導入:時系列データにおける「時間解像度」の重要性
現代の時系列解析において、単一の時間軸で全てのパターンを捉えることには限界があります。時系列データ には、秒単位の局所的な変動(高周波)から、月・年単位の季節性やトレンド(低周波)まで、異なる時間スケールが共存しているからです。
本記事では、これらを同一モデル内で効率的に扱うための**「階層的Attention機構」**の設計指針を解説します。具体的には、既存の成功パターンを5系統に分類し 、それらを統合した汎用ブロック「HMA(Hierarchical Multi-resolution Attention)」の具体的な実装構成を提案します 。
1. マルチスケール時間表現の定義と動機
マルチスケール時間表現とは、同一モデル内で「細粒度(fine)」と「粗粒度(coarse)」の表現を併存させる設計を指します。
- 細粒度(fine): 短い窓やパッチを用いて、高周波な局所変動を捉えます。
- 粗粒度(coarse): 長い窓や大きいパッチを用いて、低周波な季節性やトレンドを捉えます。
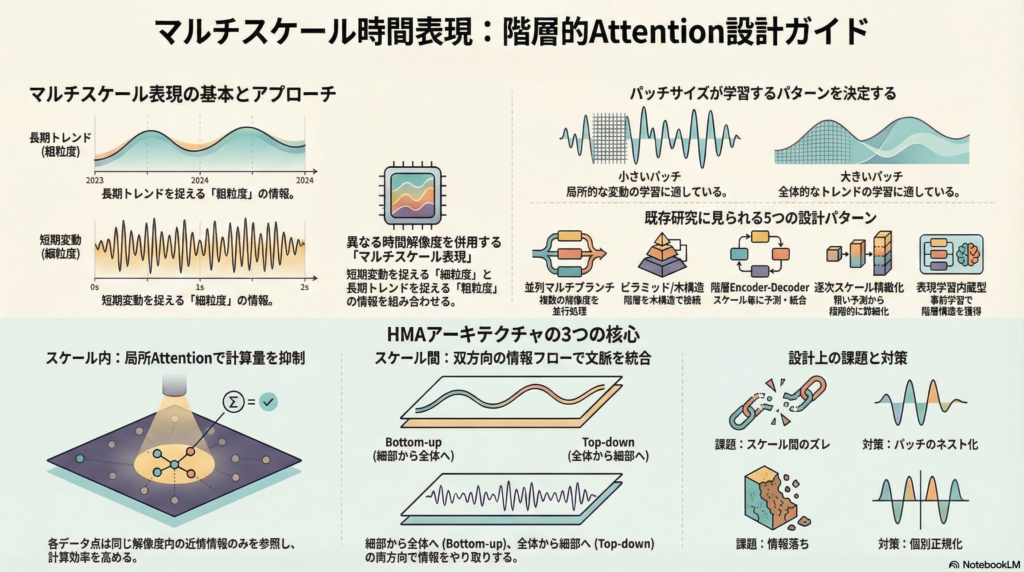
この設計の背景には、**「パッチサイズが学習しやすい周波数帯を支配する」**というMTST等の研究における動機づけがあります。パッチ化は、局所セマンティクスの保持だけでなく、計算量の削減や、より長い履歴へのアテンションの拡張を可能にします。
2. 既存研究に見る5つの設計パターン
「階層的Attention」を実現するための既存手法は、主に以下の5つの系統に整理されます 9。
| パターン | 特徴 | 既存研究の例 |
| (A) 並列マルチブランチ | 各層で複数のパッチサイズの枝を並列に走らせ、融合する 。 | MTST |
| (B) ピラミッド/木構造 | スケール間を木構造、スケール内を近傍接続で構成する 。 | Pyraformer |
| (C) 階層Encoder-Decoder | スケールごとに縮約・予測を行い、最終的に足し合わせる 。 | Crossformer |
| (D) 逐次スケール精緻化 | 粗い予測を段階的に細かいスケールで修正していく 。 | Scaleformer |
| (E) 表現学習内蔵型 | 事前学習で階層性を獲得し、fine-tuneでスケール間Attentionを解放する 。 | HiMTM |
3. 提案アーキテクチャ:階層的マルチ解像度Attention(HMA)
ここでは、異なる時間解像度を持つ「階層的Attention」を実装するための具体的な設計案「HMA」を詳述します 。
3.1 マルチ解像度トークン化
実装上、スケール $s=0, \dots, S$ におけるパッチ長 $p_s$ を幾何級数的に設定するのが効率的です 。
トークン生成手法としては、隣接パッチをマージして上位階層を作る「階層merge型(HiMTM型)」や、親子関係を明示する「木構造型(Pyraformer型)」が、階層性を数理的に定義しやすいため推奨されます 。
3.2 スケール内Attention(Intra-scale)
フルSelf-Attentionは系列長に対して $O(N^2)$ の計算量を要するため、各スケール内では**「局所Attention」を採用することが現実的です 。
各トークンが同一スケール内の近傍 $w$ のみに注目することで、計算量を 抑えることが可能です 。この際、絶対的な位置表現よりも、スケール間での整合性が高い相対位置表現(RPE)**の採用が望ましいとされています 。
3.3 スケール間Attention(Inter-scale / Cross-scale)
これが階層的Attentionの核心であり、情報の流れには2つの方向性があります 。
- Bottom-up (fine → coarse): 粗粒度トークンをQueryとし、対応する時間範囲の細粒度トークンから情報を集約します 。
- Top-down (coarse → fine): 細粒度トークンが粗粒度の長期文脈を参照し、局所的な判断を安定化させます 。
近年のトレンドは、単純な加算や連結(concat)ではなく、Cross-scale Attention自体を「融合」の仕組みとして定義する方向へシフトしています 。
4. 設計上の落とし穴と回避策
マルチスケール設計には、特有の課題が存在します 。
- スケール整合性(Alignment): 粗いパッチと細かいパッチの対応がズレると、Attentionが不安定になります 。対策として、HiMTMのように細かいパッチを粗いパッチの内部にネストさせる構成が有効です 。
- 情報落ちの防止: coarse化による細部の消失を防ぐため、Top-down AttentionとSkip connectionを併用し、局所密度を維持する必要があります 。
- 分布ずれ(Distribution Shift): スケール間で統計量が変化するため、Scaleformerが提案するように「スケールごとの正規化」を導入することが精度向上への貢献となります 。
5. 理論的裏付け:認知科学的な視点からの正当化
この階層的設計は、単なる工学的な最適化にとどまらず、**「生体の情報処理制約」**とも整合します 。
人間の脳(皮質)には、入力を統合する時間窓が階層的に分布する「Temporal Receptive Windows」が存在するとされています 。また、予測符号化(predictive coding)の観点では、上位階層が長い時間スケールで予測を行い、下位階層を調整するというメカニズムがあり、これは本設計の「Top-down cross-scale attention」の直観に対応します 。
まとめ:次世代の時系列モデルに向けて
本記事では、マルチスケール時間表現を実現するための階層的Attention機構について、その設計指針を整理しました。
- パッチサイズの幾何級数的設定によるマルチ解像度トークン化 。
- 局所AttentionとRPEによる、計算量と位置情報の両立 。
- Bottom-up/Top-downの双方向融合による情報の統合 。
- スケール間正規化による分布ずれへの対処 。
これらの要素を組み合わせることで、複雑な多周期性を持つ時系列データに対しても、堅牢で解釈性の高いモデリングが可能になります。
コメント