はじめに
AIによる対話エージェントが日常生活に浸透する中、単に応答するだけでなく「自分の推論を見直す」能力が注目を集めています。この能力こそが「メタ認知」です。人間が自分の考えを客観的に振り返るように、AIエージェントも「自分の推論は正しいか?情報は十分か?自信度はどの程度か?」と内省することで、より信頼できる対話システムが実現されつつあります。本記事では、対話エージェントにおけるメタ認知的自己モニタリングと制御の研究について、実装方法から評価手法、具体的な応用事例まで詳しく解説します。
メタ認知とは何か
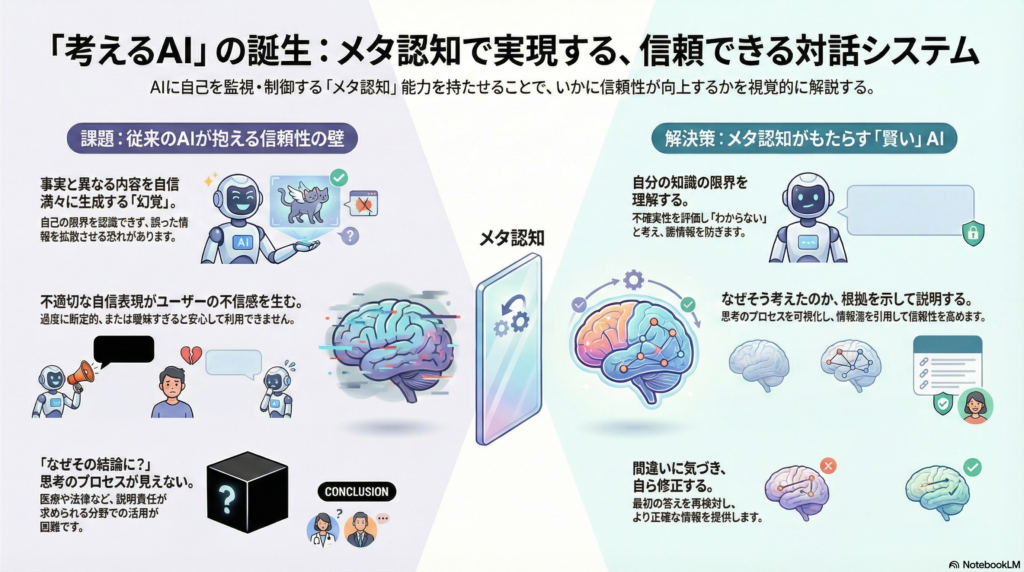
AIにおけるメタ認知とは、システムが自らの思考過程をモニターし評価・制御する能力を指します。通常の推論がタスクを解くこと自体に集中するのに対し、メタ認知は「タスクの解き方を管理する」層として機能します。
具体的には、不確実性の監視、理由付け、自己修正などを通じてエージェントの賢明で安全な動作を促します。例えば、対話エージェントが質問に答える際、単に回答を生成するだけでなく「この回答はどの程度確実か」「追加情報が必要ではないか」「別の解釈の可能性はないか」といったメタレベルの判断を行うのです。
近年、このメタ認知層を取り入れることがAIエージェントをより信頼できる存在にする鍵として注目されています。特に医療、法律、教育など、誤った情報が深刻な影響を及ぼす分野では、AIが自己の限界を認識し適切に表現する能力が不可欠となっています。
対話エージェントにメタ認知が必要な理由
対話エージェントにメタ認知が求められる背景には、いくつかの重要な課題があります。
第一に、誤情報のリスク低減です。大規模言語モデルは膨大な知識を持つ一方で、時に事実と異なる内容を自信満々に生成する「幻覚」現象が知られています。メタ認知機能により、エージェントが自身の不確実性を認識し「分からない」と答えられることで、誤った情報の拡散を防げる可能性があります。
第二に、ユーザとの信頼関係構築です。人間同士の対話でも、相手が自信の度合いを適切に表現することで信頼が生まれます。対話エージェントが過度に断定的でも控えめすぎでもなく、適切な不確実性を表現することで、ユーザは安心して情報を受け取れます。
第三に、透明性と説明可能性の向上です。AIの推論プロセスがブラックボックスであることへの懸念が高まる中、エージェントが「なぜその回答に至ったか」を説明できることは、医療診断支援や法的判断支援など重要な意思決定の場面で特に重要となります。
メタ認知機能の実装方法
不確実性の自己評価
エージェント自身が回答の確実性を見積もり、必要に応じて曖昧さを表現する機能です。具体的には、モデルの出力に確信度スコアを付与したり、回答を拒否・保留する判断を組み込みます。
IBM Watsonはクイズ番組Jeopardy!で、解答の信頼度を算出し信頼度が十分高い場合にのみ回答する戦略を採りました。各候補回答に対して根拠の強さをスコアリングし、所定の閾値を超えた場合にのみ解答する仕組みにより、誤答による減点を極力避けつつ正答率を最大化することに成功しています。
大規模言語モデルでも、出力確率のキャリブレーション技術や追加の評価モジュールで自信度を推定する研究が進んでいます。医療QA分野の研究では、架空の臓器に関する質問など答えが存在しない問いでモデルが「分からない」を選べるかを試験した結果、多くのモデルが自信過剰に誤答する中、GPT-4など一部は適切に自信度を下げる振る舞いを示したことが報告されています。
根拠付き応答
回答の根拠を明示することで、自身の思考を裏付けるアプローチです。対話エージェントが外部知識ベースや検索エンジンを利用し、証拠となる情報を取得・引用して回答を生成します。
OpenAIのWebGPTでは、人間と同様にウェブ検索で資料を集め、回答中に出典を明示する訓練を行いました。その結果、回答の事実性とユーザ評価が向上し、人間回答より好まれるケースも報告されています。
Facebook AIのWizard of Wikipediaでは、会話ごとにWikipediaから知識を検索して発話を生成することで、知識に基づく具体的な対話を可能にしました。このような根拠付き応答により、エージェントの発話は裏付けが取れるためユーザの信頼性も高まり、誤情報や幻覚の抑制に寄与します。
思考プロセスの可視化
エージェントが内部で行っている推論ステップを外部から追跡・検証できる形で表現する技術です。
Chain-of-Thought(思考の連鎖)プロンプトでは、モデルが問題を解く際に中間推論文を生成します。さらにReActフレームワークでは、モデルに「思考(推論)」と「行動(ツール使用)」のトレースをインラインで出力させることで、逐次的な思考過程を確認できます。
例えば質問応答であれば、モデルはまず「考えたこと」を文章で出力し、その後「検索」などの行動を取り、得た情報を踏まえて回答を導くといったプロセスです。この手法によりモデルの推論経路がログとして残り、開発者や場合によってはユーザがどのように結論に至ったかを検証・説明できるようになります。
Meta-R1フレームワークでは、従来のLLMにメタレベルのモジュールを追加し、問題ごとに推論計画を立て、推論中に自己監視・制御し、適切なところで推論を打ち切る判断を行う三段階を実装しています。これによりモデルの冗長な思考や逸脱を防ぎ、必要十分な推論経路を辿れることが示されました。
自己反省・自己修正
エージェントが一度得た解答や行動方針を振り返り、誤りに気付いて修正する能力です。
Reflexion手法では、言語エージェントに自ら前回の試行を振り返り「どこで失敗したか」「次にどう改善すべきか」といったテキストによる自己フィードバックを生成させ、次の試行に活かすことでタスク成功率を高めました。
またLLMを用いた自己検証では、モデルが一度出力した回答を別の推論チェーンで検証し、矛盾やエラーを検出するアプローチも模索されています。このように自己批判的に吟味し戦略を調整するメカニズムを組み込むことで、初回で間違った回答をそのまま提示するのではなく、一呼吸おいて熟考・訂正した上で応答する対話エージェントが実現されつつあります。
メタ認知機能の評価方法
ユーザ評価
ユーザとの対話実験を通じて、メタ認知機能が信頼感・満足度・理解度に与える影響を測定します。
ある研究では、LLMが回答時に自信の度合いを言葉で表現するよう操作し、高・中・低の不確実性表現がユーザに与える効果を比較しています。その結果、自信満々でもなく控えめすぎもしない「適度な不確実性表現」を含む回答が最もユーザの信頼・満足・タスク成果を高めたことが報告されました。
過度に断定的な回答は誤りだった場合に信用を損ない、逆に不確実性を強調しすぎるとユーザが戸惑うため、中程度の自己評価がユーザとの適切な信頼関係を築くことに寄与したと分析されています。
他にも、回答に根拠(出典)を添えた対話システムが利用者に選好されることをアンケートで示した研究や、対話エージェントが不確実な時に答えを保留する挙動についてユーザがより誠実で好ましいと感じるか調べた実験などが報告されています。
定量的評価指標
メタ認知機能の有無で客観的な性能指標やエラー率がどう変化するかも評価されます。
Meta-R1では数学推論ベンチマークでメタ認知拡張したモデルを評価し、最先端手法比で最大27%の正答率向上や推論に要するトークン数の大幅削減といった改善を示しました。これはメタレベルで不要な思考を省き、誤りやすいステップを自己修正できた効果と解釈できます。
その他、キャリブレーション指標(モデルの予測確率と実際の正解率の一致度)を用いて自己不確実性評価の精度を測ったり、誤答時の自己検出率(モデルが誤答の際に「自信がない」と判断できた割合)などを計測する手法もあります。
医療QA向けに拡張したMetaMedQAベンチマークでは、各モデルに「該当なし」選択肢を与え、正答が無い場合にそれを選べるかを見る指標が導入されました。結果、多くのモデルが「無回答」をほぼ選ばず誤答してしまう中、GPT-4は高い精度で「None of the above」を選択でき、自分の知識の限界をある程度認識できていることが示唆されています。
対話型エージェントへの応用事例
メタ認知機能を備えた対話エージェントは、幅広い領域で実用化・実験が進んでいます。
知識質問応答システムでは、IBM Watsonがその高精度QA能力に加えて自信度に基づく応答制御というメタ認知戦略で注目されました。答えが正しいと十分確信できた場合にのみ解答し、確信が持てない場合は回答を見送るという振る舞いを実装することで、人間チャンピオンに勝利しています。
知識対話エージェントでは、Wizard of WikipediaやBlenderBotなどのシステムが、ユーザ発話に応じて外部知識を検索し、その内容を対話に反映させることで、雑談であっても事実に基づいた発言ができるようになりました。Facebook AIのBlenderBot 2.0では長期記憶とインターネット検索機能を持たせ、曖昧な質問には検索して根拠を確認してから回答する仕組みを採用し、知識に裏付けされた応答でユーザ満足度が向上しました。
教育・チュータリング対話システムでは、学習者向け対話エージェントがエージェント自身のメタ認知に加え、ユーザの理解度・確信度を推定して対話戦略を変えるケースも見られます。EUプロジェクトのMetalogueでは、ディベート指導対話においてエージェントがユーザの表情や発話から自信のなさを検知し、対話方針を調整するメタ認知モジュールを組み込んでいました。
自律エージェント・シミュレーションでは、Generative Agentsの研究で、仮想空間上の多数のエージェントに長期記憶・計画・反省能力を持たせ、人間らしい挙動を自主的に生み出す試みがなされました。各エージェントは一日の行動後にその日の出来事を内省的に要約し、自分の記憶に統合する自己反省プロセスにより、一貫した人格やストーリー展開が維持されました。
まとめ
対話エージェントにおけるメタ認知的自己モニタリングと制御は、AI対話システムの信頼性と有用性を大きく向上させる可能性を持っています。不確実性の自己評価、根拠付き応答、思考プロセスの可視化、自己反省・自己修正といった機能により、エージェントは自己を客観視し、より賢明で安全な対話を実現できます。
ユーザ評価と定量的評価の両面から、メタ認知機能がユーザ満足度や信頼性指標の向上、タスク達成度や誤答抑制の改善に寄与することが明らかになっています。IBM WatsonからWizard of Wikipedia、Meta-R1、Generative Agentsまで、多様な研究プロジェクトがこの領域の発展に貢献してきました。
今後、メタ認知的AIの研究はさらに進展し、医療、教育、ビジネスなど様々な分野で「自己を考えられるAI」が実用化されていくことが期待されます。対話エージェントが単なる応答システムから、自己の限界を認識し説明責任を果たせる信頼できるパートナーへと進化する未来が、そう遠くない将来に実現するかもしれません。
コメント