
これにより、脳はノイズや予測された当たり前の情報を無視し、本当に新規で意味のある誤差情報だけを上位に伝える効率的な符号化を実現している可能性があります。
フィードバックによる図地分離と輪郭統合
V4からV1へのフィードバックをサルで一時的に遮断する実験では、V1ニューロンの応答が図形の輪郭や表面の文脈に基づく促進・抑制効果を失い、動物の図地知覚性能も低下しました。これは、V4→V1フィードバックが図と地の統合的な知覚に必須であり、主に刺激後半の遅い相でV1の活動を調整する役割を持つことを示しています。
V1が局所特徴に基づいて出した初期応答を、V4からのフィードバックが「それは大きな輪郭の一部だ」と再解釈して応答を持続・増幅させるという誤差修正・補完が行われていると考えられます。
選択的注意とトップダウン制御
フィードバック経路は注意の神経機構の主要素でもあります。注意を向けるとV1やV4のニューロン応答が増強すること、注意の焦点に関連しない刺激の応答が抑制されることが報告されており、この効果は上位の注意制御領野(前頭眼野や上頭頂葉など)から視覚野へのフィードバックで実現していると考えられます。
注意や期待、課題目標といったトップダウン情報は視覚野ニューロンの受容野特性を状況に応じて可塑的に変化させ、同じ入力でも異なる意味を持つ信号へと変換します。トップダウン信号が「今注目すべき特徴はこれだ」という選択バイアスをかけることで、視覚処理全体の出力が現在の行動目標に適した内容になります。
強化学習エージェントにおけるフィードバックと学習
報酬予測誤差による内部モデルの更新
強化学習エージェントにおけるフィードバックは、主に学習面で現れます。エージェントは環境相互作用を通じて外部からの報酬フィードバックを受け取り、これを元に内部モデル(政策や価値関数)の誤差修正を行います。
具体的には、エージェントの出力した行動の結果得た報酬と、自身の予測した価値とのズレ(報酬予測誤差)が計算され、それがニューラルネットの重み更新(バックプロパゲーション)による内部状態の調整として実現します。
DQNではQネットワークの出力Q値と、取得した報酬+次状態から算出される目標Q値との差分が誤差となり、これをネットワークに逆伝播して重みを更新します。Actor-CriticではCriticが算出したTD誤差がActorネットワークへフィードバックされ、「予想より良かった/悪かった」方向にポリシーを勾配上昇で更新します。
脳の学習機構との対応
強化学習エージェントにとってのフィードバック信号とは「予測に対する外部からの評価」であり、将来の意思決定を改善するよう内部表現を変化させる役割を果たします。これは脳におけるドーパミン報酬予測誤差の役割と対応しており、ドーパミンが増減することで皮質-基底核シナプスの重み付けが強化・弱化され、行動選択の方策が修正されるという仕組みと並行的です。
実際、ドーパミンニューロンの活動とTD誤差信号の類似、ドーパミン依存的な線条体可塑性と強化学習の重み更新の類似が指摘されており、Actor-Criticアルゴリズムは生物の強化学習を定量化したモデルと見ることができます。
注意機構の導入
従来のDeep RLには選択的注意に相当する機構は明示的に組み込まれていませんでしたが、近年のモデルでは視覚的注意機構を導入する試みもあります。強化学習エージェントに注意モジュール(self-attentionや視線制御)を追加し、観察の中でタスクに重要な部分に重み付けして処理させる手法が研究されています。
こうした注意型の強化学習モデルでは、不要な入力ノイズを無視して効率よく学習できることが報告されており、脳の注意メカニズムの有用性を裏付けています。
機能的類似点と相違点、今後の展望
共通する計算原理
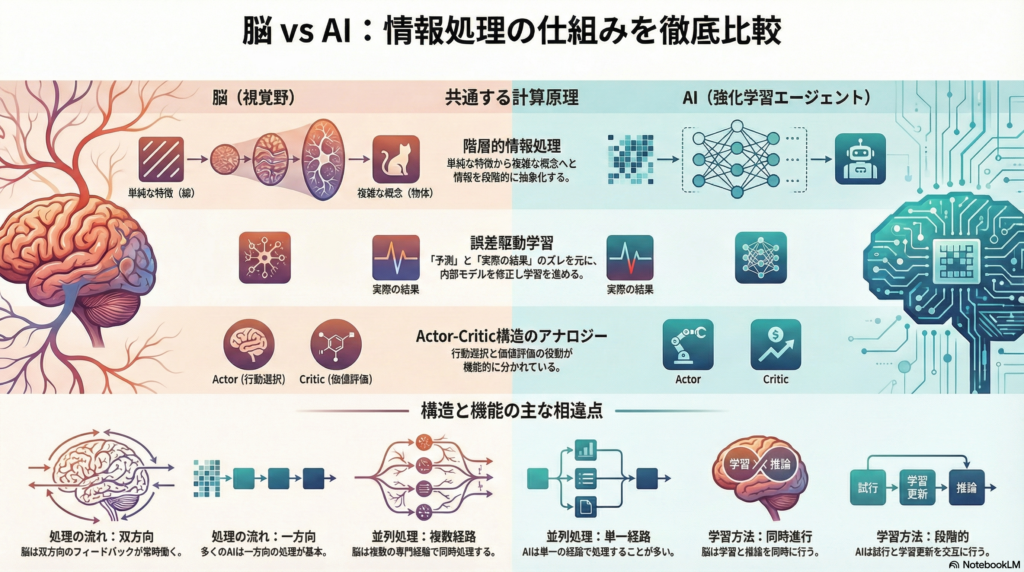
視覚野とDeep RLエージェントには、以下のような機能的類似点が存在します:
階層的情報処理: 両者とも多層の階層構造によって情報を逐次変換し、高度な特徴表現を得るという共通の原理で動いています。CNNの層と視覚野の領野は粗く対応し、下層で基本的特徴検出、上層で統合と抽象化を行います。
誤差駆動学習: 脳における予測誤差のフィードバック(ドーパミン報酬予測誤差や視覚予測誤差)は、Deep RLにおけるバックプロパゲーションによる誤差修正と対応しています。いずれも「予想」と「実際」の差を計算し、それを用いて内部状態を更新するプロセスです。
Actor-Critic構造: 強化学習アルゴリズムのActor-Critic分離は、脳の行動選択系(前頭皮質・基底核)と価値評価系(ドーパミン系)の機能分化とアナロジーがあります。脳のアーキテクチャと対応するAIアルゴリズムが互いに有効性を裏付け合っている例と言えます。
主要な相違点
一方で、以下のような重要な差異も存在します:
再帰性とリアルタイム処理: 脳は大規模かつ密な再帰結合ネットワークであり、視覚処理でさえ常時トップダウン・ボトムアップの相互作用が存在します。対して、多くのDeep RLモデルは基本的にフィードフォワード型で、学習時以外には明示的な再帰的フィードバックがありません。
並行処理経路: 脳の視覚系は腹側・背側など複数の並行ルートや、各領野内でも色・形・運動といったモジュールに分かれる高度な並列処理を行います。典型的なDeep RLネットは単一の逐次ネットワークであり、情報の流れが一元化されています。
学習と推論の統合: 脳は学習と推論を並行して行う(常にシナプス可塑性や予測更新が起き続ける)のに対し、Deep RLは試行と学習更新が交替で起こります。これにより、脳は少数の経験から素早く一般化・適応できますが、人工エージェントは多数のトライアルを要する場合があります。
AI設計への示唆
これらの比較から、脳の仕組みを模倣・応用することでAIアーキテクチャを改良できる可能性が見えてきます。脳の並行・再帰的処理を取り入れたネットワークは、より頑強で柔軟な知覚判断が期待できます。予測コーディング型のニューラルネットは、データ効率やロバスト性で利点を示す可能性があります。
トップダウン注意メカニズムを強化学習エージェントに組み込むことで、観察処理の効率化や解釈性向上が図れるでしょう。また、脳のモジュール性を真似た階層的強化学習(オプションやスキルの階層)も有望な方向性です。
逆に、AI研究から脳へのフィードバックもあります。Deep RLの成功事例は、Actor-Criticのように脳の計算役割分担の仮説を支持したり、畳み込みネットのように視覚野の計算理論に定量的な裏付けを与えたりしています。
まとめ:神経科学とAIの相互作用が拓く未来
視覚野と強化学習エージェントは、情報処理の階層性という共通基盤を持ちながらも、フィードバック利用、並行性、学習と推論の統合において相違があります。その比較研究から得られる知見は、脳を解明するヒントになると同時に、より知的で効率の良いAIシステムの設計にも貴重な示唆を与えています。
今後、脳型のフィードバック回路や学習則を取り入れたAI、AIの計算原理から発想を得た脳の理論モデルが一層発展することで、両分野の深化と融合が期待されます。神経科学とAI研究の協調は、人間の知能の理解と人工知能の進化という二つの目標を同時に前進させる可能性を秘めています。
コメント