マルチモーダル世界モデルがロボティクスにもたらす変革
ロボット工学における最大の課題の一つは、未知の環境やタスクに対する一般化能力の獲得です。従来のロボット制御システムは特定のタスクに特化した設計が主流でしたが、近年の深層学習とマルチモーダル基盤モデルの発展により、視覚・言語・行動を統合的に扱う世界モデルの研究が急速に進展しています。本記事では、これらの最新研究動向と一般化能力の評価手法、そして今後の展望について詳しく解説します。
主要なマルチモーダル世界モデルのアーキテクチャ
Gato:マルチタスク対応のジェネラリストエージェント
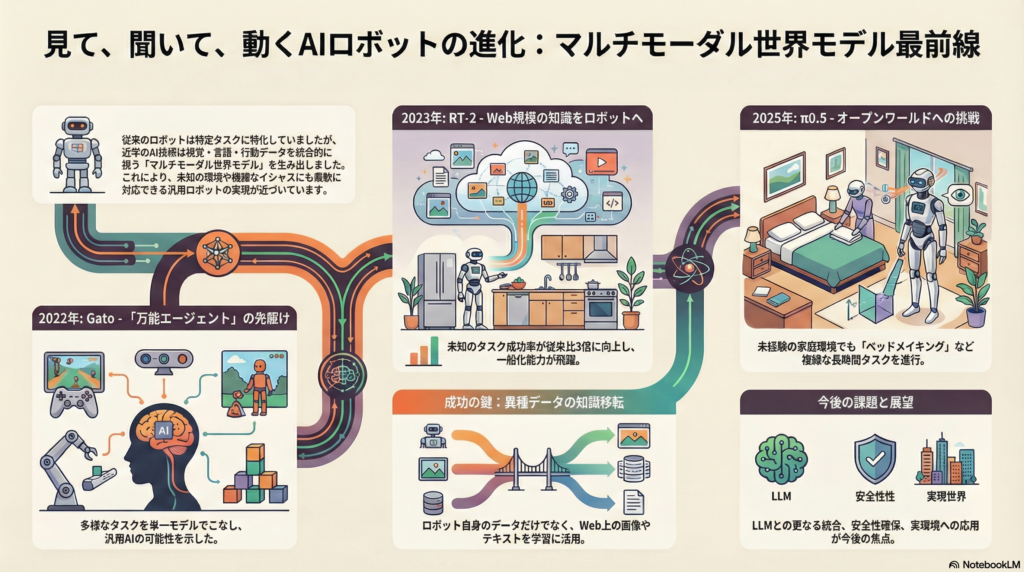
DeepMindが2022年に発表したGatoは、マルチモーダル・マルチタスク学習の先駆的モデルです。約12億パラメータのTransformerベースアーキテクチャを採用し、画像観察、テキスト、行動シーケンスなど多様なデータを統一的なトークン列として表現します。
この設計により、単一の重みセットでゲームプレイ、ロボット操作、画像キャプション生成、対話など幅広いタスクを実現しました。視覚・言語・行動を同一のトークン列で扱うことで、文脈に応じて適切な出力形式を自律的に選択できる点が特徴です。専門特化モデルの性能には及ばないものの、多様な環境への適応力を示した重要な事例と言えます。
SayCan:言語モデルとロボットスキルの統合
Googleが2022年に提案したSayCanは、大規模言語モデル(LLM)をロボット制御に活用するモジュール型アプローチです。ユーザからの自然言語命令に対し、LLMが高水準のプランを生成し、各ステップについてロボットのスキル実行確率を評価します。
「できる(Can)」スキルと「言われた(Say)」タスクを統合することで、実行可能性とタスク適合性の両立を図ります。実環境での101命令に対してプラン正解率84%、実行成功率74%を達成し、長い指示文の解釈や未学習スキルの組み合わせ実行への一般化を実証しました。
VIMA:マルチモーダルプロンプトによる操作学習
ICML 2023で発表されたVIMAは、マルチモーダルプロンプトを活用したロボット操作手法です。テキスト指示、画像、動画による一例デモなど視覚と言語を交えたプロンプトでタスクを指定し、単一モデルで多様な操作をこなすことを目指します。
Transformerデコーダを採用し、事前学習T5モデルで符号化したマルチモーダルプロンプトをクロスアテンション機構で条件付けして、ロボット行動を逐次生成します。ゼロショット条件下で既存手法よりタスク成功率が最大2.9倍向上し、10分の1のデータ量でも他手法を上回る高いデータ効率を示しました。
PaLM-E:言語モデルへの身体性付与
Googleが2023年に発表したPaLM-Eは、5400億パラメータ規模の言語モデルPaLMに視覚・ロボットセンサ入力用エンコーダを組み込んだモデルです。画像やロボット状態を「単語トークン」と同じベクトル空間にマッピングして直接入力する設計により、生のロボット観測データをLLMに取り込む統合学習を実現しました。
ロボット操作タスクと視覚質問応答などの一般視覚言語タスクを一括学習することで、ロボット制御の高い性能を維持しつつ、OK-VQAなど視覚言語ベンチマークで追加微調整なしに高精度を達成しています。言語モデルの知識と推論力を活かしながら感覚入力に反応できるアーキテクチャの有効性を示しました。
RT-2:インターネット規模の知識をロボット制御に転移
DeepMindとGoogleが2023年に共同開発したRT-2(Robotic Transformer 2)は、Vision-Language-Actionモデルの代表例です。大規模視覚言語モデル(PaLM-E 12BやPaLI-X 55B)をロボットの操作データとウェブ画像・テキストタスクで共同微調整し、ロボットの観測から行動までをエンドツーエンドで生成します。
ロボットの行動をテキストトークン列に符号化し、視覚・テキストと同じフォーマットでモデルに学習させた点がユニークです。この設計により、訓練データに含まれない未知のオブジェクトや命令への対応力が飛躍的に向上しました。
チェイン・オブ・ソート(思考の連鎖)プロンプトを活用することで、「即席のハンマーに使えそうな物を選ぶ」や「眠気覚ましに適した飲み物を渡す」といったマルチステップのセマンティック推論も実現しています。従来のRT-1と比較して、新規一般化タスクでの成功率が約3倍向上し、人間による総合評価でも2倍以上の性能差を示しました。
GenRL:世界モデル型強化学習フレームワーク
NeurIPS 2024で発表されたGenRLは、マルチモーダル基盤モデルによる世界モデル型強化学習フレームワークです。事前学習済みの動画・言語モデルと強化学習用の生成的世界モデルを接続・整合させることで、言語アノテーションなしでマルチモーダル基盤世界モデル(MFWM)を学習します。
このMFWMにより、エージェントは画像やテキストのプロンプトでタスク指定を受け、環境の潜在動的表現にグラウンドして、モデル内シミュレーション上で行動を学習できます。視覚または言語の入力から複数タスクへの同時汎化が可能になり、追加の実データなしで新規タスクを達成するデータフリー一般化能力も確認されました。
π0.5:オープンワールド一般化を目指す最新VLAモデル
Physical Intelligenceが2025年にarXivで発表したπ0.5は、オープンワールド一般化を目指した最新の視覚・言語・行動モデルです。移動マニピュレータによる家庭内タスク遂行を想定し、異種のデータソースを組み合わせた共同訓練で学習しています。
400時間相当の家庭内実ロボットデータに加え、他種類ロボットからのデータ、ラボ環境での類似タスクデータ、ロボット観察に基づく高レベルタスク予測データ、人間による言語指示データ、さらにはWeb上の画像キャプション・QA・物体検出データまで取り入れた多様なマルチモーダル学習を実施しました。
全体の97%以上が実ロボ以外のデータですが、これら異種知識の移転により、訓練で一度も見ていない新しい家庭環境でも「タオルを掛ける」「ベッドメイキング」「台所を10~15分かけて一式片付ける」といった長い手順の巧妙な操作タスクを高い成功率で実行できることを示しました。
階層型アーキテクチャを採用し、多様データで大まかなマルチタスクポリシーを事前訓練した後、高レベルの「サブタスク予測」モジュールと低レベルの連続行動モジュールに分けて微調整しています。推論時には各ステップで次に遂行すべきサブタスクを予測し、それに沿って低レベル動作を実行する構造になっており、長いタスクの論理構成を把握しつつ実行制御も精密に行うことが可能です。
一般化能力を評価するベンチマークと手法
VIMA-Bench:マルチモーダルプロンプト操作の評価基盤
VIMA-Benchは、マルチモーダルプロンプトによるロボット操作の大規模シミュレーションベンチマークです。テーブル上の物体操作17タスクについて、言語指示と例示画像・動画からなるプロンプトを生成し、数千種類のバリエーションを自動生成できます。
各タスクに専門の模倣学習ポリシーの専門家デモ(計60万軌跡以上)を用意し、モデルのマルチタスク学習と系統的な一般化評価を行います。評価プロトコルは4段階あり、訓練で見た組み合わせから構成的に新しい指示・物体配置・属性などへモデルがゼロショット適応できるかを細かく測定します。
LIBERO:生涯学習志向のロボット操作ベンチマーク
NeurIPS 2023で提案されたLIBEROは、Vision-Language-Actionモデルの汎用性を測るための生涯学習志向のベンチマークです。日常動作を模した130種類の言語条件付きマニピュレーションタスクを4つのカテゴリ(空間概念、物体概念、目標命令、長尺手順)に分類し、MuJoCoシミュレータ上で手動収集した高品質なデモを提供します。
各タスクは言語命令、オブジェクト集合、環境レイアウト、初期状態、目標状態の形式で定義され、異なるタスク間で知識を転移できるか(前向き転移FWT)、新タスク習得時に旧タスク性能が落ちないか(負のバックワード転移NBT)など生涯学習の観点で一般化指標を測定します。
LIBEROの評価では、クリーンな条件下では高い成功率を出せるモデルも、少しセンサー入力にノイズが乗るだけで脆弱になるなど、ロバスト性や組合せ一般化に課題が浮き彫りになりました。
実環境評価と多角的な一般化指標
実ロボットを用いた新規環境でのタスク成功率測定も一般化評価の重要な指標です。π0.5の研究では、訓練で見ていない家庭での大規模掃除タスク成功率を詳細に報告し、タスク内訳ごとの成否やデモ動画による質的評価も行われています。
RT-2では、未知オブジェクト操作や新規命令文理解といった軸で性能比較することで一般化能力を示しています。最近では、VLA-FEBというベンチマークで、モデルが視覚・言語・行動各モダリティをどれだけ効率よく統合・活用しているかを新たなメトリクスで定量化する試みも登場しています。
総じて、未知のタスク・環境での成功率、タスク間の知識転移度合い、ノイズや摂動への頑健性、人手による質的評価などを組み合わせ、多角的に一般化能力を測る傾向にあります。
今後の展望と未解決課題
モダリティ融合戦略の高度化
最新のレビュー研究によると、階層型・後段融合アーキテクチャ(マルチモーダル表現を段階的・遅延的に統合する設計)が操作成功率と一般化性能で優れた結果を示しています。一方で、現在主流のオートレグレッシブ(逐次デコーダ)出力よりも、拡散モデルを用いたデコーダの方がモーダル間の頑健なクロスドメイン転移に優れる兆候も示されています。
今後、よりリッチなマルチモーダル表現の統合方法(オブジェクト指向のスロット表現や関係表現、拡散モデル活用など)を探求しつつ、モデルの一般化能力向上が期待されます。
大規模データとシミュレーションの課題
ロボティクス分野では依然として多様で大規模な訓練データの不足がボトルネックです。今後はシミュレータを用いたタスク自動生成や、人間の動画からスキル抽出、Webデータ活用などでデータ多様性を高める方向が模索されています。
ただし、シミュレータと実環境のギャップ(リアルギャップ)も依然大きく、現行のシミュレータはモダリティ同期や現実再現性に限界があります。シミュレーション内で言語・視覚・物理を高忠実度で統合した新しいベンチマーク環境の開発や、シミュレーションで学習した世界モデルを実ロボにアダプトするドメイン適応手法の進展が重要となるでしょう。
LLMとの統合とエージェンティックAI
巨大言語モデルをロボットのプランナーや知識ベースとして組み込むアプローチは今後さらに発展すると考えられます。LLMを高位のプランナーとして用い、VLAスキルをツール群として検証・再計画しながらフィードバックループで制御する「エージェンティックVLA」パラダイムが提案されています。
言語モデルの論理推論力とロボットのサブスキルを結びつけることで、環境変化に自己適応できるロボット制御を目指すものです。将来的には、計画と実行を統合したモジュール構成のロボットが、人間の高度な指示に対しても自己評価・試行錯誤しながら対応できるようになる可能性があります。ただし、長尺推論時の安定性、リアルタイム応答性、安全性など解決すべき課題も多く残されています。
リソース効率と安全性の両立
大規模モデルを実ロボットに搭載して動作させるには計算資源やエネルギー効率の最適化も不可欠です。推論高速化やモデル圧縮技術、オンボード計算との折り合いをつける工夫が求められます。
また、マルチモーダルモデルがブラックボックス化する中で、判断根拠の説明性(XAI)やミス時のフェイルセーフも重要課題です。特にロボットは物理的実体を伴うため、誤認識や誤動作による安全リスクに備え、センサフィードバックによる自己検知・停止や、人間の介入を受け入れるインタフェース設計も検討されています。
高度な一般化能力と安全で解釈可能な動作を両立するマルチモーダル世界モデルの設計指針が、今後の研究で模索されるでしょう。
まとめ:マルチモーダル統合がもたらすロボティクスの未来
視覚・言語・行動を統合した世界モデルの研究は急速に進展しており、多様なモダリティ融合による知識移転がロボットの一般化能力を飛躍的に向上させつつあります。Gatoからπ0.5に至るまでの研究は、単一モデルで多様なタスクをこなす汎用ロボットの実現可能性を示しています。
一方で、評価基盤の整備、データ効率、安全性、解釈性など未解決の課題も残されています。今後も基盤モデルやプランニング手法の進歩と相まって、未知の環境やタスクにも柔軟に適応できる汎用ロボットの実現に向けた研究がさらに深化していくと期待されます。
コメント